java的简单网络爬虫(爬取花瓣网的图片)
Posted zengtao614
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java的简单网络爬虫(爬取花瓣网的图片)相关的知识,希望对你有一定的参考价值。
因为本人对爬虫比较感兴趣,加上之前也写过一些简单的python爬虫,所以在学完java基础后写了一个简单的网络图片爬虫。废话不多说直接上过程代码。(爬取的图源来自花瓣网:https://huaban.com/boards/favorite/beauty/)
源url页面分析
拿到爬取的源url,首先是分析页面哪些东西是要爬取的,这个页面是美女分类的画板页面,这里我们要爬的就是要爬取某个画板下面的所有图片。这里为了简单爬取我就选取了该页面推荐的几个画板。查看本页面源码可以很快找到推荐画板的url资源,如下图。

可以看到要爬取目标资源就存在这个app.page["suggests"]里面,可以通过正则拿到这些url,然后依次去访问这些url,得到画板页面。
画板url的爬取
这里先写一个静态的获取页面html的方法
public static StringBuffer getHtml(String url) throws Exception{ URL url1 = new URL(url); URLConnection connection = url1.openConnection(); InputStream is = connection.getInputStream(); BufferedReader bw = new BufferedReader(new InputStreamReader(is)); StringBuffer sb = new StringBuffer(); while (bw.ready()){ sb.append(bw.readLine()).append("\\n"); } bw.close(); is.close(); return sb; }
编写爬取画板url的正则,如下
tring suggestsRegex = "app.page\\\\[\\"suggests\\"\\\\] = \\\\{.*\\\\}";
String urlRegex = "\\"url\\":\\".*?\\"";
StringBuffer html = Util.getHtml("https://huaban.com/boards/favorite/beauty/");
Matcher suggestsMatcher = Pattern.compile(suggestsRegex).matcher(html);
while (suggestsMatcher.find()){
Matcher urlMatcher = Pattern.compile(urlRegex).matcher(suggestsMatcher.group());
while (urlMatcher.find()){
System.out.println(urlMatcher.group());
}
}
可以得到下面的结果:
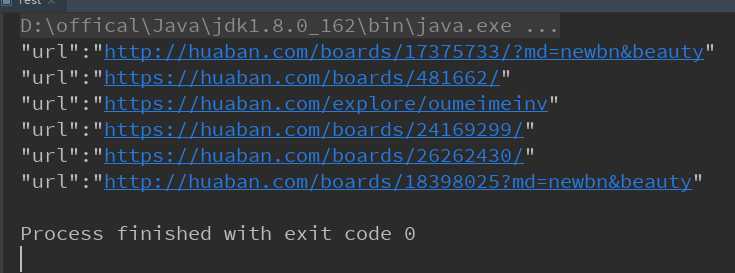
但是这些url并不全是我们需要的画板url,比如上面第三条url会跳转到另一个分类页面,而且有些url协议为http有些为https,这里测试发现协议为http的都会重定向到其对应的https页面,所以这里我们为了方便提取url,只提取目标中的画板id,就是数字部分,然后手动添加其余的部分,修改上面的部分代码如下。
while (urlMatcher.find()) { // System.out.println(urlMatcher.group()); String urlStr = urlMatcher.group(); if (urlStr.contains("boards")) { Matcher matcherId = Pattern.compile("[\\\\d]+").matcher(urlStr); String id = ""; while (matcherId.find()) { id = matcherId.group(); } String url = "https://huaban.com/boards/" + id; System.out.println(url); } }
