需求:爬取https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html页面中的新闻数据。
分析:
1.首先通过分析页面会发现该页面中的新闻数据都是动态加载出来的,并且通过抓包工具抓取数据可以发现动态数据也不是ajax请求获取的动态数据(因为没有捕获到ajax请求的数据包),那么只剩下一种可能,该动态数据是js动态生成的。
2.通过抓包工具查找到底数据是由哪个js请求产生的动态数据:打开抓包工具,然后对首页url(第一行需求中的url)发起请求,捕获所有的请求数据包。
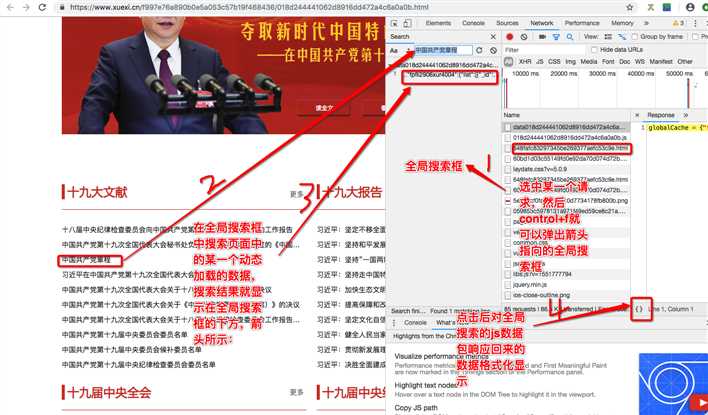
分析js数据包响应回来的数据:
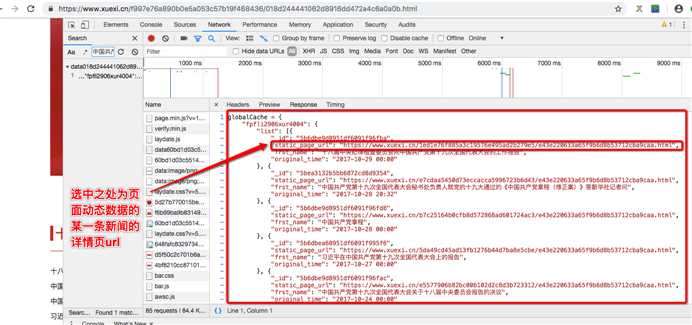
该响应数据对应的url可以在抓包工具对应的该数据包的header选项卡中获取。获取url后,对其发起请求即可获取上图中选中的相应数据,该响应数据类型为application/javascript类型,所以可以将获取的响应数据通过正则提取出最外层大括号中的数据,然后使用json.loads将其转为字典类型,然后逐步解析出数据中所有新闻详情页的url即可。
- 获取详情页中对应的新闻详情数据:对详情页发起请求后,会发现详情页的新闻数据也是动态加载出来的,因此还是跟上述步骤一样,在抓包工具中对详情页中的局部数据进行搜索,定位到指定的js数据包:
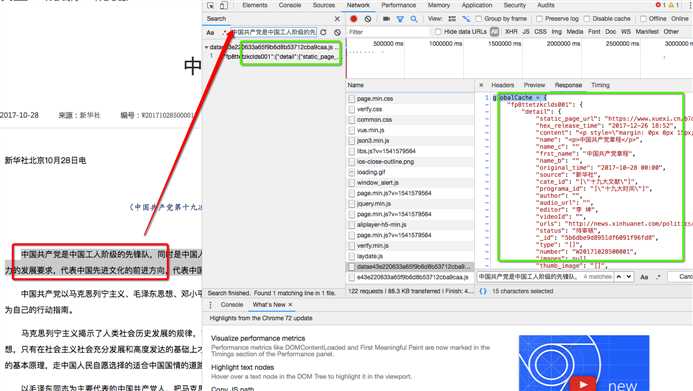
该js数据包的url为:
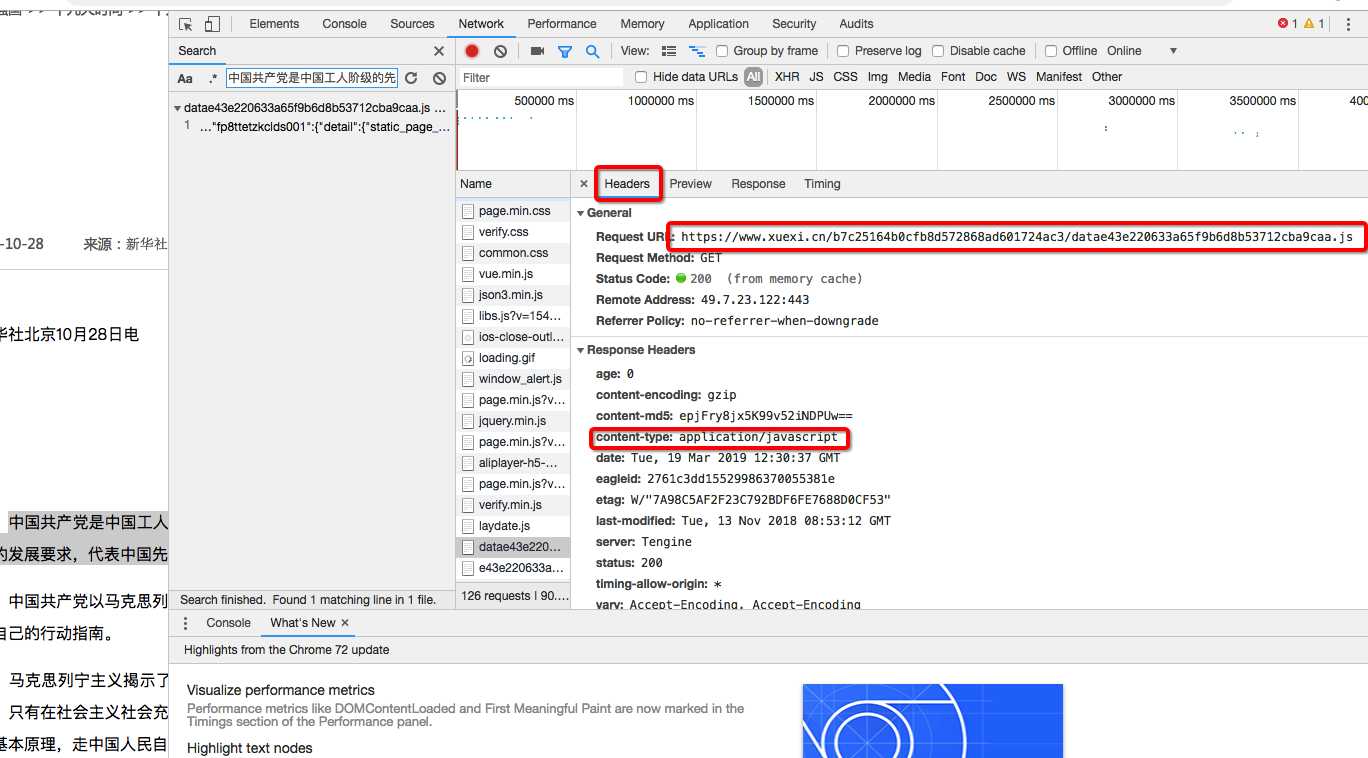
详情页url,获取后,即可请求到该数据包对应的响应数据了,该相应数据中就包含了对应新闻详情数据了。注意,该响应数据的类型同样为application/javascript,所以数据解析同上!
分析首页中所有新闻的详情页url和新闻详情数据对应的js数据包的url之间的关联:
- 首页中某一新闻详情页的url: https://www.xuexi.cn/5c39c314138da31babf0b16af5a55da4/e43e220633a65f9b6d8b53712cba9caa.html
- 该新闻详情数据对应的js数据包的url:https://www.xuexi.cn/5c39c314138da31babf0b16af5a55da4/datae43e220633a65f9b6d8b53712cba9caa.js
- 所有的新闻详情对应的js数据包的黄色选中部分都是一样的只是红色部分各自不同,但是红色部分却和该新闻详情页的url中的红色部分是相同的!!!新闻详情页的url是可以在上述过程中解析出来的。因此现在就可以批量产生出详情数据对应js数据包的url的,然后批量进行数据请求,获取响应数据,然后对响应数据进行解析即可完成最终的需求!