浅谈程序优化
Posted showcase
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈程序优化相关的知识,希望对你有一定的参考价值。
无论什么语言,千万不要在循环里进行数据库的查询。
首先说明一下,这里说的程序优化是指程序效率的优化。一般来说,程序优化主要是以下三个步骤:
算法上的优化是必须首要考虑的,也是最重要的一步。一般我们需要分析算法的时间复杂度,即处理时间与输入数据规模的一个量级关系,一个优秀的算法可以将算法复杂度降低若干量级,那么同样的实现,其平均耗时一般会比其他复杂度高的算法少(这里不代表任意输入都更快)。
比如说排序算法,快速排序的时间复杂度为O(nlogn),而插入排序的时间复杂度为O(n*n),那么在统计意义下,快速排序会比插入排序快,而且随着输入序列长度n的增加,两者耗时相差会越来越大。但是,假如输入数据本身就已经是升序(或降序),那么实际运行下来,快速排序会更慢。
因此,实现同样的功能,优先选择时间复杂度低的算法。比如对图像进行二维可分的高斯卷积,图像尺寸为MxN,卷积核尺寸为PxQ,那么
直接按卷积的定义计算,时间复杂度为O(MNPQ)
如果使用2个一维卷积计算,则时间复杂度为O(MN(P+Q))
使用2个一位卷积+FFT来实现,时间复杂度为O(MNlogMN)
如果采用高斯滤波的递归实现,时间复杂度为O(MN)(参见paper:Recursive implementation of the Gaussian filter,源码在GIMP中有)
很显然,上面4种算法的效率是逐步提高的。一般情况下,自然会选择最后一种来实现。
还有一种情况,算法本身比较复杂,其时间复杂度难以降低,而其效率又不满足要求。这个时候就需要自己好好地理解算法,做些修改了。一种是保持算法效果来提升效率,另一种是舍弃部分效果来换取一定的效率,具体做法得根据实际情况操作。
代码优化一般需要与算法优化同步进行,代码优化主要是涉及到具体的编码技巧。同样的算法与功能,不同的写法也可能让程序效率差异巨大。一般而言,代码优化主要是针对循环结构进行分析处理,目前想到的几条原则是:
a.避免循环内部的乘(除)法以及冗余计算
这一原则是能把运算放在循环外的尽量提出去放在外部,循环内部不必要的乘除法可使用加法来替代等。如下面的例子,灰度图像数据存在BYTE Img[MxN]的一个数组中,对其子块 (R1至R2行,C1到C2列)像素灰度求和,简单粗暴的写法是:


1 int sum = 0;
2 for(int i = R1; i < R2; i++)
3 {
4 for(int j = C1; j < C2; j++)
5 {
6 sum += Image[i * N + j];
7 }
8 }
但另一种写法:
1 int sum = 0;
2 BYTE *pTemp = Image + R1 * N;
3 for(int i = R1; i < R2; i++, pTemp += N)
4 {
5 for(int j = C1; j < C2; j++)
6 {
7 sum += pTemp[j];
8 }
9 }
可以分析一下两种写法的运算次数,假设R=R2-R1,C=C2-C1,前面一种写法i++执行了R次,j++和sum+=...这句执行了RC次,则总执行次数为3RC+R次加法,RC次乘法;同 样地可以分析后面一种写法执行了2RC+2R+1次加法,1次乘法。性能孰好孰坏显然可知。
b.避免循环内部有过多依赖和跳转,使cpu能流水起来
关于CPU流水线技术可google/baidu,循环结构内部计算或逻辑过于复杂,将导致cpu不能流水,那这个循环就相当于拆成了n段重复代码的效率。
另外ii值是衡量循环结构的一个重要指标,ii值是指执行完1次循环所需的指令数,ii值越小,程序执行耗时越短。下图是关于cpu流水的简单示意图:
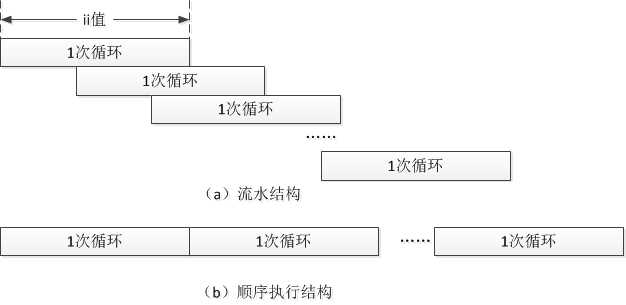
简单而不严谨地说,cpu流水技术可以使得循环在一定程度上并行,即上次循环未完成时即可处理本次循环,这样总耗时自然也会降低。
先看下面一段代码:
 View Code
View Code这段代码实现的功能很简单,对数组a的不同元素累加一个不同的值,但是在循环内部有3个分支需要每次判断,效率太低,有可能不能流水;可以改写为3个循环,这样循环内部就不 用进行判断,这样虽然代码量增多了,但当数组规模很大(N很大)时,其效率能有相当的优势。改写的代码为:
View Code关于循环内部的依赖,见如下一段程序:
