自建elk+filebeat+grafana日志收集平台
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自建elk+filebeat+grafana日志收集平台相关的知识,希望对你有一定的参考价值。
欢迎关注个人公众号“没有故事的陈师傅”
搭建这个平台的初衷只是为了我和我的两个小伙伴来更好的学习es以及周边组件,欲善其事,必利其器,只是单纯的去学习理论知识是不够的,理论与操作相结合,才能学的更扎实。
环境配置:
使用自己的两台1v2g阿里云主机以及好友颖枞的一台1v2gvps,共计三台主机
环境架构如下:
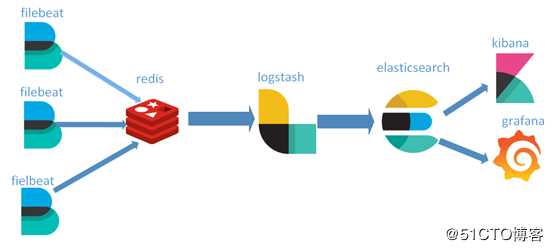
三台主机的环境分别如下:
node1:elasticsearch6.4+filebeat
node2:kibana6.4+grafana+filebeat
node3:logstash+nginx+filebeat+Redis
由于es很消耗内存,所以我只把es单独运行在一个主机上,并设置主分片为1,副本分片为0,每周定时删除上周的索引数据
日志采集端配置
安装Redis
redis服务器是logstash官方推荐的broker(代理人)选择,broker角色也就意味着会同时存在输入和输出两个插件,产生数据的被称作生产者,而消费数据的被称作消费者。
redis消息队列作用说明:
1、防止Logstash和ES无法正常通信,从而丢失日志。
2、防止日志量过大导致ES无法承受大量写操作从而丢失日志。
3、应用程序(php,java)在输出日志时,可以直接输出到消息队列,从而完成日志收集。补充:如果redis使用的消息队列出现扩展瓶颈,可以使用更加强大的kafka,flume来代替。
编译安装Redis
wget http://download.redis.io/releases/redis-4.0.11.tar.gz #下载Redis源码
tar -zxf redis-4.0.11.tar.gz #解压Redis源码
cp -r redis-4.0.11 /usr/local/
mv redis-4.0.11/ redis
cd /usr/local/redis/
cp redis.conf bin/
make PREFIX=/usr/local/redis install #编译安装Redis
echo "export PATH=$PATH:/usr/local/redis/bin" >> /etc/profile 将Redis加入环境变量启动Redis
1.前端模式启动
直接运行bin/redis-server将以前端模式启动,前端模式启动的缺点是ssh命令窗口关闭则redis-server程序结束,不推荐使用此方法redis-server
2.后端模式启动
修改redis.conf配置文件, daemonize yes 以后端模式启动
vim /usr/local/redis/bin/redis.conf
daemonize yes执行如下命令启动redis:
redis-server redis.conf连接redisredis-cli
关闭Redis
强行终止redis进程可能会导致redis持久化数据丢失。正确停止Redis的方式应该是向Redis发送SHUTDOWN命令,命令为:
redis-cli shutdown修改nginx日志格式
nginx日志默认格式为log格式,传输到es中需要经过grok插件进行处理并转换成json格式,这一过程是很消耗logstash资源的,而且传入到es中的字段并不容易分析,所以在收集端先将日志转为json格式,再传入es中去,这样传入的字段也是利于分析的。
编辑nginx配置文件
vim /usr/local/nginx/conf/nginx.conf #修改主配置文件,定义日志格式
log_format json ‘{ "@timestamp": "$time_iso8601", ‘
‘"time": "$time_iso8601", ‘
‘"clientip": "$remote_addr", ‘
‘"remote_user": "$remote_user", ‘
‘"body_bytes_sent": "$body_bytes_sent", ‘
‘"request_time": "$request_time", ‘
‘"status": "$status", ‘
‘"host": "$host", ‘
‘"request": "$request", ‘
‘"request_method": "$request_method", ‘
‘"uri": "$uri", ‘
‘"http_referrer": "$http_referer", ‘
‘"body_bytes_sent":"$body_bytes_sent", ‘
‘"http_x_forwarded_for": "$http_x_forwarded_for", ‘
‘"http_user_agent": "$http_user_agent" ‘
‘}‘;
vim /usr/local/nginx/conf.d/default.conf #修改站点配置文件
access_log /var/log/nginx/io.log json ;
vim /usr/local/nginx/conf.d/doc.conf
access_log /var/log/nginx/doc.access.log json; 重载nginxsystemctl reload nginx
查看日志格式tail -f /var/log/nginx/io.log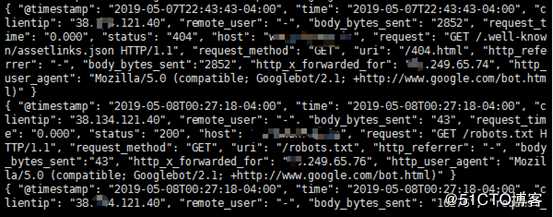
安装并配置filebeat
filebeat是一个轻量级的日志采集器,由于logstash比较消耗资源,不适合在每台主机上部署logstash
使用RPM安装filebeat
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.0.1-x86_64.rpm
rpm -vi filebeat-7.0.1-x86_64.rpm配置filebeat收集nginx日志
