js的网页爬虫爬不到吗
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了js的网页爬虫爬不到吗相关的知识,希望对你有一定的参考价值。
不是爬不到是因为用js生成的网页,是通过浏览器加载js代码之后,由js动态生成的。
用爬虫直接去抓网页的话,抓下来的是原始代码,浏览器还未解析过的内容。
纯 html 的话,抓下来可以直接拿来用,但是如果是由 js 动态生成的网页的话,就没办法直接用了。
像通过js动态加载的网页,理论上如果能用开源的浏览器内核将网页解析出来的话,通过浏览器内核提供的接口,完全可以把网页最终的 html 拿出来 参考技术A 爬不到,爬虫只认html
利用php加js实时爬取数据
一般我们做爬虫,都是用后端语言爬取数据之后存进数据库。
那我们前端是不是就不能玩爬虫了呢?NO,我们一起来看看这是什么奇技淫巧...
现在我们利用js来爬取,并实时使用这些数据,php仅仅把目标网页渲染后的html给转成字符串,并提供一个接口供我们调用以获取目标网页的html字符串。
至于为什么选php,那还用说吗,php不是世界上最好的语言吗?开玩笑的啦,不过php却是世界上部署最方便的后端语言,阿里云6块钱一年的虚拟主机丢进去就能跑起来。
先看一眼效果:
左边的是我写的,右边的是酷狗手机网页,除了换了层皮,是不是赶脚一毛一样?没错,数据全是爬取的,啦啦啦...
在线地址:http://www.xi-g.com/index
我们先新建一个php文件get_kugou.php:
<?php // 允许所有域访问header("Access-Control-Allow-Origin: *");// 接收一个参数,参数名叫url$url = $_GET['url'];// 酷狗的网址$crossUrl = 'http://m.kugou.com/'.$url;// 把这个网页读取后转成字符串$res = file_get_contents($crossUrl);// 输出这个字符串echo $res;?>http://www.xi-g.com/get_kugou.php
我们可以先访问一下,然后再加个参数访问:
http://www.xi-g.com/get_kugou.php?url=/plist/index
是不是很神奇,通过参数可以间接访问酷狗任何一个页面...
接下来我们看怎么换皮,首先我们当然得把静态页面写好呀,我这里只演示怎么抓取数据:
// 调个ajax$.ajax({
type:'get', url: 'http://www.xi-g.com/get_kugou.php', success: function(data) { // 打印看看是个什么玩意
console.log(data);
}
});打印一下:
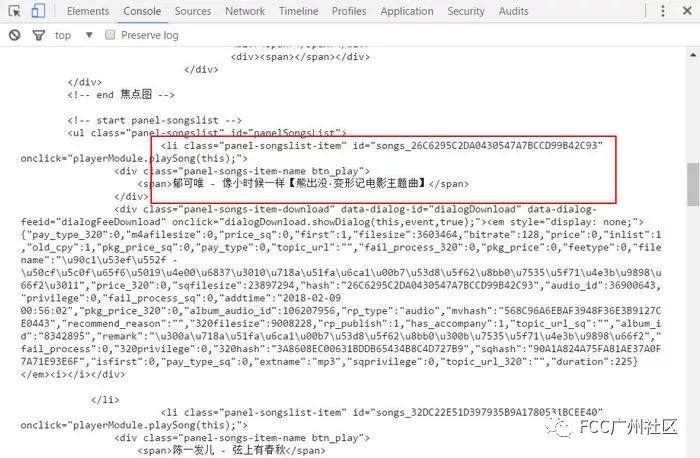
我们已经把整个酷狗首页的html字符串拿到了,接下来是重点,怎么提取数据:
$.ajax({
type:'get',
url: 'http://www.xi-g.com/get_kugou.php',
success: function(data) { // 创建一个div的盒子存起来
var div = document.createElement('div'); // 把整个html的字符串存到这个div节点里
div.innerHTML = data; // 分析html结构后,把类名为.panel-songslist-item的元素全部存到list变量里
// querySelectorAll()以数组形式返回所有匹配节点
var list = div.querySelectorAll('.panel-songslist-item'); // 定义一个空数组
var songList = []; // 遍历list提取歌单数据,整理格式
for(var i = 0; i<list.length; i++){ // 定义空对象
var song = {}; // 查找类名为.panel-songs-item-name的元素里的span节点里的文本存到song.title属性
song.title = list[i].querySelector('.panel-songs-item-name span').textContent; // 取到每个list元素的id值
song.hash = list[i].id.substr(6); // 把song对象推入songList数组
songList.push(song);
} // 我们来打印songList这个对象数组看看
console.log(songList);
}
});打印结果:
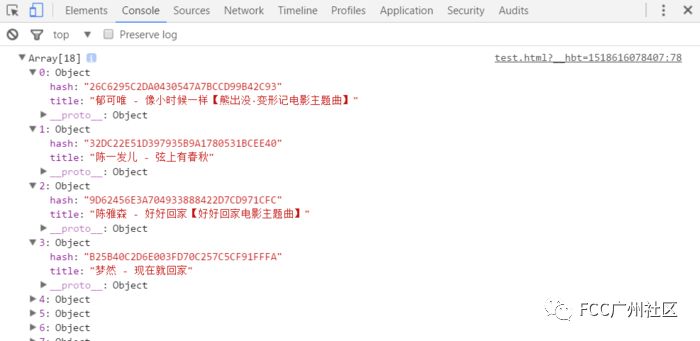
现在我们就把酷狗首页的歌单数据给拿到了,只要拿到数据就能构建我们的页面了,是不是十分神奇,关键点还是对querySelectorAll()和querySelector()这两个方法的运用,根据id名、class名、标签名来查找元素提取数据。
我们再来提取一下歌单页面的数据,还是老方法,但是需要仔细分析页面才能提取到我们想要的数据:
$.ajax({
type:"get",
url: "http://www.xi-g.com/get_kugou.php?url=plist/index",
success: function(data) { var div = document.createElement('div');
div.innerHTML = data; var list = div.querySelectorAll('.panel-img-list li'); var plistList = []; for(var i = 0; i<list.length; i++){ var plist = {};
plist.imgUrl = list[i].querySelector('.panel-img-left img').getAttribute('_src');
plist.plistName = list[i].querySelector('.panel-img-content-first').textContent;
plist.plistNum = list[i].querySelector('.panel-img-content-sub').textContent;
plist.location = "plist/list/"+list[i].querySelector('a').href.substr(30);
plistList.push(plist);
}
console.log(plistList);
}
});打印结果:
深圳新闻网:http://m.sznews.com/
每一条新闻都是带a标签链接的,根据这个链接我们可以进行二次爬取,即从列表页爬进详情页...
以上是关于js的网页爬虫爬不到吗的主要内容,如果未能解决你的问题,请参考以下文章