熔断,限流,降级
Posted qianjinyan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了熔断,限流,降级相关的知识,希望对你有一定的参考价值。
https://www.cnblogs.com/raoshaoquan/articles/6636067.html
https://www.cnblogs.com/DengGao/p/rateLimit.html
https://blog.csdn.net/aa1215018028/article/details/81700796
https://www.jianshu.com/p/3463571febc2
https://www.jianshu.com/p/33f394c0ee2d
https://blog.csdn.net/chunlongyu/article/details/53259014
1 写在前面
1.1 名词解释
consumer表示服务调用方
provider标示服务提供方,dubbo里面一般就这么讲。
下面的A调用B服务,一般是泛指调用B服务里面的一个接口。
1.2 拓扑图
大写字母表示不同的服务,后面的序号表示同一个服务部署在不同机器的实例。
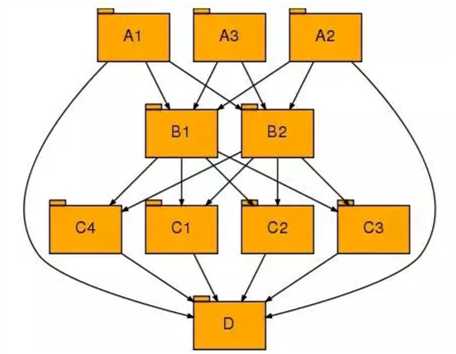
2 从微观角度思考
2.1 超时(timeout)
在接口调用过程中,consumer调用provider的时候,provider在响应的时候,有可能会慢,如果provider 10s响应,那么consumer也会至少10s才响应。如果这种情况频度很高,那么就会整体降低consumer端服务的性能。
这种响应时间慢的症状,就会像一层一层波浪一样,从底层系统一直涌到最上层,造成整个链路的超时。
所以,consumer不可能无限制地等待provider接口的返回,会设置一个时间阈值,如果超过了这个时间阈值,就不继续等待。
这个超时时间选取,一般看provider正常响应时间是多少,再追加一个buffer即可。
2.2 重试(retry)
超时时间的配置是为了保护服务,避免consumer服务因为provider 响应慢而也变得响应很慢,这样consumer可以尽量保持原有的性能。
但是也有可能provider只是偶尔抖动,那么超时后直接放弃,不做后续处理,就会导致当前请求错误,也会带来业务方面的损失。
那么,对于这种偶尔抖动,可以在超时后重试一下,重试如果正常返回了,那么这次请求就被挽救了,能够正常给前端返回数据,只不过比原来响应慢一点。
重试时的一些细化策略:
重试可以考虑切换一台机器来进行调用,因为原来机器可能由于临时负载高而性能下降,重试会更加剧其性能问题,而换一台机器,得到更快返回的概率也更大一些。
2.2.1 幂等(idempotent)
如果允许consumer重试,那么provider就要能够做到幂等。
即,同一个请求被consumer多次调用,对provider产生的影响(这里的影响一般是指某些写入相关的操作) 是一致的。
而且这个幂等应该是服务级别的,而不是某台机器层面的,重试调用任何一台机器,都应该做到幂等。
2.3 熔断(circuit break)
重试是为了应付偶尔抖动的情况,以求更多地挽回损失。
可是如果provider持续的响应时间超长呢?
如果provider是核心路径的服务,down掉基本就没法提供服务了,那我们也没话说。 如果是一个不那么重要的服务,却因为这个服务一直响应时间长导致consumer里面的核心服务也拖慢,那么就得不偿失了。
单纯超时也解决不了这种情况了,因为一般超时时间,都比平均响应时间长一些,现在所有的打到provider的请求都超时了,那么consumer请求provider的平均响应时间就等于超时时间了,负载也被拖下来了。
而重试则会加重这种问题,使consumer的可用性变得更差。
因此就出现了熔断的逻辑,也就是,如果检查出来频繁超时,就把consumer调用provider的请求,直接短路掉,不实际调用,而是直接返回一个mock的值。
等provider服务恢复稳定之后,重新调用。
2.3.1 简单的熔断处理逻辑
目前我们框架有通过注解使用的熔断器,大家可以参考应用在项目中。
2.4 限流(current limiting)
上面几个策略都是consumer针对provider出现各种情况而设计的。
而provider有时候也要防范来自consumer的流量突变问题。
这样一个场景,provider是一个核心服务,给N个consumer提供服务,突然某个consumer抽风,流量飙升,占用了provider大部分机器时间,导致其他可能更重要的consumer不能被正常服务。
