05Hadoop 概论
Posted jbli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了05Hadoop 概论相关的知识,希望对你有一定的参考价值。
Hadoop的思想之源:Google
Google搜索引擎
,Gmail,安卓,
AppspotGoogle Maps,
Google earth,Google 学术,
Google翻译,Google+,下一步Google what??
Google的低成本之道
?不使用超级计算机,不使用存储(淘宝的去i,去e,去o之路)
?大量使用普通的pc服务器(去掉机箱,外设,硬盘),
提供有冗余的集群服务 ?全世界多个数据中心,有些附带发电厂 ?运营商向Google倒付费
Hadoop的起源 --Lucene
Doug Cutting开创的开源源软件,用java书写的代码,实现与Google类似的全文搜索功能,
它提供了全文检索引擎的框架,包括完整的查询引擎和索引引擎 早期发布在个人网站和SourceFage上 ,
2001年底成为Apache软件基金会jakarta的一个子项目 Lucene的目的是为软件开发人员提供一套简单易用的工具包,
以方便的在目标系统中实现全文检索的功能 对于大数据量的检索,lucene面临这和Google一样的困难。
迫使DougCutting学习和模仿Google解决这些问题的方法 一个微缩版nutch
从 Lucene到nutch ,从nutch到Hadoop
2003-2004年,Google公开了部分GFS和MapReduce的思想细节,
以此为基础,DougCutting等人用了2年的业余时间实现了DFS和MapReduce机制,
使Nutch性能飘升 Yahoo招安了DougCutting及其子项目
Hadoop于2005秋天作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年3月份,MapReduce和Nutch Distributed FileSystem (NDFS)分别是被纳入到Hadoop的项目中
名字来源于DougCutting儿子的一个玩具大象
Doug Cutting


目前Hadoop达到的高度

传统场景:面临的问题

Hadoop的思想
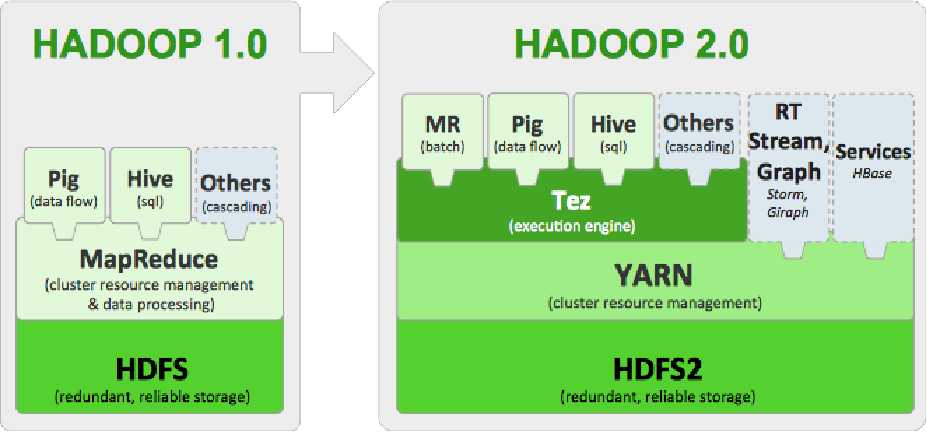
Hadoop 2.x、 生态系统
大数据处理业务应用
大型网站Web服务器的日志分析:一个大型网站的Web服务器集群,
每5分钟收录的点击日志高达800GB左右,峰值点击每秒达到900万次。
每隔5分钟将数据装载到内存中,高速计算网站的热点URL,
并将这些信息反馈给前端缓存服务器,以提高缓存命中率。
运营商流量经营分析:每天的流量数据在2TB~5TB左右,拷贝到HDFS上,通过交互式分析引擎框架,
能运行几百个复杂的数据清洗和报表业务,总时间比类似硬件配置的小型机集群和DB2快2~3倍。
IPTV收视统计与点播推荐:一个实时收视率统计和点播推荐系统,可以实时收集用户的遥控器操作,
提供实时的收视率榜单;并且根据内容推荐和协同过滤算法,实现了点播推荐服务。
城市交通卡口视频监控信息的实时分析:采用基于流式 Stream进行全省范围的交通卡口通过视频监控收录的信息进行实时分析、
告警和统计(计算实时路况),对全省范围内未年检车辆或套牌车的分析延时在300毫秒左右,
可以做出实时告警,所以开车的朋友最好要按时年检。
培养三大能力
1)学习能力 自我学习能力,接受新鲜事物。
2)解决问题能力 发现 问题、分析问题(静下心来)、解决问题(如何解决)
3)沟通交际能力 与人打交通,肯定与沟通交际,不要与同事上司还是下属关系不好。
Hadoop: The Definitive Guide


Apache Hadoop 起源
Apache Lucene 开源的高性能全文检索工具包
Apache Nutch 开源的 Web 搜索引擎
Google 三大论文MapReduce / GFS / BigTable
Apache Hadoop 大规模数据处理
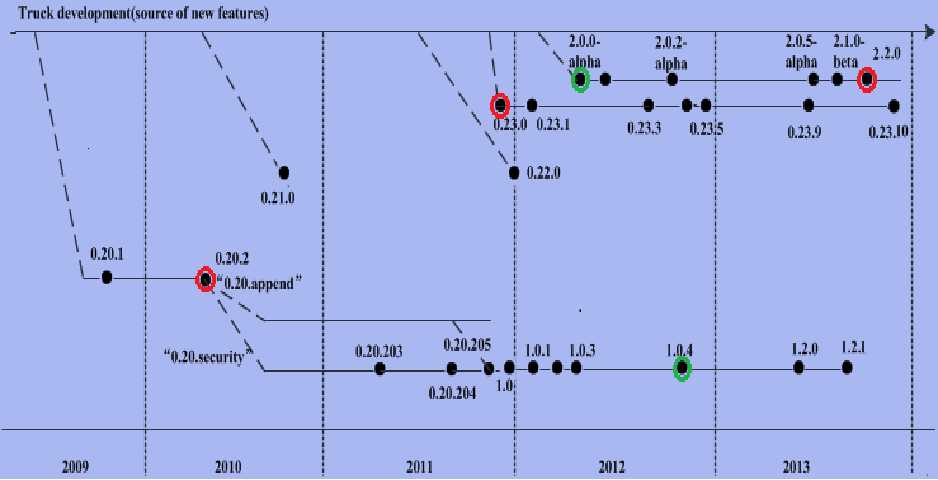
Apache Hadoop 版本演化
大数据Hadoop安装过程
Hadoop 环境准备 使用SCP传输数据 安装JDK 安装Hadoop
安装包目录结构


以上是关于05Hadoop 概论的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之_03_Hadoop学习_01_入门_大数据概论+从Hadoop框架讨论大数据生态+Hadoop运行环境搭建(开发重点)