View Code其中f,g,h都是一个函数,可以看到这段代码中x依赖于a[i],y依赖于x,z依赖于xy,每一步计算都需要等前面的都计算完成才能进行,这样对cpu的流水结构也是相当不利的,尽 量避免此类写法。另外C语言中的restrict关键字可以修饰指针变量,即告诉编译器该指针指向的内存只有其自己会修改,这样编译器优化时就可以无所顾忌,但目前VC的编译器似乎不支 持该关键字,而在DSP上,当初使用restrict后,某些循环的效率可提升90%。
c.定点化
定点化的思想是将浮点运算转换为整型运算,目前在PC上我个人感觉差别还不算大,但在很多性能一般的DSP上,其作用也不可小觑。定点化的做法是将数据乘上一个很大的数后,将 所有运算转换为整数计算。例如某个乘法我只关心小数点后3位,那把数据都乘上10000后,进行整型运算的结果也就满足所需的精度了。
d.以空间换时间
空间换时间最经典的就是查表法了,某些计算相当耗时,但其自变量的值域是比较有限的,这样的情况可以预先计算好每个自变量对应的函数值,存在一个表格中,每次根据自变量的 值去索引对应的函数值即可。如下例:
View Code后面的查表法需要额外耗一个数组double aSinTable[360]的空间,但其运行效率却快了很多很多。
e.预分配内存
预分配内存主要是针对需要循环处理数据的情况的。比如视频处理,每帧图像的处理都需要一定的缓存,如果每帧申请释放,则势必会降低算法效率,如下所示:
View CodeView Code前一段代码在每帧处理都malloc和free,而后一段代码则是有上层传入缓存,这样内部就不需每次申请和释放了。当然上面只是一个简单说明,实际情况会比这复杂得多,但整体思想 是一致的。
对于经过前面算法和代码优化的程序,一般其效率已经比较不错了。对于某些特殊要求,还需要进一步降低程序耗时,那么指令优化就该上场了。指令优化一般是使用特定的指令集,可快速实现某些运算,同时指令优化的另一个核心思想是打包运算。目前PC上intel指令集有MMX,SSE和SSE2/3/4等,DSP则需要跟具体的型号相关,不同型号支持不同的指令集。intel指令集需要intel编译器才能编译,安装icc后,其中有帮助文档,有所有指令的详细说明。
例如MMX里的指令 __m64 _mm_add_pi8(__m64 m1, __m64 m2),是将m1和m2中8个8bit的数对应相加,结果就存在返回值对应的比特段中。假设2个N数组相加,一般需要执行N个加法指令,但使用上述指令只需执行N/8个指令,因为其1个指令能处理8个数据。
实现求2个BYTE数组的均值,即z[i]=(x[i]+y[i])/2,直接求均值和使用MMX指令实现2种方法如下程序所示:
View Code使用指令优化需要注意的问题有:
a.关于值域,比如2个8bit数相加,其值可能会溢出;若能保证其不溢出,则可使用一次处理8个数据,否则,必须降低性能,使用其他指令一次处理4个数据了;
b.剩余数据,使用打包处理的数据一般都是4、8或16的整数倍,若待处理数据长度不是其单次处理数据个数的整数倍,剩余数据需单独处理;
补充——如何定位程序热点
程序热点是指程序中最耗时的部分,一般程序优化工作都是优先去优化热点部分,那么如何来定位程序热点呢?
一般而言,主要有2种方法,一种是通过观察与分析,通过分析算法,自然能知道程序热点;另一方面,观察代码结构,一般具有最大循环的地方就是热点,这也是前面那些优化手段都针对循环结构的原因。
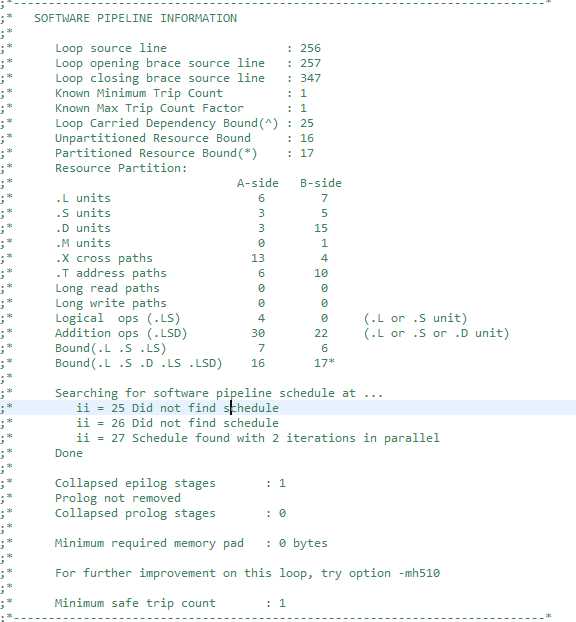
另一种方法就是利用工具来找程序热点。x86下可以使用vtune来定位热点,DSP下可使用ccs的profile功能定位出耗时的函数,更近一步地,通过查看编译保留的asm文件,可具体分析每个循环结构情况,了解到该循环是否能流水,循环ii值,以及制约循环ii值是由于变量的依赖还是运算量等详细信息,从而进行有针对性的优化。由于Vtune刚给卸掉,没法截图;下图是CCS编译生成的一个asm文件中一个循环的截图:
最后提一点,某些代码使用Intel编译器编译可以比vc编译器编译出的程序快很多,我遇到过最快的可相差10倍。对于gcc编译后的效率,目前还没测试过。
原文:https://www.cnblogs.com/jcchen1987/p/4362879.html
以上是关于浅谈程序优化的主要内容,如果未能解决你的问题,请参考以下文章
JavaScript性能优化2——浅谈JavaScriptV8引擎工作流程