MyCAT 源码解析 —— 分片结果合并(使用unsaferow)
Posted qiumingcheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MyCAT 源码解析 —— 分片结果合并(使用unsaferow)相关的知识,希望对你有一定的参考价值。
??????关注微信公众号:【芋道源码】有福利:
- RocketMQ / MyCAT / Sharding-JDBC 所有源码分析文章列表
- RocketMQ / MyCAT / Sharding-JDBC 中文注释源码 GitHub 地址
- 您对于源码的疑问每条留言都将得到认真回复。甚至不知道如何读源码也可以请教噢。
- 新的源码解析文章实时收到通知。每周更新一篇左右。
- 认真的源码交流微信群。
1. 概述
相信很多同学看过 mysql 各种优化的文章,里面 99% 会提到:单表数据量大了,需要进行分片(水平拆分 or 垂直拆分)。分片之后,业务上必然面临的场景:跨分片的数据合并。今天我们就一起来瞅瞅 MyCAT 是如何实现分片结果合并。
跨分片查询大体流程如下:

和 《【单库单表】查询》 不同的两个过程:
- 【2】多分片执行 SQL
- 【4】合并多分片结果
下面,我们来逐条讲解这两个过程。
2. 多分片执行 SQL
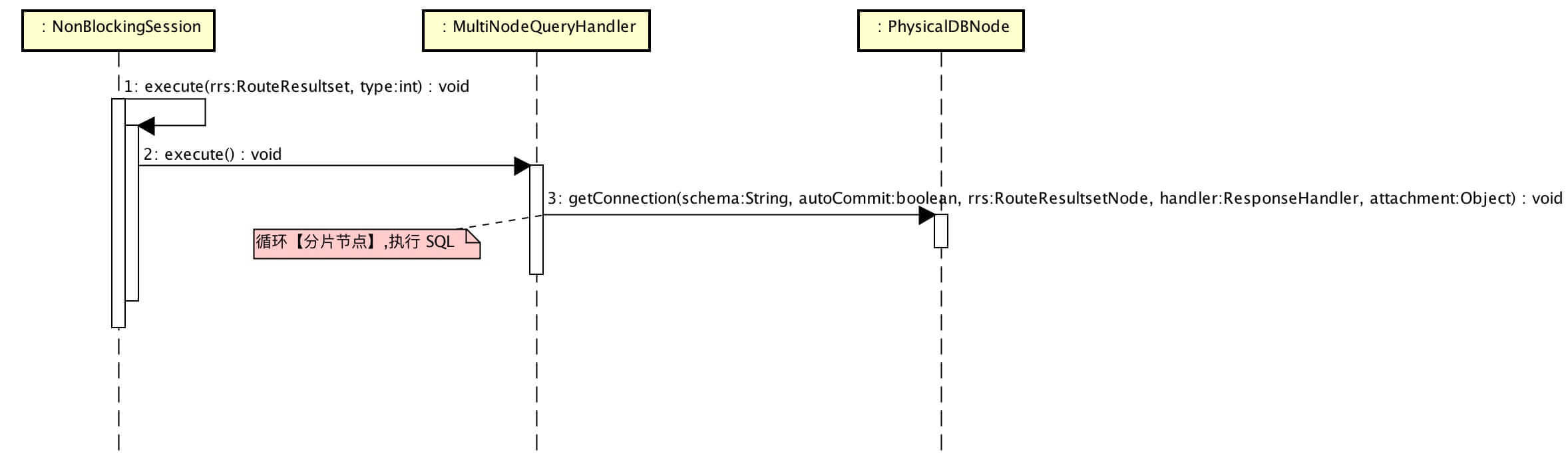
经过 SQL 解析后,计算出需要执行 SQL 的分片节点,遍历分片节点发送 SQL 进行执行。
核心代码:
SQL 解析 详细过程,我们另开文章,避免内容过多,影响大家对 分片结果合并 流程和逻辑的理解。
3. 合并多分片结果
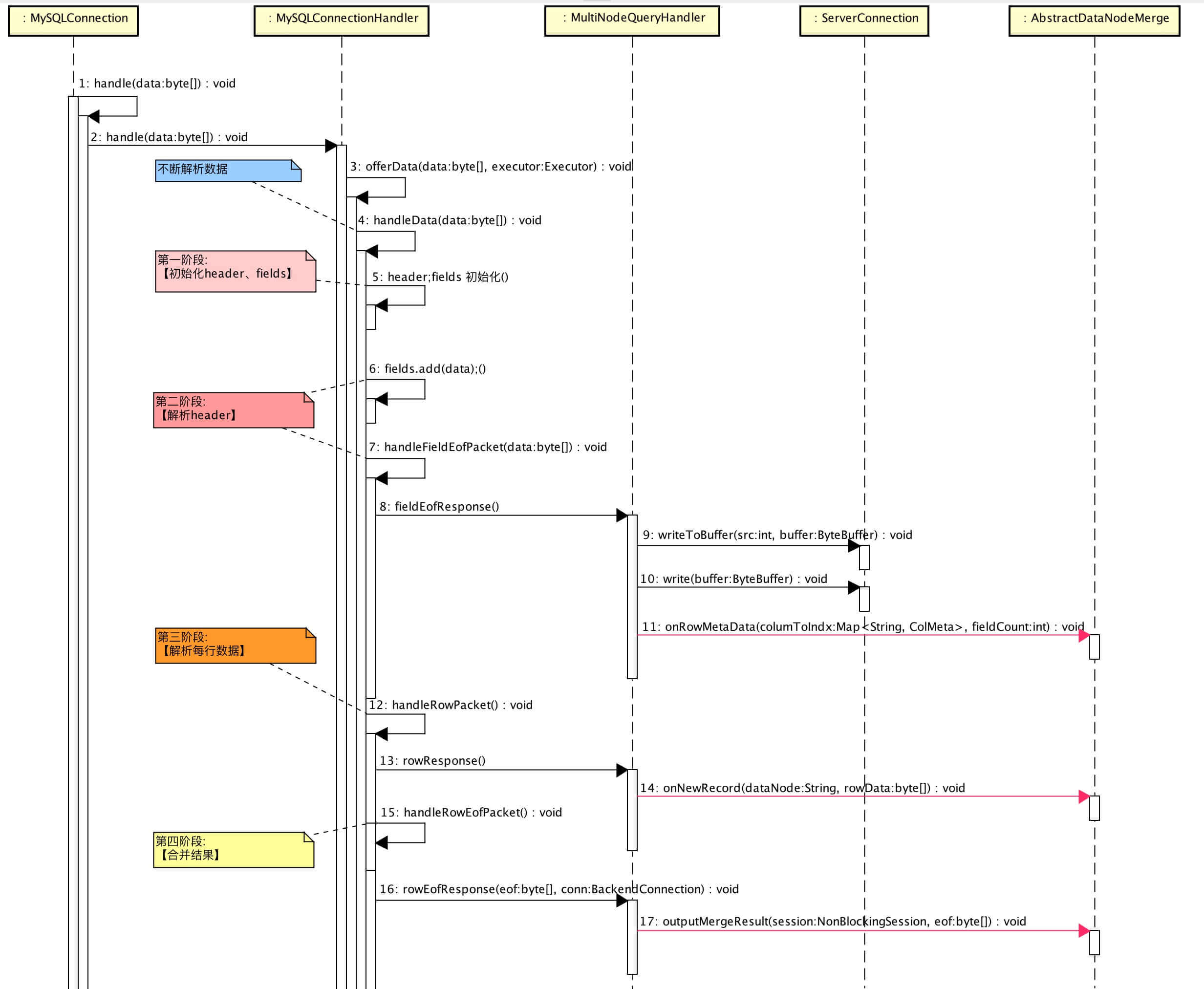
和 《【单库单表】查询》 不同,多个分片节点都会分别响应 记录头(header) 和 记录行(row) 。在开始分析 MyCAT 是怎么合并多分片结果之前,我们先来回想下 SQL 的执行顺序。
FROM // [1] 选择表
|
3.1 记录头(header)
多个分片节点响应时,会响应多次 记录头(header) 。MyCAT 在实际处理时,只处理第一个返回的 记录头(header) 。因此,在使用时要保证表的 Schema 相同。
