python爬取花瓣网任意面板图片
Posted akyna-zh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬取花瓣网任意面板图片相关的知识,希望对你有一定的参考价值。
python爬取花瓣网任意面板图片
| 版本 | 主要使用的库 |
|---|---|
| 最初版本 | re, urllib, requests |
| 升级版本 | re, urllib, requests, easygui |
| 最终版本 | re, urllib, easygui, time, selenium |
一.最初版本:
- 优点:不通过json获取, 代码少很简便
- 缺点:爬到一些多余图片且图片不是最原始的,无法滚动获取所有图片
选择爬取的html代码:

import re
import urllib.request
import requests
def getHtml(url_):
page = urllib.request.urlopen(url_)
html_ = page.read().decode('utf-8')
obj = open('text.html', 'w', encoding='utf-8')
obj.write(html_)
obj.close()
return html_
if __name__ == '__main__':
url = input()
html = getHtml(url)
# '//hbimg.huabanimg.com/...'
pattern = re.compile('(//hbimg.huabanimg.com[\\S]+)"')
keys = re.findall(pattern, html)
x = 1
print(len(keys))
for key in keys:
url = 'http:' + key
print('下载图片:' + url)
obj = open('images/' + str(x) + '.webp', 'wb+')
image = requests.get(url)
for data in image:
obj.write(data)
obj.close()
x += 1
二.升级版本:
- 优点:通过json获取, 图片是最原始的,且不会爬到多余图片
- 缺点:码量较大,时间较长, 无法滚动获取所有图片
查看面板源码,可以在对应的script中找到面板中图片的json数据:
在app.page[“board”]下可以找到"pins":[{…}],主要图片ID(pin)位于这里面。
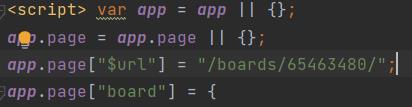
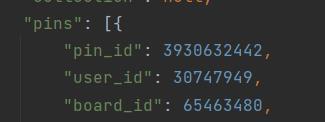
获取到图片的ID(pin)之后可以对应访问点击图片后进入的地址http://huaban.com/pins/pinId/,并获取页面源码:
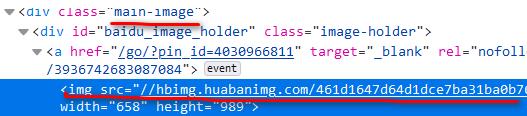 显然可见主要图片的源码特征,书写对应正则表达式可以获取图片真实地址。
显然可见主要图片的源码特征,书写对应正则表达式可以获取图片真实地址。
import urllib.request
import re
import os
import datetime
import easygui
import requests
# 获取网页
# urllib.request可获取完整html 而这里requests.get却无法获取完整代码
def get_html(url):
# 伪装成浏览器的header
fake_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; '
'WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36'
}
response = requests.get(url, headers=fake_headers) # 请求参数里面把假的请求header加上
html_ = response.content.decode('utf-8')
return html_
def get_html_1(url):
page = urllib.request.urlopen(url)
html_ = page.read().decode('utf-8')
return html_
# 下载图片
def get_image(path, html):
# 获取HTML源码里面的"pins": [{...}]部分,主要图片ID位于此部分
get_app_page_pins = re.compile('"pins":.*', re.S)
get_str = re.findall(get_app_page_pins, html)[0]
pin_id = r'"pin_id":(\\d+)' # 捕获括号内的内容
pin_id_re = re.compile(pin_id)
# 获取图片ID,保存在列表中
id_list = re.findall(pin_id_re, get_str)
print(len(id_list))
x = 0
for pinId in id_list:
# 获取跳转网页网址
url_str = r'http://huaban.com/pins/%s/' % pinId
# 获取点击图片时弹出网页的源码
pinId_source = get_html_1(url_str)
# 解析源码,获取原图片的网址
'''
<div class="main-image"><div class="image-holder" id="baidu_image_holder">
<img src="//hbimg.huabanimg.com/64369267b9c8dc7a43da81457658c05b1a752f9329ec0-dSfdfl_fw658/format/webp"
'''
img_url_re = re.compile('main-image.*?src="(.*?)"', re.S)
img_url_list = re.findall(img_url_re, pinId_source)
img_url = 'http:' + img_url_list[0]
urllib.request.urlretrieve(img_url, path + '\\%s.jpg' % x) # urlretrieve()方法直接将远程数据下载到本地
print("获取成功!%s" % img_url)
x += 1
print("保存图片成功!")