配置输入端采集nginx日志,根据字段类型不同输出到Redis不同的key中,每种日志存放在不同的key中,便于后续的处理
vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
- /var/log/nginx/io.log
fields:
type: www_access
fields_under_root: true
- type: log
paths:
- /var/log/nginx/io.error.log
fields:
type: www_error
fields_under_root: true
- type: log
paths:
- /var/log/nginx/doc.access.log
fields:
type: doc_access
fields_under_root: true
setup.template.settings:
index.number_of_shards: 1
output.redis:
hosts: ["127.0.0.1:6379"]
key: "nginx"
keys:
- key: "%{[type]}"
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~重启filebeat
systemctl restart filebeat进入Redis中查看日志信息redis-cli
获取key的长度,key长度增加说明日志已经写入到Redis里了,而且也能看到日志的信息,下图日志信息还是log格式的,因为json格式是后来修改的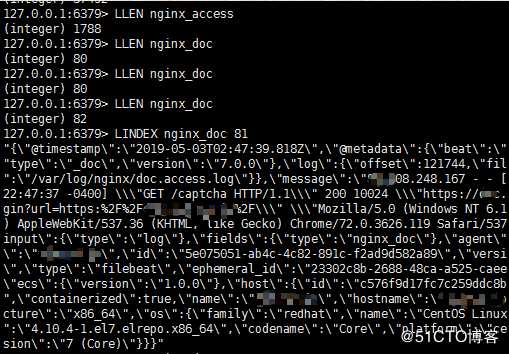
日志处理端配置
安装并配置logstash
1.安装logstash需要依赖Java8的环境,不支持Java9
使用yum install java命令安装
2.下载并安装公共签名密钥
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
3.添加logstash的yum仓库
vim /etc/yum.repos.d/logstash.repo
[logstash-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md4.使用yum安装logstashyum install logstash
编写日志处理配置文件
定义Redis列表或者频道名称,以及Redis的数据类型,定义type以区分不同的日志类型,使用json插件将message字段处理成json格式,并删掉message字段,使用date插件定义新的时间戳,使用geoip插件根据客户端IP来定位客户端大体,默认是使用GeoLite2 city数据库,此数据库官网每两周更新一次,如果对IP地址的准确性要求高,可写一个定时任务,每两周从官网下载新的数据库,mutate插件用于修改字段数据类型,因为"coordinates"子字段不修改会默认为keyword格式,这对于在kibana上创建坐标地图可能会不支持,关于以上插件的详细信息可查看本人以前发的logstash文章。
vim /etc/logstash/conf.d/test.conf
input {
redis {
host => "127.0.0.1"
port => 6379
type => "www_access"
data_type => "list"
key => "www_access"
codec => "json"
}
redis {
host => "127.0.0.1"
port => 6379
type => "nginx_error"
data_type => "list"
key => "www_error"
}
redis {
host => "127.0.0.1"
port => 6379
type => "doc_access"
data_type => "list"
key => "doc_access"
codec => "json"
}
}
filter {
if [type] == "www_access" {
json {
source => "message"
remove_field => "message"
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
fields => ["city_name", "country_code2", "country_name", "region_name","longitude","latitude","ip"]
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
}
mutate {
convert => [ "[geoip][coordinates]","float" ]
}
}
else if [type] =~ "error" {
grok {
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
else {
json {
source => "message"
remove_field => "message"
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ] }
geoip {
source => "clientip"
fields => ["city_name", "country_code2", "country_name", "region_name","longitude","latitude","ip"]
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ] }
mutate {
convert => ["[geoip][coordinates]","float"]
}
}
}
output {
if [type] == "www_access" {
elasticsearch {
hosts => ["60.205.177.168:9200"]
