Mycat核心概念工作原理及高级特性分析
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mycat核心概念工作原理及高级特性分析相关的知识,希望对你有一定的参考价值。
海量数据存储解决方案之分库分表原理解析及mycat安装及使用_踩踩踩从踩的博客-CSDN博客
前言
上篇文章主要对海量数据的分片进行介绍,并且包括mycat的安装和简单使用,做了一个简单的配置,也对分片中会出现的问题做分析;这篇文章会接着继续进行分析数据库中间件中重要的mycat,在使用上有一些高级特性及核心概念、分片解决的办法做了哪些优化和处理大的介绍
核心概念理解和工作原理
mycat的版本迭代
- Mycat-mini-monitor项目开源了,又一款Mycat监控!
- Mycat-mini-monitor-1.0.0 版本发布
- Mycat-server-1.6.6-release 版本发布
- Mycat-server-1.6.6-test 版本发布
- Mycat-server-1.6-release 版本发布
- Mycat-server-1.5-release 版本发布
- Mycat-server-1.4-release 版本发布
- Mycat-server-1.3-release 版本发布
- Mycat-web(eye) 版本发布
Mycat工作原理
- 将订单表 orders 数据按省份分片;
- 应用连接mycat,提交SQL;
- Mycat ‚拦截‛
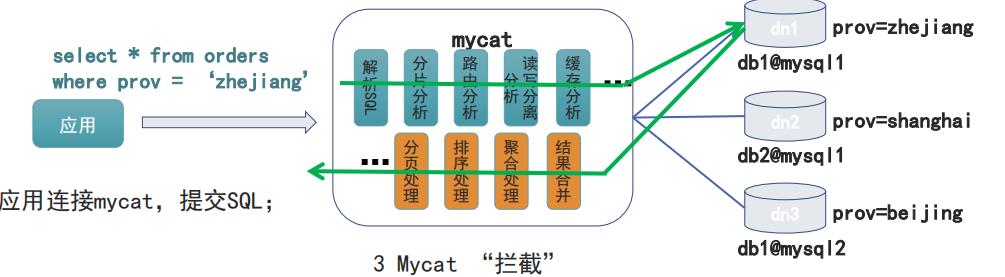
架构
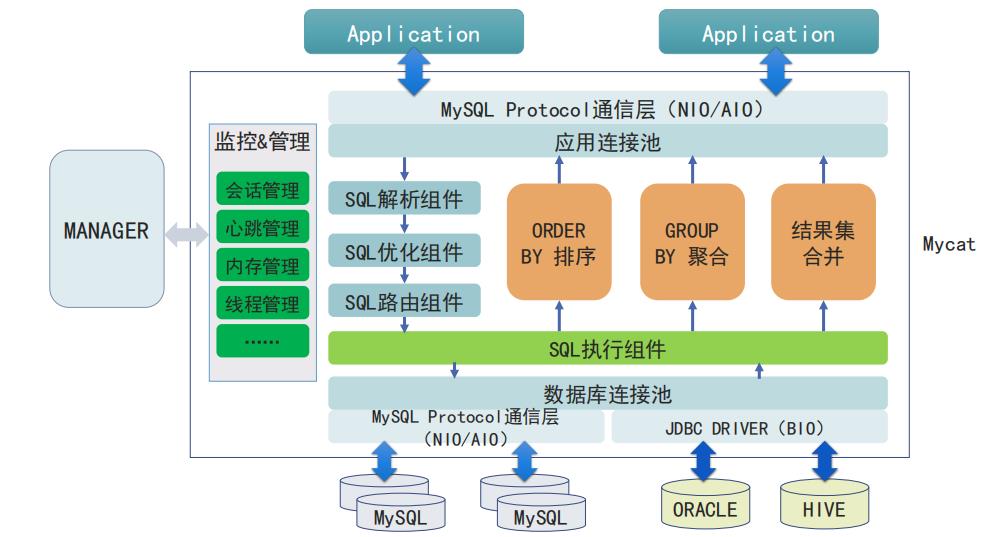
连接mycat 利用mysql的连接包,基于mysql协议包,sql执行组件。 对于mysql 不适用jdbc进行连接,如果其他的数据库,使用的jdbc的数据库,并发能力也好,还是其他的特殊的支持等都不是很好。
核心概念
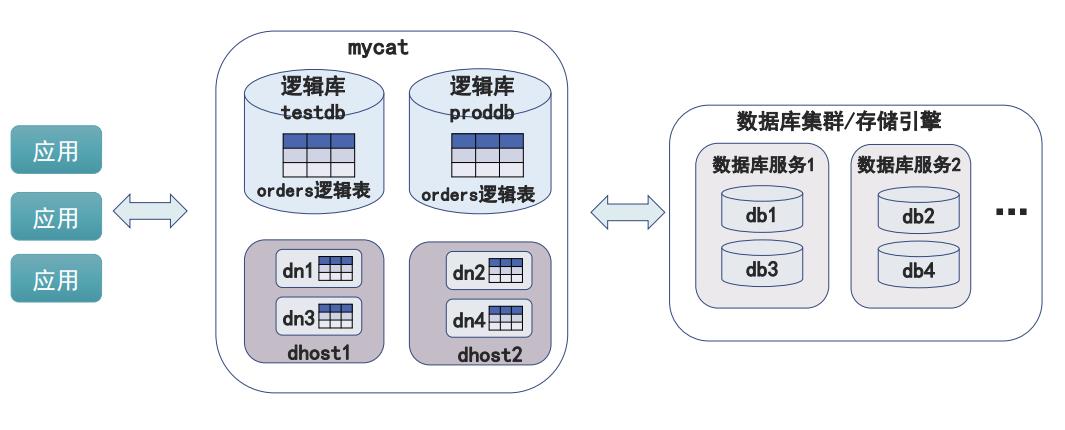
应用层访问数据库,依次会找到下面的 对应的配置
- 逻辑库:mycat数据库服务中定义、管理的数据库