# 创建文件夹路径
def createPath():
while True:
path = easygui.diropenbox(title='选择你要保存的路径')
filePath = path + "\\\\" + str(datetime.datetime.now().strftime('%Y-%m-%d %H.%M.%S'))
isExists = os.path.exists(filePath)
if not isExists:
# 创建目录
os.makedirs(filePath)
print('%s创建成功!' % filePath)
break
else:
print('%s已存在重新输入!' % filePath)
return filePath
if __name__ == '__main__':
url = easygui.enterbox('请输入面板地址:', title='获取花瓣用户任意面板中的图片')
html = get_html(url)
obj = open('text.html', 'w', encoding='utf-8')
obj.write(html)
obj.close()
get_image(createPath(), html) # 调用创建文件夹方法并返回文件夹路径和传入网址
三.最终版本:
发现升级版本无法获取所有图片,为了追求梦想,我们必须找到更好的办法。
自然地认为页面的script代码中的pin会随着页面的滚动加载而变多,可是经过考察发现script代码中的pin并没有发生动态变化。所有该方法作废了。
无法通过json获取pin,那么就只能通过html代码了:
通过滚动页面我们可以发现加载规律:
原来的图片对应的代码:
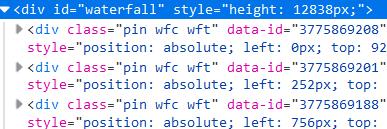 经过滚动,原来的代码逐渐被一些新的代码取代:
经过滚动,原来的代码逐渐被一些新的代码取代:
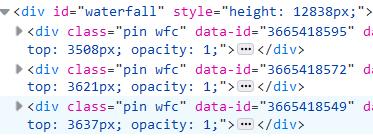
而不难发现他们都有对应的data-id!而data-id就是图片地址中对应的pin!
所以我们可以通过webdriver滚动加载页面,每滚动一次就进行一次data-id的读取,并利用集合进行去重即可!这样可以获取面板中几乎所有图片的pin(有一小部分图片可能由于网络,地址改变等原因无法获取)
-
优点:图片是最原始的,且不会爬到多余图片,可以获取面板下所有图片
-
缺点:码量较大,时间更长
import urllib.request
import urllib.error
import re
import os
import datetime
import easygui
import time
from selenium import webdriver
# 获取网页中所有图片对应的pin
def get_pins(url_):
options = webdriver.ChromeOptions()
options.add_argument("User-Agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0")
driver = webdriver.Chrome(chrome_options=options)
driver.get(url_)
js1 = "window.scrollTo(0,document.body.scrollHeight);"
js2 = "h=document.documentElement.scrollTop; return h"
pattern = re.compile(r'data-id=?"(\\d*)"')
origin_top = driver.execute_script(js2)
pins_ = set()
# 可以使用大括号 { } 或者 set() 函数创建集合,但是注意如果创建一个空集合必须用 set() 而不是 { },因为{}是用来表示空字典类型的。
while True:
html_ = driver.page_source
pins_1 = re.findall(pattern, html_)
pins_2 = set(pins_1)
pins_.update(pins_2)
driver.execute_script(js1)
new_top = driver.execute_script(js2)
time.sleep(1)
if new_top == origin_top:
break
else:
origin_top = new_top
driver.close()
return pins_
# 获取页面html
def get_html_1(url_):
try:
page = urllib.request.urlopen(url_)
except urllib.error.URLError:
return 'fail'
html_ = page.read().decode('utf-8')
return html_
# 下载图片
def get_image(path_, pin_list):
x = 1
for pinId in pin_list:
# 获取跳转网页网址
url_str = r'http://huaban.com/pins/%s/' % pinId
# 获取点击图片时弹出网页的源码
pinId_source = get_html_1(url_str)
if pinId_source == 'fail':
continue
# 解析源码,获取原图片的网址
'''
<div class="main-image"><div class="image-holder" id="baidu_image_holder">
<img src="//hbimg.huabanimg.com/64369267b9c8dc7a43da81457658c05b1a752f9329ec0-dSfdfl_fw658/format/webp"
'''
img_url_re = re.compile('main-image.*?src="(.*?)"', re.S)
img_url_list = re.findall(img_url_re, pinId_source)
img_url = 'http:' + img_url_list[0]
try:
urllib.request.urlretrieve(img_url, path_ + '\\%s.jpg' % x) # urlretrieve()方法直接将远程数据下载到本地
except urllib.error.URLError:
print("获取失败!%s" % img_url)
continue
print("获取成功!%s" % img_url)
x += 1
print("保存图片成功!")
