决策树的实现
Posted hhxz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树的实现相关的知识,希望对你有一定的参考价值。
样本选自周志华老师的西瓜书
样本:
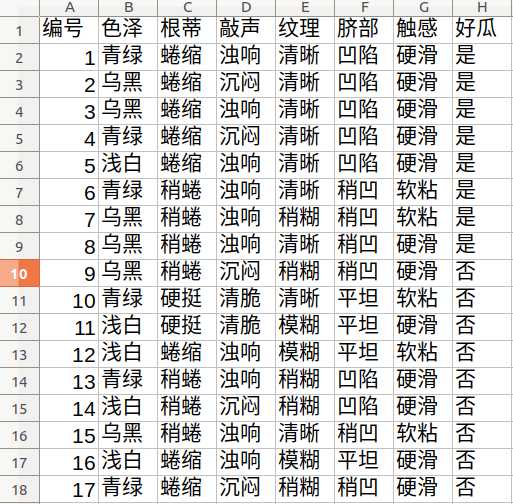
将上面的样本制作成为一个CSV文件,保存的编码为utf8,文中保存在/home/jsj/datetest/下名字wm20.csv
需要导入的文件:
import csv#导入csv库
from sklearn.feature_extraction import DictVectorizer#转换工具,将list转换成为一个数组
from sklearn import preprocessing
from sklearn import tree #创建决策树
import numpy as np
1)导入文件:
#csv的读取
file = csv.reader((open("/home/jsj/datatest/wm20.csv","rt")))#注意保存utf8
print(file)#获取文件信息
#file.decode("utf8","ignore")
headers = next(file)#获取并打印头信息
print(headers)
这段代码的运行结果:
<_csv.reader object at 0x7fa77d171198>
[‘编号‘, ‘色泽‘, ‘根蒂‘, ‘敲声‘, ‘纹理‘, ‘脐部‘, ‘触感‘, ‘好瓜‘])
2)分离标签和特征值
#将行信息转变成为list和Dict
featurelist = []#创建一个特征列表
labellist = []#创建一个标签列表
for row in file:
labellist.append(row[len(row) -1])#每一次获取最后一行值,添加到标签列表中
rowDict = {}#每一次都创建一个字典接受列值
for i in range(1,len(row)-1):#从第二位置开始添加
rowDict[headers[i]] = row[i]#添加字典的对应特征值
featurelist.append(rowDict)#每次添加一行
print(labellist)#获取到的标签值
print(featurelist)#获取到的每一行的特征值,每一个字典相当于一个元素
这段代码的运行结果:
[‘是‘, ‘是‘, ‘是‘, ‘是‘, ‘是‘, ‘是‘, ‘是‘, ‘是‘, ‘否‘, ‘否‘, ‘否‘, ‘否‘, ‘否‘, ‘否‘, ‘否‘, ‘否‘, ‘否‘]
[{‘色泽‘: ‘青绿‘, ‘根蒂‘: ‘蜷缩‘, ‘敲声‘: ‘浊响‘, ‘纹理‘: ‘清晰‘, ‘脐部‘: ‘凹陷‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘乌黑‘, ‘根蒂‘: ‘蜷缩‘, ‘敲声‘: ‘沉闷‘, ‘纹理‘: ‘清晰‘, ‘脐部‘: ‘凹陷‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘乌黑‘, ‘根蒂‘: ‘蜷缩‘, ‘敲声‘: ‘浊响‘, ‘纹理‘: ‘清晰‘, ‘脐部‘: ‘凹陷‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘青绿‘, ‘根蒂‘: ‘蜷缩‘, ‘敲声‘: ‘沉闷‘, ‘纹理‘: ‘清晰‘, ‘脐部‘: ‘凹陷‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘浅白‘, ‘根蒂‘: ‘蜷缩‘, ‘敲声‘: ‘浊响‘, ‘纹理‘: ‘清晰‘, ‘脐部‘: ‘凹陷‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘青绿‘, ‘根蒂‘: ‘稍蜷‘, ‘敲声‘: ‘浊响‘, ‘纹理‘: ‘清晰‘, ‘脐部‘: ‘稍凹‘, ‘触感‘: ‘软粘‘}, {‘色泽‘: ‘乌黑‘, ‘根蒂‘: ‘稍蜷‘, ‘敲声‘: ‘浊响‘, ‘纹理‘: ‘稍糊‘, ‘脐部‘: ‘稍凹‘, ‘触感‘: ‘软粘‘}, {‘色泽‘: ‘乌黑‘, ‘根蒂‘: ‘稍蜷‘, ‘敲声‘: ‘浊响‘, ‘纹理‘: ‘清晰‘, ‘脐部‘: ‘稍凹‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘乌黑‘, ‘根蒂‘: ‘稍蜷‘, ‘敲声‘: ‘沉闷‘, ‘纹理‘: ‘稍糊‘, ‘脐部‘: ‘稍凹‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘青绿‘, ‘根蒂‘: ‘硬挺‘, ‘敲声‘: ‘清脆‘, ‘纹理‘: ‘清晰‘, ‘脐部‘: ‘平坦‘, ‘触感‘: ‘软粘‘}, {‘色泽‘: ‘浅白‘, ‘根蒂‘: ‘硬挺‘, ‘敲声‘: ‘清脆‘, ‘纹理‘: ‘模糊‘, ‘脐部‘: ‘平坦‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘浅白‘, ‘根蒂‘: ‘蜷缩‘, ‘敲声‘: ‘浊响‘, ‘纹理‘: ‘模糊‘, ‘脐部‘: ‘平坦‘, ‘触感‘: ‘软粘‘}, {‘色泽‘: ‘青绿‘, ‘根蒂‘: ‘稍蜷‘, ‘敲声‘: ‘浊响‘, ‘纹理‘: ‘稍糊‘, ‘脐部‘: ‘凹陷‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘浅白‘, ‘根蒂‘: ‘稍蜷‘, ‘敲声‘: ‘沉闷‘, ‘纹理‘: ‘稍糊‘, ‘脐部‘: ‘凹陷‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘乌黑‘, ‘根蒂‘: ‘稍蜷‘, ‘敲声‘: ‘浊响‘, ‘纹理‘: ‘清晰‘, ‘脐部‘: ‘稍凹‘, ‘触感‘: ‘软粘‘}, {‘色泽‘: ‘浅白‘, ‘根蒂‘: ‘蜷缩‘, ‘敲声‘: ‘浊响‘, ‘纹理‘: ‘模糊‘, ‘脐部‘: ‘平坦‘, ‘触感‘: ‘硬滑‘}, {‘色泽‘: ‘青绿‘, ‘根蒂‘: ‘蜷缩‘, ‘敲声‘: ‘沉闷‘, ‘纹理‘: ‘稍糊‘, ‘脐部‘: ‘稍凹‘, ‘触感‘: ‘硬滑‘}]
3)将特征值转换成为0、1数组
#将获得特征值字典转变成为数组
vec = DictVectorizer()#获取转换对象
dummyX = vec.fit_transform(featurelist).toarray()#将特征值的list转变成为一个数组
print("dummyX:" + str(dummyX))
print(vec.get_feature_names())#获取特征所有的取值
这段代码的运行结果:
dummyX:[[0. 1. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 1. 0. 0. 1. 0.]
[0. 1. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 0. 0. 1. 1. 0.]
[0. 1. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 0. 1. 0. 1. 0.]
[0. 1. 0. 0. 1. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1. 1. 0. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1. 1. 0. 0. 1. 0.]
[0. 0. 1. 1. 0. 0. 0. 1. 0. 0. 1. 0. 0. 0. 1. 0. 1.]
[0. 0. 1. 1. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1. 0. 1. 0.]
[0. 1. 0. 0. 0. 1. 1. 0. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 0. 1. 1. 0. 0. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1. 0. 0. 0. 1. 1. 0. 0. 0. 1. 0. 1. 0.]
[0. 1. 0. 0. 1. 0. 0. 1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[0. 1. 0. 0. 0. 1. 1. 0. 0. 0. 1. 0. 0. 1. 0. 1. 0.]
