大数据-spark HA集群搭建
Posted Angel_jing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据-spark HA集群搭建相关的知识,希望对你有一定的参考价值。
一、安装scala
我们安装的是scala-2.11.8 5台机器全部安装
下载需要的安装包,放到特定的目录下/opt/workspace/并进行解压
1、解压缩
[root@master1 ~]# cd /opt/workspace
[root@master1 workspace]#tar -zxvf scala-2.11.8.tar.gz
2、配置环境变量 /etc/profile文件中添加spark配置
[root@master1 ~]# vi /etc/profile
# Scala Config
export SCALA_HOME=/opt/software/scala-2.11.8
export PATH=$SCALA_HOME/bin:$PATH
[root@master1 ~]# source /etc/profile
3、启动scala
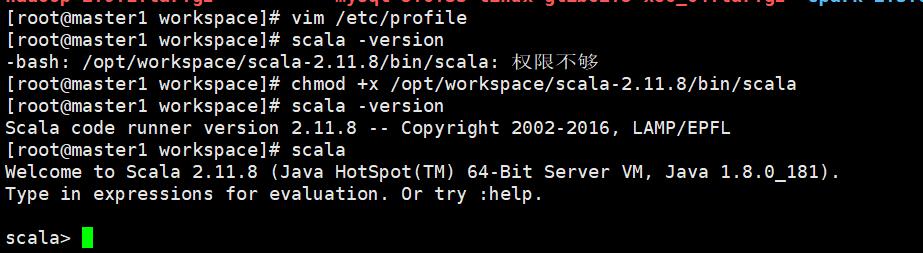
[root@master1 workspace]# vim /etc/profile
[root@master1 workspace]# scala -version
-bash: /opt/workspace/scala-2.11.8/bin/scala: 权限不够
[root@master1 workspace]# chmod +x /opt/workspace/scala-2.11.8/bin/scala
[root@master1 workspace]# scala -version
Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL
[root@master1 workspace]# scala
Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181).
Type in expressions for evaluation. Or try :help.
scala>
二、安装spark
1、下载spark对应版本
因为后期需要安装Hive,并且会运行hive on spark模式,为避免jar冲突,我们去掉了spark中的hive部分。
我们应用的是spark-2.3.0-bin-hadoop2-without-hive.tgz 自己编译的版本
可参考https://blog.csdn.net/sinat_25943197/article/details/81906060进行编译
2、文件解压
[root@master1 workspace]# tar -zxvf spark-2.3.0-bin-hadoop2-without-hive.tgz
3、配置文件 spark-env.sh slaves、/etc/profile
/etc/profile文件中添加
# Spark Config export SPARK_HOME=/opt/workspace/spark-2.3.0-bin-hadoop2-without-hive
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${MAVEN_HOME}/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:${SPARK_HOME}/bin:$SQOOP_HOME/bin:${ZK_HOME}/bin:$PATH
source /etc/profile
spark-env.sh.template重新命名为spark-env.sh文件、配置如下:
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This file is sourced when running various Spark programs.
# Options read when launching programs locally with
# ./bin/run-example or ./bin/spark-submit
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public dns name of the driver program
# Options read by executors and drivers running inside the cluster
# - SPARK_LOCAL_IP, to set the IP address Spark binds to on this node
# - SPARK_PUBLIC_DNS, to set the public DNS name of the driver program
# - SPARK_LOCAL_DIRS, storage directories to use on this node for shuffle and RDD data
# - MESOS_NATIVE_JAVA_LIBRARY, to point to your libmesos.so if you use Mesos
# Options read in YARN client/cluster mode
# - SPARK_CONF_DIR, Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files
# - YARN_CONF_DIR, to point Spark towards YARN configuration files when you use YARN
# - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1).
# - SPARK_EXECUTOR_MEMORY, Memory per Executor (e.g. 1000M, 2G) (Default: 1G)
# - SPARK_DRIVER_MEMORY, Memory for Driver (e.g. 1000M, 2G) (Default: 1G)
#export SPARK_MASTER_IP=master1
export SPARK_SSH_OPTS="-p 61333"
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_INSTANCES=1
export SCALA_HOME=/opt/workspace/scala-2.11.8
export JAVA_HOME=/opt/workspace/jdk1.8
export HADOOP_HOME=/opt/workspace/hadoop-2.9.1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/workspace/spark-2.3.0-bin-hadoop2-without-hive
export SPARK_CONF_DIR=$SPARK_HOME/conf
export SPARK_EXECUTOR_MEMORY=5120M
export SPARK_DIST_CLASSPATH=$(/opt/workspace/hadoop-2.9.1/bin/hadoop classpath)
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master1:2181,master2:2181,slave1:2181,slave2:2181,slave3:2181 -Dspark.deploy.zookeeper.dir=/spark"
# Options for the daemons used in the standalone deploy mode
# - SPARK_MASTER_HOST, to bind the master to a different IP address or hostname
# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master
# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")
# - SPARK_WORKER_CORES, to set the number of cores to use on this machine
# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)
# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker
# - SPARK_WORKER_DIR, to set the working directory of worker processes
# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")
# - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g).
# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")
# - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y")
# - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y")
# - SPARK_DAEMON_CLASSPATH, to set the classpath for all daemons
# - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers
# Generic options for the daemons used in the standalone deploy mode
# - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf)
# - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs)
# - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp)
# - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER)
# - SPARK_NICENESS The scheduling priority for daemons. (Default: 0)
# - SPARK_NO_DAEMONIZE Run the proposed command in the foreground. It will not output a PID file.
# Options for native BLAS, like Intel MKL, OpenBLAS, and so on.
# You might get better performance to enable these options if using native BLAS (see SPARK-21305).
# - MKL_NUM_THREADS=1 Disable multi-threading of Intel MKL
# - OPENBLAS_NUM_THREADS=1 Disable multi-threading of OpenBLAS
slaves.template文件重新命名为slaves、配置如下:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# A Spark Worker will be started on each of the machines listed below.
slave1
slave2
slave3
4、启动spark
[root@master1 workspace]# ./spark-2.3.0-bin-hadoop2-without-hive/sbin/start-all.sh
报错:默认是22端口,进行ssh端口修改

解决:在spark-env.sh中增加端口
export SPARK_SSH_OPTS="-p 61333"
重新启动spark

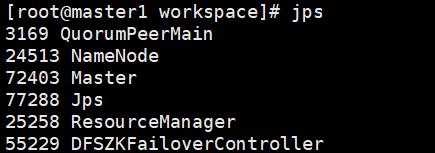
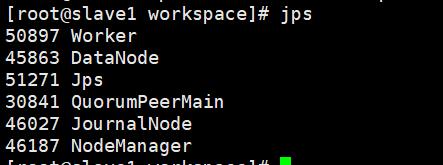
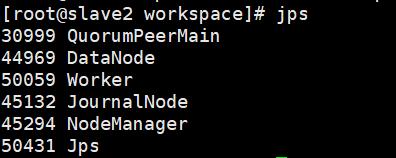
启动成功
5、手动启动备用master
[root@master2 workspace]# ./spark-2.3.0-bin-hadoop2-without-hive/sbin/start-master.sh
参考:https://blog.csdn.net/sinat_25943197/article/details/81906060
以上是关于大数据-spark HA集群搭建的主要内容,如果未能解决你的问题,请参考以下文章