index => "nginx_access-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
else if [type] == "www_error" {
elasticsearch {
hosts => ["60.205.177.168:9200"]
index => "nginx_error-%{+YYYY.MM.dd}"
}
}
else {
elasticsearch {
hosts => ["60.205.177.168:9200"]
index => "nginx_doc-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
}启动logstash
logstash -f /etc/logstash/conf.d/test.conf
再次进入Redis数据库查看,发现日志数据已经被消费掉了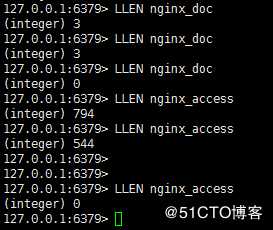
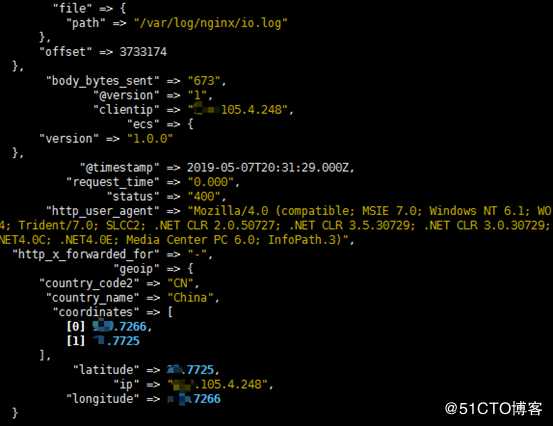
日志存储分析端配置
安装elasticsearch
elasticsearch同样需要Java运行环境
1.下载elasticsearch的tar包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.0.tar.gz2.解压包
tar -xzf elasticsearch-6.4.0.tar.gz3.修改配置文件
[[email protected] elasticsearch-6.4.0]# vim config/elasticsearch.yml
修改内容如下:
cluster.name: my-elk #设置集群的名字
node.name: es1 #集群中的节点名称,同一集群中的节点名称不能重复
path.data: /elasticsearch/elasticsearch-6.4.0/data #设置es集群的数据位置
path.logs: /elasticsearch/elasticsearch-6.4.0/logs/ #设置存放日志的路径
network.host: 192.168.179.134 #绑定本地ip地址
http.port: 9200 #设置开放的端口,默认就是9200端口4.启动elasticsearch
cd elasticsearch-6.4.0/
./bin/elasticsearch如果要将es后台运行,可以在命令后加-d
这里要使用普通用户运行,还要把目录授予普通文件权限chown -R elker.elker /elasticsearch
5.查看启动状态
输入netstat -ntlp |grep 9200查看9200端口是否监听,可以使用curl 192.168.179.134:9200或者在浏览器上输入192.168.179.134:9200进行查看启动后的状态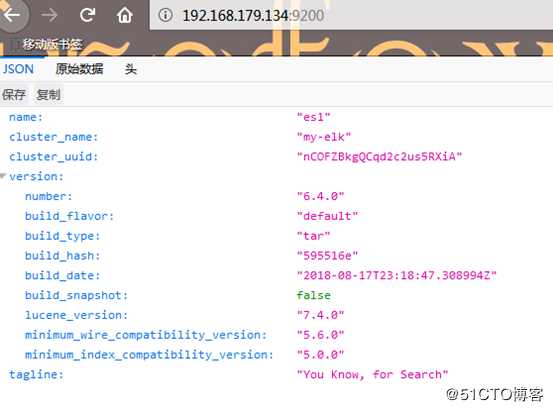
6.启动过程出现的报错
[WARN ][o.e.b.BootstrapChecks ] [PWm-Blt] max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决办法:
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096[WARN ][o.e.b.BootstrapChecks ] [PWm-Blt] max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
vim /etc/sysctl.conf
vm.max_map_count=655360修改完成执行命令:sysctl -p
日志可视化端配置
kibana安装
kibana版本须与es版本一致
1.下载并解压kibana包
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.4.0-linux-x86_64.tar.gz
tar -xzf kibana-6.4.0-linux-x86_64.tar.gz2.修改kibana默认配置
vim kibana-6.4.0-linux-x86_64/config/kibana.yml
server.port: 5601 #kibana默认端口是5601
server.host: "192.168.179.134" #设置绑定的kibana服务的地址
elasticsearch.url: "http://192.168.179.134:9200" #设置elasticsearch服务器的ip地址,不修改的话启动的时候会报[elasticsearch] Unable to revive connection: http://localhost:9200/连接不上elasticsearch的错误3.启动kibana
/kibana-6.4.0-linux-x86_64/bin/kibana
netstat -ntlp |grep 5601 #可以查看5601端口是否启动在浏览器输入192.168.179.134:5601即可访问kibana
4.出现的警告信息
虽然出现警告信息,不过还是可以启动kibana的,本人有点强迫症,不想看到警告信息
警告信息1:[security] Generating a random key for xpack.security.encryptionKey. To prevent sessions from being invalidated on restart, please set xpack.security.encryptionKey in kibana.yml
解决方法:修改配置文件vim config/kibana.yml
在配置文件底部添加
xpack.reporting.encryptionKey: "a_random_string"
警告信息2:[security] Session cookies will be transmitted over insecure connections. This is not recommended.