- 逻辑表:逻辑库中包含的需分库分表存储的表
- dataNode:数据节点(分片节点),逻辑表分片的存放节点。这里的datanode 对应的数据节点。
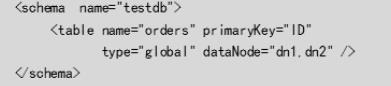
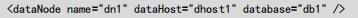
- dataHost: 数据主机(节点主机),数据节点所在的主机。
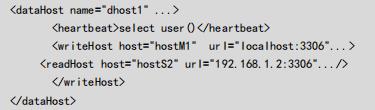
- writeHost:写主机,真实的数据库服务主机描述

- readHost:读主机,真实的数据库服务主机描述

schema配置-schema
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
</schema>
</mycat:schema>schema元素属性说明
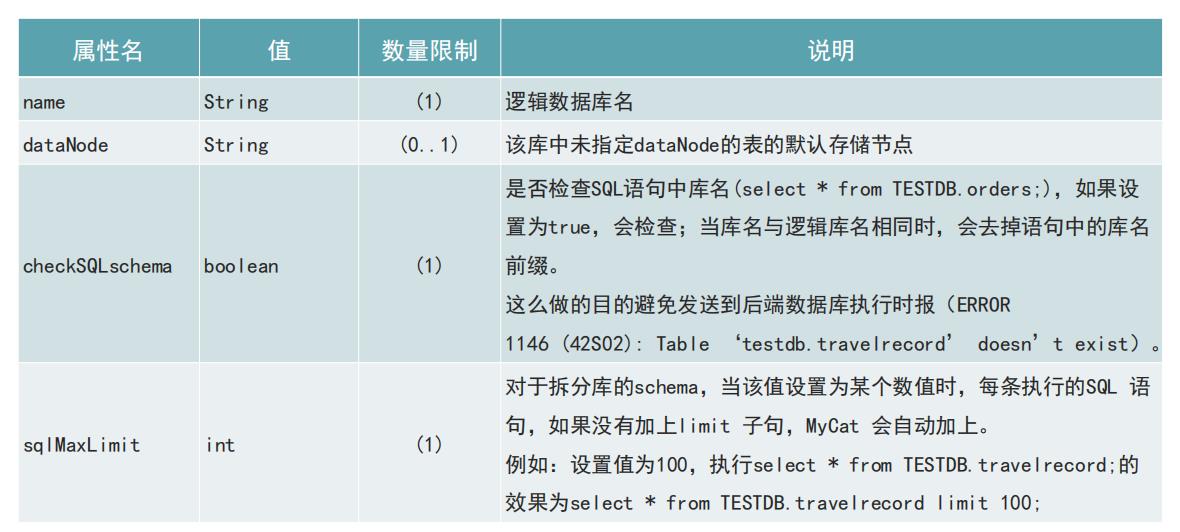
checkSQLschema 需要设置为true ,当库名与逻辑库名相同时,会去掉语句中的库名前缀。
这个在实际应用中一般都加上的。
schema配置-table
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id">
<childTable name="order_items" joinKey="order_id" parentKey="id" />
</childTable>
</table>
</schema>
这其中,
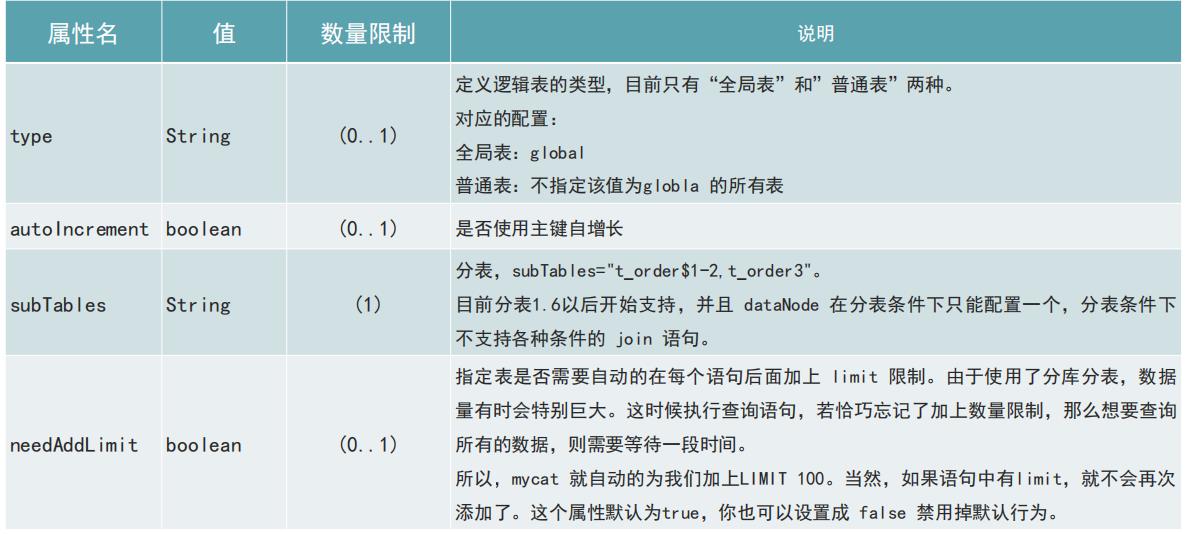
- name :表名,同个schema 标签中定义的名字必须唯一,存放表数据的数据节点名。
- dataNode
- primaryKey 用来做缓存的。
schema配置-childTable标签
<table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id">
<childTable name="order_items" joinKey="order_id" parentKey="id" />
</childTable>
</table>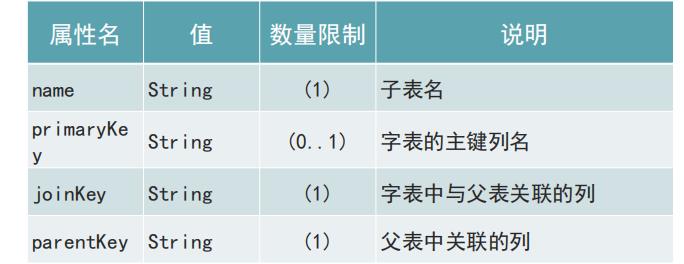
schema配置-dataHost
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />
</writeHost>
</dataHost>