[1. 0. 0. 0. 0. 1. 0. 0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]]
[‘敲声=沉闷‘, ‘敲声=浊响‘, ‘敲声=清脆‘, ‘根蒂=硬挺‘, ‘根蒂=稍蜷‘, ‘根蒂=蜷缩‘, ‘纹理=模糊‘, ‘纹理=清晰‘, ‘纹理=稍糊‘, ‘脐部=凹陷‘, ‘脐部=平坦‘, ‘脐部=稍凹‘, ‘色泽=乌黑‘, ‘色泽=浅白‘, ‘色泽=青绿‘, ‘触感=硬滑‘, ‘触感=软粘‘]
4)转换标签为0、1数组
#将获取的标签list转变
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labellist)
print("dummyY" + str(dummyY))
这段代码结果为:
dummyY[[1]
[1]
[1]
[1]
[1]
[1]
[1]
[1]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]
[0]]
5)使用id3建立决策树
#创建分类器
clf = tree.DecisionTreeClassifier(criterion= "entropy")#使用Id3
clf = clf.fit(dummyX,dummyY)
print("clf:"+str(clf))
这段代码结果为:
clf:DecisionTreeClassifier(class_weight=None, criterion=‘entropy‘, max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter=‘best‘)
6)创建出文件
with open("/home/jsj/datatest/wm20.dot","w") as f:
f = tree.export_graphviz(clf,feature_names = vec.get_feature_names(),out_file= f)#使用export_graphviz
这段代码结果为:
会产生一个wm20.dot的文件

文件打开之后形式如下:

上面是使用export_graphviz建立好的决策树,可以使用graphviz产生图片,详情见https://blog.csdn.net/adaptiver/article/details/53701015
使用命令:dot -Tpng wm20.dot -o wm20.png产生下列图:
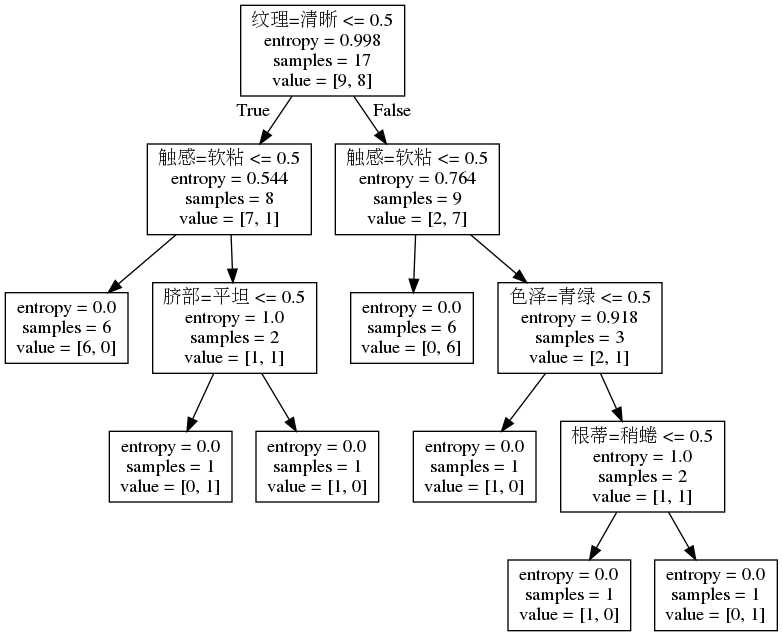
7)预测
#预测新的数据如:‘浅白‘, ‘蜷缩‘, ‘浊响‘, ‘清晰‘, ‘稍凹‘, ‘硬滑‘
newRowX = oneRowX;
#修改数据不同的地方
#将青绿转变成为浅白
newRowX[2] = 0
newRowX[0] = 1
#将凹陷转变成为稍凹
newRowX[14] = 0
newRowX[13] = 1
"""由于在新版的sklearn中,
所有的数据都应该是二维矩阵,哪怕它只是单独一行或一列(
比如前面做预测时,仅仅只用了一个样本数据),
所以需要使用.reshape(1,-1)进行转换,具体操作如下"""
newRowX = np.array(newRowX).reshape(1, -1)
print("newRowX :" + str(newRowX))
pY = clf.predict(newRowX)
print("pY :" + str(pY))
这段代码结果为:
[0. 1. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 0. 0. 1. 1. 0.]
newRowX :[[1. 1. 0. 0. 0. 1. 0. 1. 0. 1. 0. 0. 0. 1. 0. 1. 0.]]
pY :[1]
--可以看到这里是好瓜
以上是关于决策树的实现的主要内容,如果未能解决你的问题,请参考以下文章
[机器学习与scikit-learn-15]:算法-决策树-分类问题代码详解