解决方法:修改配置文件vim config/kibana.yml
在配置文件底部添加
xpack.security.encryptionKey: "something_at_least_32_characters"
5.检查kibana状态
在浏览器输入192.168.179.134:5601/status查看kibana状态,或者输入http://192.168.179.134:5601/api/status查看json格式的详细状态
grafana安装
1.下载RPM包并安装
wget https://dl.grafana.com/oss/release/grafana-5.4.2-1.x86_64.rpm
yum install grafana-5.4.2-1.x86_64.rpm
yum install initscripts -y2.启动grafana
通过init.d方式启动
service grafana-server start
/sbin/chkconfig --add grafana-server通过systemd启动
systemctl daemon-reload
systemctl start grafana-server
systemctl enable grafana-server.service3.修改存储数据库为mysql
默认使用sqlite3数据库,可以编辑配置文件/etc/grafana/grafana.ini,修改使用的数据库,可以选择mysql或者postgres,默认数据库文件位置/var/lib/grafana/grafana.db
创建grafana数据库
create database grafana character set utf8 collate utf8_general_ci;编辑grafana配置文件
vim /etc/grafana/grafana.ini
在[database]段下添加以下内容
type = mysql
host = 192.168.179.131:3306
name = grafana
user = root
password = "123456"重启grafana会报一个错,因为我使用的是mysql8.0的数据库,他不支持授权方法caching_sha2_password,解决方法是配置root用户使用mysql_native_password身份验证插件连接器
reason="Service init failed: Migration failed err: this authentication plugin is not supported
alter user [email protected]‘%‘ identified with mysql_native_password by ‘123456‘;
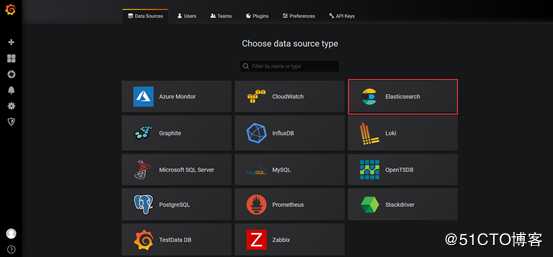
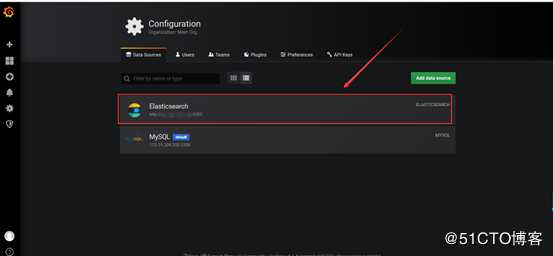
select user, plugin from mysql.user;4.添加数据源
首先添加一个elasticsearch的数据源
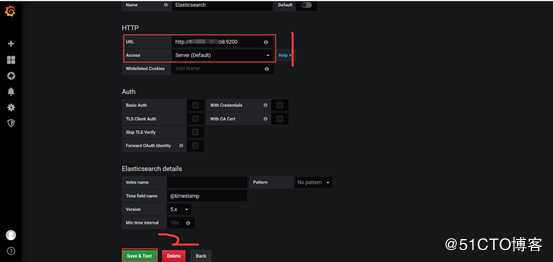
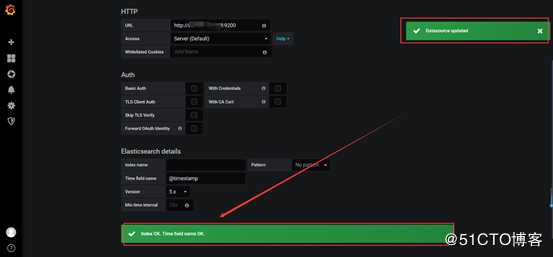
使用kibana展示数据
数据展示完成如下所示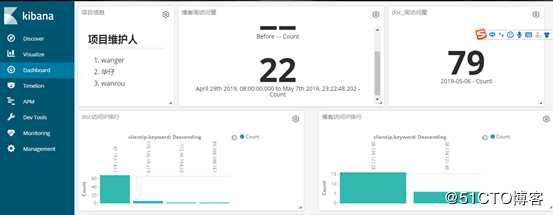
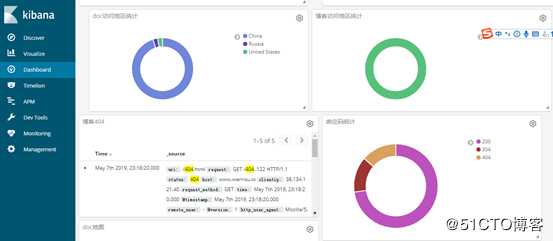
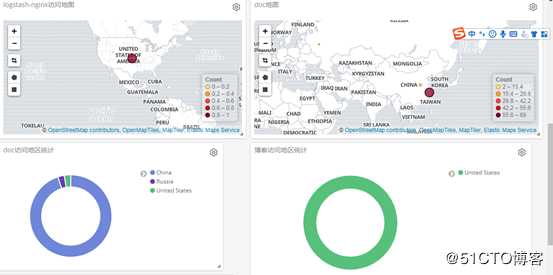
下面开始进行逐一添加
创建访问IP排行
首先创建一个柱形图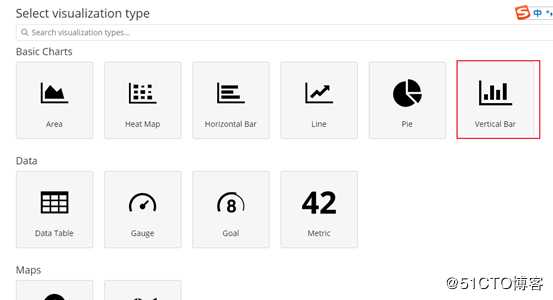
选择索引模式或者保存的搜索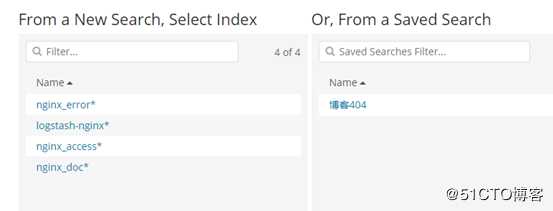