这些对应不配置都有默认的。

schema配置-heartbeat
<heartbeat>select user()</heartbeat>- 这个标签内指明用于和后端数据库进行心跳检查的语句 如:MYSQL 可以使用select user(),Oracle 可以使用select 1 from dual 等。
- 这个标签还有一个connectionInitSql 属性,主要是当使用Oracle数据库时,需要执行的初始化SQL 语句就放到这里。 如:alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'
- 主从切换的语句必须是:show slave status
schema配置-writeHost readHost
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />
</writeHost>
java -cp Mycat-server-1.4.1-dev.jar io.mycat.util.DecryptUtil 1:host:user:passwordMycat-server-1.4.1-dev.jar 为mycat download 下载目录的jar1:host:user:password 中1 为db 端加密标志,host 为dataHost 的host 名称
Mycat如何解决分库分表带来的挑战
解决原则
Mycat中表分类
分片表
<table name="t_goods" primaryKey="vid" autoIncrement="true" dataNode="dn1,dn2" rule="rule1" />非分片表
<table name="t_node" primaryKey="vid" autoIncrement="true" dataNode="dn1" />ER表
<table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id">
<childTable name="order_items" joinKey="order_id" parentKey="id" />
</childTable>
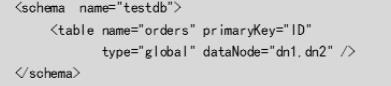
</table>全局表
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />也是解决效率慢,一定要数据量小,不然会导致占用空间大。
分片规则
在conf/rule.xml中定义分片规则