# 创建文件夹路径
def createPath():
while True:
path_ = easygui.diropenbox(title='选择你要保存的路径')
filePath = path_ + "\\\\" + str(datetime.datetime.now().strftime('%Y-%m-%d %H.%M.%S'))
isExists = os.path.exists(filePath)
if not isExists:
# 创建目录
os.makedirs(filePath)
print('%s创建成功!' % filePath)
break
else:
print('%s已存在重新输入!' % filePath)
return filePath
if __name__ == '__main__':
url = easygui.enterbox('请输入面板地址:', title='获取花瓣用户任意面板中的图片')
path = createPath()
pins = get_pins(url)
print(len(pins))
get_image(path, pins)
最终测试:
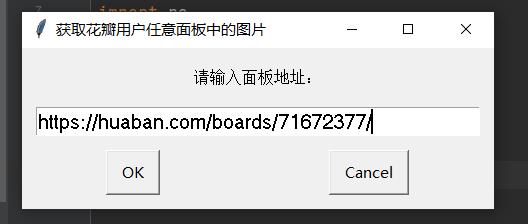
1.输入网址:
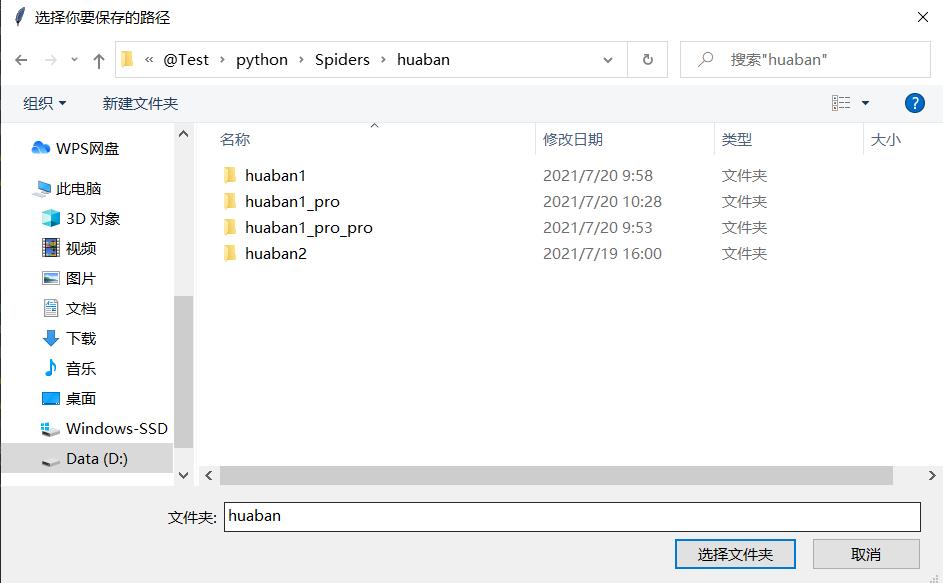
 2.选择路径
2.选择路径
 3.动态加载中…
3.动态加载中…
4.获取图片中…
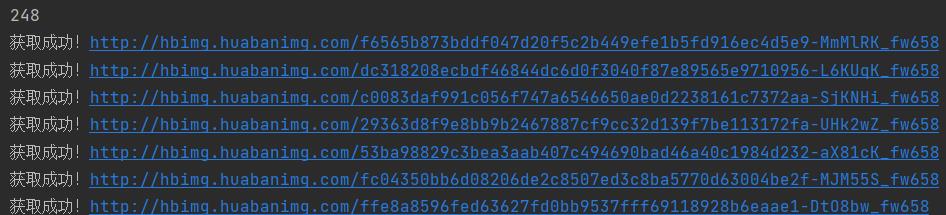 5.获取完毕:
5.获取完毕:
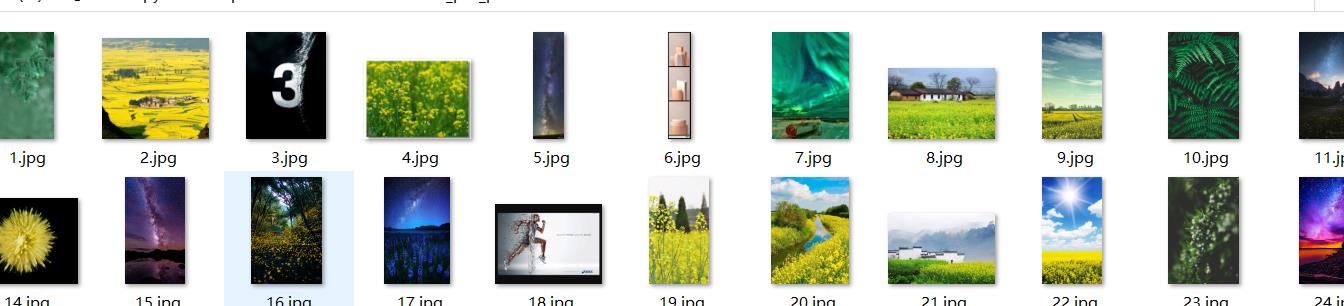
over!!
以上是关于python爬取花瓣网任意面板图片的主要内容,如果未能解决你的问题,请参考以下文章