分片节点响应的 记录头(header) 可以直接返回 MySQL Client 吗?答案是不可以。AVG函数 是特殊情况,MyCAT 需要将 AVG 拆成 SUM + COUNT 进行计算。举个例子:
// [1] MySQL Client => MyCAT :
|
核心代码:
3.2 记录行(row)
3.1 AbstractDataNodeMerge
MyCAT 对分片结果合并通过 AbstractDataNodeMerge 子类来完成。

AbstractDataNodeMerge :
- -packs :待合并记录行(row)队列。队列尾部插入
END_FLAG_PACK表示队列已结束。 - -running :合并逻辑是否正在执行中的标记。
- ~onRowMetaData(…) :根据记录列信息(ColMeta)构建对应的排序组件和聚合组件。需要子类进行实现。
- ~onNewRecord(…) :插入记录行(row) 到
packs。 - ~outputMergeResult(…) :插入
END_FLAG_PACK到packs。 - ~run(…) :执行合并分片结果逻辑,并将合并结果返回给 MySQL Client。需要子类进行实现。
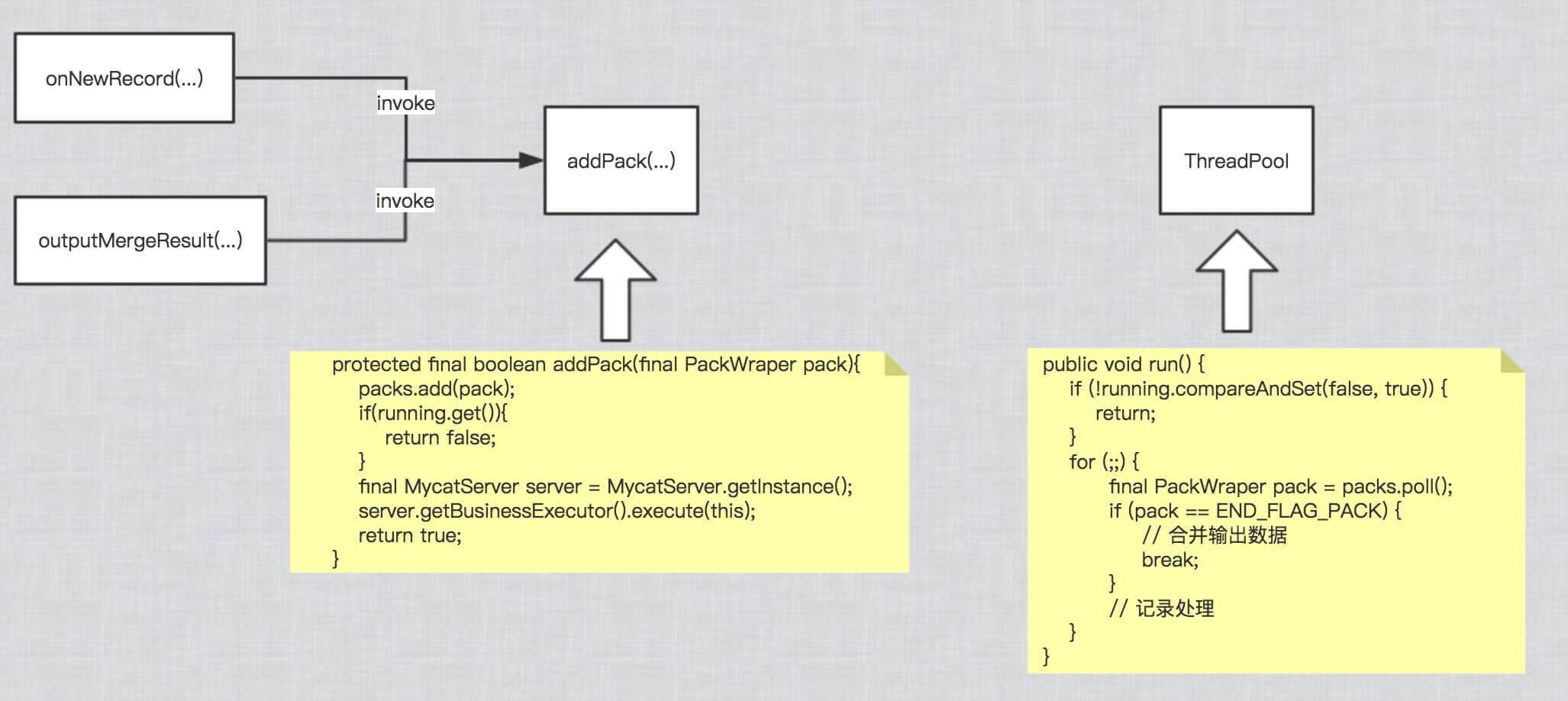
通过 running 标记保证同一条 SQL 同时只有一个线程正在执行,并且不需要等到每个分片结果都返回就可以执行聚合逻辑。当然,排序逻辑需要等到所有分片结果都返回才可以执行。
核心代码:
3.2 DataNodeMergeManager
AbstractDataNodeMerge 有两种子类实现:
DataMergeService:基于堆内内存合并分片结果。DataNodeMergeManager:基于堆外内存合并分片结果。
目前官方默认配置使用 DataNodeMergeManager。主要有如下优点:
- 可以使用更大的内存空间。当并发量大或者数据量大时,更大的内存空间意味着更好的性能。
- 减少 GC 暂停时间。记录行(row)对象小且重用性很低,需要能够进行类似 C / C++ 的自主内存释放。