定义x轴信息,并把clientip字段作为求和的值 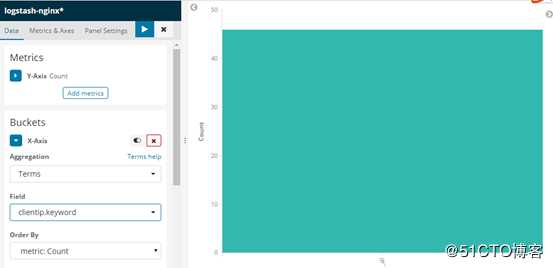
单击保存就可以创建图形了
创建访问IP的坐标地图
这一项需要依赖geoip插件,坐标地图需要有地理坐标的数据类型geo_point存在,但是es创建动态映射不会定义这些特殊的数据类型,这就需要我们自己定义映射模板,mapping信息可以复制之前自动创建的映射内容,然后修改coordinate的数据类型为geo_point就可以了,mapping信息可以从这里复制。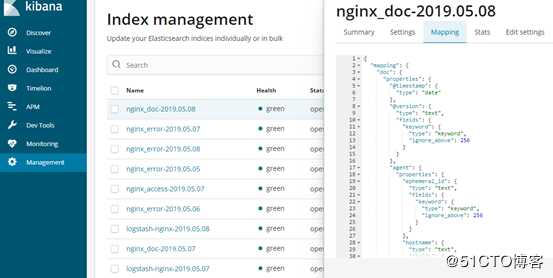
然后我们在dev tools中定义索引的模板,下图是我之前定义好的模板,创建模板使用put请求,
关于geo_point数据类型可以查看
官方文档 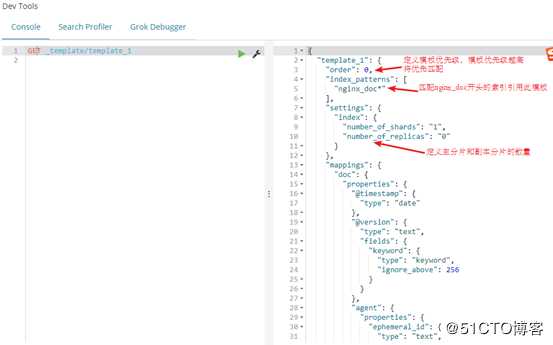
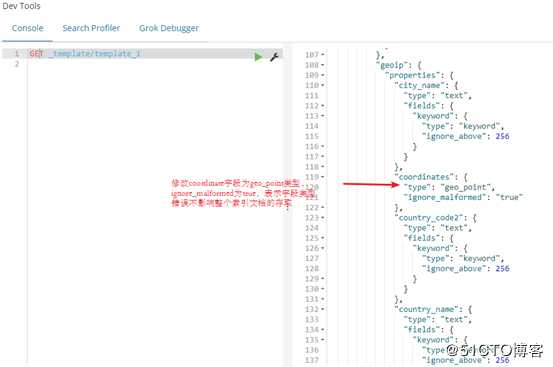
修改完之后可以删除索引并重新生成新的索引,然后需要删除索引模式,并重新创建索引模式,不然地图上可能会没有数据。
创建坐标地图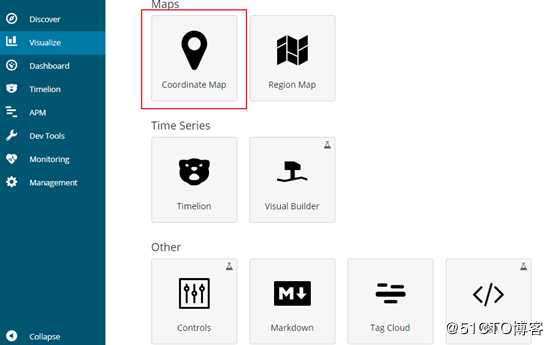
选择索引模式 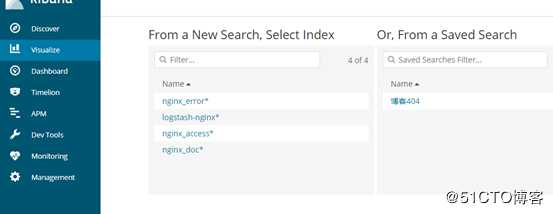
选择具有geo_point类型的字段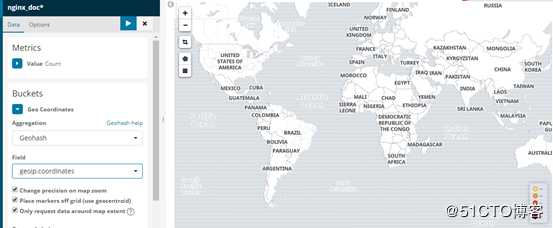
保存之后就可以看到正常的地图了
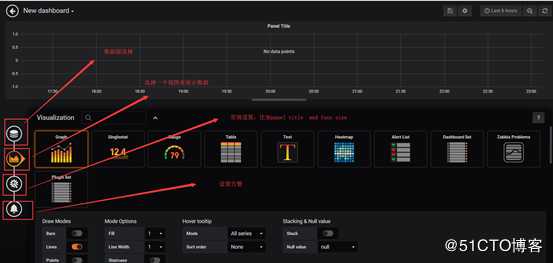
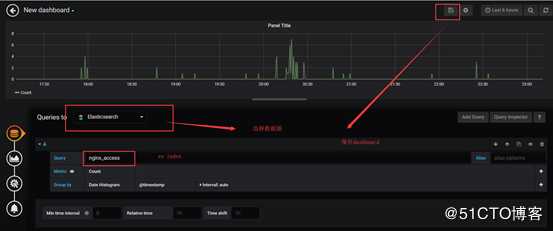
使用grafana展示数据
创建一个博客访问量的图形
欢迎各位关注我的公众号"没有故事的陈师傅"
以上是关于自建elk+filebeat+grafana日志收集平台的主要内容,如果未能解决你的问题,请参考以下文章