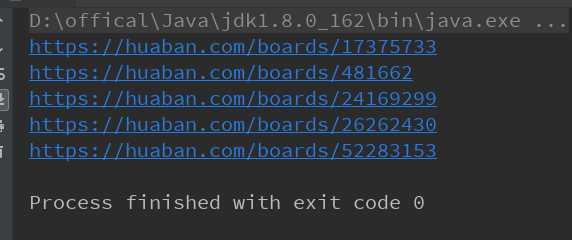
此时就得到了推荐画板的url了。
画板页面分析
这里用getHtml方法得到的画板页面html和在浏览器中查看的源码并不相同,其中源码部分的script代码被解析为了html代码被返回回来了。所以这里我们只能看控制台打印回来的代码来找到图片的url。此处就不作太多介绍,具体可自行尝试查看。
图片url的爬取
这里也是采用正则来爬(网上有选择器的方法来爬取目标资源,可自行百度),先是获取所有img标签的内容再进一步正则查询其中符合图片url特征的内容。如下
String get_img_regex = "<img src=\\"//hbimg.*?/>"; String get_src_regex = "\\"//hbimg.huabanimg.com/.*?\\""; StringBuffer html = Util.getHtml("https://huaban.com/boards/17375733"); Matcher matcherImg = Pattern.compile(get_img_regex).matcher(html); while (matcherImg.find()){ Matcher matcherSrc = Pattern.compile(get_src_regex).matcher(matcherImg.group()); while (matcherSrc.find()){ System.out.println(matcherSrc.group()); } }
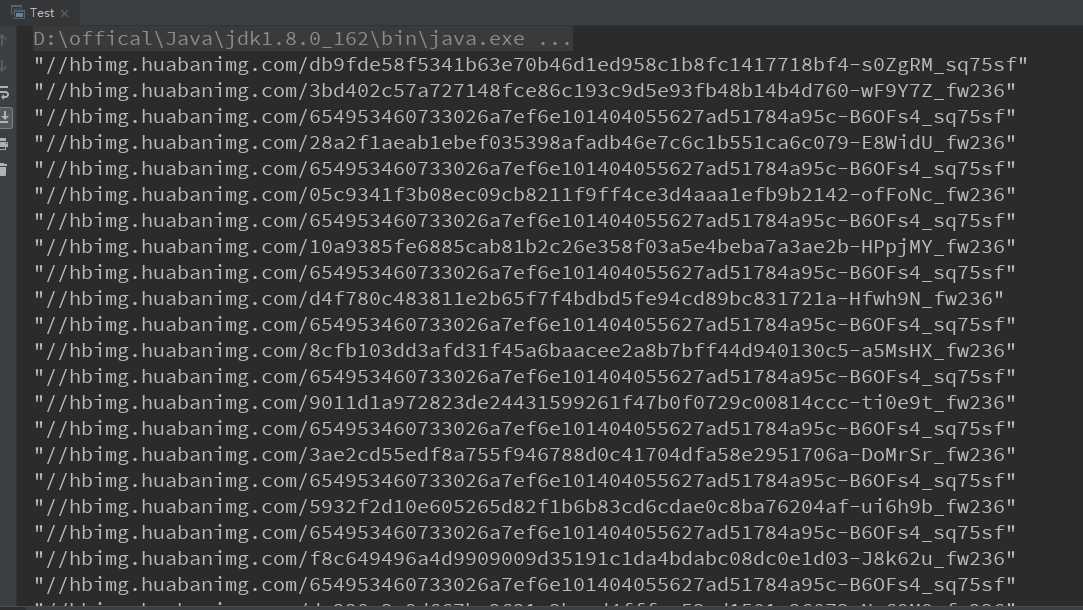
通过测试发现末尾位sq75sf的是头像图url,末尾为fw236的才是我们需要的图片url,不过是小图,我们发现大图(浏览器上点开单个图片页面即可查看大图url)的url只有末尾参数与小图url不同(大图末尾是fw658),修改上面部分代码如下
while (matcherSrc.find()){ String srcStr = matcherSrc.group(); if (srcStr.contains("fw236")){ String srcUrl = srcStr.substring(1,srcStr.length()-1).replace("fw236","fw658"); System.out.println(srcUrl); } }

最后将得到的数据用列表封装并返回即可。
图片下载
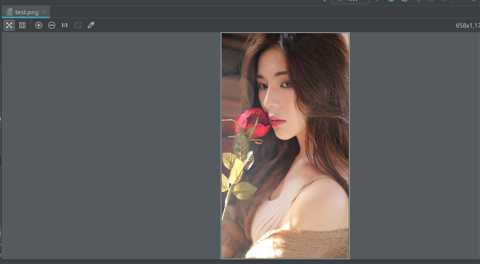
URL url = new URL("http://hbimg.huabanimg.com/3bd402c57a727148fce86c193c9d5e93fb48b14b4d760-wF9Y7Z_fw658"); InputStream is = url.openStream(); FileOutputStream fos = new FileOutputStream("src/test.png"); byte buf[] = new byte[1024]; int length = 0; while ((length=is.read(buf))!=-1){ fos.write(buf,0,length); } fos.close(); is.close();
代码优化与完善
这里简单的说一下程序优化的方案。由于有多个画板,所以每个画板可以开启一个线程进行爬取。还有就是每个画板大约只能爬到40张左右图片,那是因为页面采用Ajax加载资源(这个我也不太懂,可自行百度),可用代码模拟加载数据进而获取到所有图片。(这里每次加载请求的参数是每个页面最后一张图片的id,可自行尝试完成)
写在最后
因为本人还是个java初学者菜鸟,所以代码肯定是有漏洞和不足的地方欢迎大家指出共同学习,谢谢。
项目源码:https://github.com/zengtao614/JavaCrawler
以上是关于java的简单网络爬虫(爬取花瓣网的图片)的主要内容,如果未能解决你的问题,请参考以下文章