- 更快的内存复制和读取速度,对排序和聚合带来很好的提速。
如果对堆外内存不太了解,推荐阅读如下文章:
本文主要分析 DataNodeMergeManager 实现,DataMergeService 可以自己阅读或者等待后续文章(??欢迎订阅我的公众号噢)。
DataNodeMergeManager 有三个组件:
globalSorter:UnsafeExternalRowSorter=> 实现记录行(row)合并并排序逻辑。globalMergeResult:UnsafeExternalRowSorter=> 实现记录行(row)合并不排序逻辑。unsafeRowGrouper:UnsafeRowGrouper=> 实现记录行(row)聚合逻辑。
DataNodeMergeManager#run(...) 逻辑如下:
- [1] 写入记录行(row)到
UnsafeRow。 - [2] 根据情况将
UnsafeRow插入对应组件。 - [3] 当所有
UnsafeRow插入完后,根据情况使用组件聚合、排序。
| 是否排序 | 是否聚合 | 依赖组件 | [2] | [3] |
|---|---|---|---|---|
| 否 | 否 | globalSorter |
插入 globalSorter |
使用 globalSorter 合并并排序 |
| 是 | 否 | globalMergeResult |
插入 globalMergeResult |
使用 globalMergeResult 合并不排序 |
| 否 | 是 | unsafeRowGrouper + globalSorter |
插入 unsafeRowGrouper 进行聚合 |
使用 globalSorter 合并并排序 |
| 是 | 是 | unsafeRowGrouper + globalMergeResult |
插入 unsafeRowGrouper 进行聚合 |
使用 globalMergeResult 合并不排序 |
核心代码:
??看到这里,可能很多同学都有点懵逼,问题不大,我们继续往下瞅。
3.3 UnsafeRow

记录行(row)写到 UnsafeRow 的 baseObject 属性,结构如下:

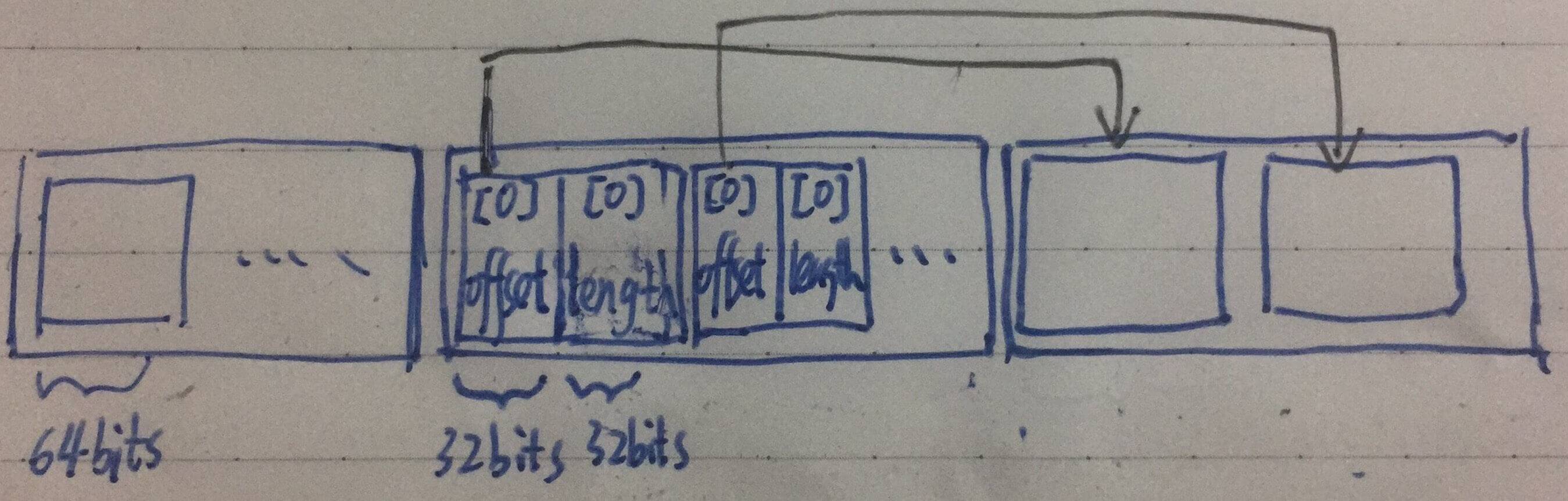
- 拆分成三个区域,每个区域按照格子记录信息,每个格子 64bits(8 Bytes)。
- 记录行(row)按照字段顺序位置记录到
baseObject。 - [1] 空标记位区域 :标记字段对应的值是否为 NULL。
- 当字段对应的值为 NULL 时,其对应的字段顺序对应的 bit 设置为 1。举个例子,第 0 个位置字段为 NULL,则第一个格子对应的 64 bits 从右边第一个 bit 设置为 1。
- 因为每个格子是 64 bits,每 64 个字段占用一个格子,不满一个格子,按照一个格子计算。因此,该区域的长度(
bitSetWidthInBytes) = 字段占用的格子数 * 64 bits。
- [2] 位置长度区域 :记录字段对应的值在
[3]区域所在的位置和长度。- 每个字段记录
[2]区域的位置 =baseOffset+bitSetWidthInBytes+ 8 Bytes * 字段顺序。 - 占用一个格子,前 32 bits 为
[3]区域的位置,后 32 bits 为字段对应的值长度。
- 每个字段记录
- [3] 值区域 :记录字段对应的值。
- 每个字段对应的值占用格子数 = 字段对应的值长度 / 8 Byte,如果无法整除再 + 1。
- 因为字段对应的值可能无法刚好占满每个格子,未使用的 bit 用 0 占位。
写入 UnsafeRow,MyCAT 可以顺序访问每个字段,而不需要在记录行(row)进行遍历。
??日常开发使用位操作的机会比较少,可能较为难理解,需要反复理解下,相信会获得很大启发。恩,该部分代码引用自开源运算框架 Spark,是不是更加有动力列??。
核心代码:
3.4 UnsafeExternalRowSorter
如果使用 Java 实现 SELECT * FROM student ORDER BY age desc, nickname asc,不考虑算法优化的情况下,我们可以简单如下实现:
Collections.sort(students, new Comparator<Comparable>() {
|