所以,provider端,需要根据consumer的重要程度,以及平时的QPS大小,来给每个consumer设置一个流量上线,同一时间内只会给A consumer提供N个线程支持,超过限制则等待或者直接拒绝。
2.4.1 资源隔离
provider可以对consumer来的流量进行限流,防止provider被拖垮。
同样,consumer 也需要对调用provider的线程资源进行隔离。 这样可以确保调用某个provider逻辑不会耗光整个consumer的线程池资源。
2.4.2 服务降级
降级服务既可以代码自动判断,也可以人工根据突发情况切换。
2.4.2.1 consumer 端
consumer 如果发现某个provider出现异常情况,比如,经常超时(可能是熔断引起的降级),数据错误,这是,consumer可以采取一定的策略,降级provider的逻辑,基本的有直接返回固定的数据。
2.4.2.2 provider 端
当provider 发现流量激增的时候,为了保护自身的稳定性,也可能考虑降级服务。
比如,1,直接给consumer返回固定数据,2,需要实时写入数据库的,先缓存到队列里,异步写入数据库。
3 从宏观角度重新思考
宏观包括比A -> B 更复杂的长链路。
长链路就是 A -> B -> C -> D这样的调用环境。
而且一个服务也会多机部署,A 服务实际会存在 A1,A2,A3 …
微观合理的问题,宏观未必合理。
下面的一些讨论,主要想表达的观点是:如果系统复杂了,系统的容错配置要整体来看,整体把控,才能做到更有意义。
3.1 超时
如果A给B设置的超时时间,比B给C设置的超时时间短,那么肯定不合理把,A超时时间到了直接挂断,B对C支持太长超时时间没意义。
R表示服务consumer自身内部逻辑执行时间,TAB表示consumer A开始调用provider B到返回的时间 。
那么那么TAB > RB + TBC 才对。
3.2 重试
重试跟超时面临的问题差不多。
B服务一般100ms返回,所以A就给B设置了110ms的超时,而B设置了对C的一次重试,最终120ms正确返回了,但是A的超时时间比较紧,所以B对C的重试被白白浪费了。
A也可能对B进行重试,但是由于上一条我们讲到的,可能C确实性能不好,每次B重试一下就OK,但是A两次重试其实都无法正确的拿到结果。
N标示设置的重试次数
修正一下上面section的公式,TAB > RB+TBC * N。
虽然这个公式本身没什么问题,但是,如果站在长链路的视角来思考,我们需要整体规划每个服务的超时时间和重试次数,而不是仅仅公式成立即可。
比如下面情况:
A -> B -> C。
RB = 100ms,TBC=10ms
B是个核心服务,B的计算成本特别大,那么A就应该尽量给B长一点的超时时间,而尽量不要重试调用B,而B如果发现C超时了,B可以多调用几次C,因为重试C成本小,而重试B成本则很高。 so …
3.3 熔断
A -> B -> C,如果C出现问题了,那么B熔断了,则A就不用熔断了。
3.4 限流
B只允许A以QPS<=5的流量请求,而C却只允许B以QPS<=3的qps请求,那么B给A的设定就有点大,上游的设置依赖下游。
而且限流对QPS的配置,可能会随着服务加减机器而变化,最好是能在集群层面配置,自动根据集群大小调整。
3.5 服务降级
服务降级这个问题,如果从整体来操作,
1,一定是先降级优先级地的接口,两权相害取其轻
2,如果服务链路整体没有性能特别差的点,比如就是外部流量突然激增,那么就从外到内开始降级。
3如果某个服务能检测到自身负载上升,那么可以从这个服务自身做降级。
3.6 涟漪
A -> B -> C,如果C服务出现抖动,而B没有处理好这个抖动,造成B服务也出现了抖动,A调用B的时候,也会出现服务抖动的情况。
这个暂时的不可用状态就想波浪一样从底层传递到了上层。
所以,从整个体系的角度来看,每个服务一定要尽量控制住自己下游服务的抖动,不要让整个体系跟着某个服务抖动。
3.7 级联失败(cascading failure)
系统中有某个服务出现故障,不可用,传递性地导致整个系统服务不可用的问题。
跟上面涟漪(自造词)的区别也就是严重性的问题。
涟漪描述服务偶发的不稳定层层传递,而级联失败基本是导致系统不可用。 一般,前者可能会因为短时间内恢复而未引起重视,而后者一般会被高度重视。
3.8 关键路径
关键路径就是,你的服务想正常工作,必须要完整依赖的下游服务链,比如数据库一般就是关键路径里面的一个节点。
尽量减少关键路径依赖的数量,是提高服务稳定性的一个措施。
数据库一般在服务体系的最底层,如果你的服务可以会自己完整缓存使用的数据,解除数据库依赖,那么数据库挂掉,你的服务就暂时是安全的。
3.9 最长路径
想要优化你的服务的响应时间,需要看服务调用逻辑里面的最长路径,只有缩短最长时间路径的用时,才能提高你的服务的性能。
以上是关于熔断,限流,降级的主要内容,如果未能解决你的问题,请参考以下文章