从功能上,UnsafeExternalRowSorter 是这么实现排序逻辑。当然肯定的是,不是这么“简单”的实现。

UnsafeRow 会写入到两个地方:
List<MemoryBlock>:内存块数组。当前MemoryBlock无法容纳写入的UnsafeRow时,生成新的MemoryBlock提供写入。每条UnsafeRow存储在MemoryBlock由 长度 + 字节内容 组成。LongArray:每条UnsafeRow存储在LongArray由两部分组成:address + prefix。address:UnsafeRow存储在List<MemoryBlock>的位置。前 13 bits 记录所在MemoryBlock的 index,后 51 bit 记录在MemoryBlock的 offset。prefix:UnsafeRow第一个排序字段值前 64 bits 计算的值。
UnsafeExternalRowSorter 排序实现方式 :提供 TimSort 和 RadixSort 两种排序算法,前者为默认实现。TimSort 折半查找时,使用 LongArray,先比较 prefix,若相等,则顺序对比每个排序字段直到不等,提升计算效率。插入操作在 LongArray 操作,List<MemoryBlock> 只作为原始数据。
另外,当需要排序特别大的数据量时,会使用存储数据到文件进行排序。限于笔者暂时未阅读该处源码,后续会另开文章分析。??
核心源码:
3.5 UnsafeRowGrouper
如果使用 Java 实现 SELECT nickname, COUNT(*) FROM student group by nickname,不考虑算法优化的情况下,我们可以简单如下实现:
Map<String, List<Object>> map = new HashMap<>();
|
从功能上,UnsafeRowGrouper 是这么实现排序逻辑。当然肯定的是,也不是这么“简单”的实现。
??具体怎么实现的呢?我们在《MyCAT 源码解析 —— 分片结果合并(二)》继续分析。
以上是关于MyCAT 源码解析 —— 分片结果合并(使用unsaferow)的主要内容,如果未能解决你的问题,请参考以下文章