- name 属性指定唯一的名字,用于标识不同的表规则。
- 内嵌的rule 标签则指定对物理表中的哪一列进行拆分和使用什么路由算法。

- name 指定算法的名字。
- class 制定路由算法具体的类名字。
- property 为具体算法需要用到的一些属性。
Mycat内置的常用分片规则
分片枚举(列表分片)
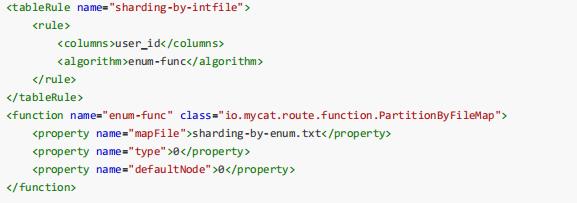
- 算法实现类为:io.mycat.route.function.PartitionByFileMap
- mapFile 标识配置文件名称;
- type 默认值为0,0 表示Integer,非零表示String;
- defaultNode defaultNode 默认节点:小于0 表示不设置默认节点,大于等于0 表示设置默认节点为第几个数 据节点。
- 默认节点的作用:枚举分片时,如果碰到不识别的枚举值,就让它路由到默认节点 如果不配置默认节点 (defaultNode 值小于0 表示不配置默认节点),碰到不识别的枚举值就会报错。
like this:can’t find datanode for sharding column:column_name val:ffffffff- sharding-by-enum.txt 放置在conf/下,配置内容示例:
10000=0 # 字段值为 10000 的放到 0 号数据节点10010=1
范围分片
此分片适用于,提前规划好分片字段某个范围属于哪个分片

- mapFile 代表配置文件路径
- defaultNode 超过范围后的默认节点。
start <= range <= end.
range start-end=data node index
K=1000,M=10000.0-500M=0
500M-1000M=1
1000M-1500M=2按日期范围分片

- columns :标识将要分片的表字段
- algorithm :分片函数
- dateFormat :日期格式
- sBeginDate :开始日期
- sEndDate:结束日期
- sPartionDay :分区天数,即默认从开始日期算起,分隔10 天一个分区
- sBeginDate,sEndDate 都有指定 此时表的dataNode 数量的>=这个时间段算出的分片数,否则启动时会异常:

- 没有指定 sEndDate 的情况 数据分片将依次存储到dataNode上,数据分片随时间增长,所需的dataNode数也随之增长,当超出了为该表配置的dataNode数时,将得到如下异常信息:

自然月分片
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-month</algorithm>
</rule>
</tableRule>
<function name="sharding-by-month" class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2014-01-01</property>
</function>- columns: 分片字段,字符串类型
- dateFormat : 日期字符串格式,默认为yyyy-MM-dd
- sBeginDate : 开始日期,无默认值
- sEndDate:结束日期,无默认值
- 节点从0 开始分片
节点数量必须是12 个,对应1 月~12 月
- "2017-01-01" = 节点0
- "2018-01-01" = 节点0
- "2018-05-01" = 节点4
- "2019-12-01" = 节点11
- sBeginDate = "2017-01-01" 该配置表示"2017-01 月"是第0 个节点,从该时间按月递增,无最大节点
- "2014-01-01" = 未找到节点
- "2017-01-01" = 节点0
- "2017-12-01" = 节点11
- "2018-01-01" = 节点12
- "2018-12-01" = 节点23
- sBeginDate = "2015-01-01" sEndDate = "2015-12-01" 该配置可看成与场景1 一致。
- "2014-01-01" = 节点0
- "2014-02-01" = 节点1
- "2015-02-01" = 节点1
- "2017-01-01" = 节点0
- "2017-12-01" = 节点11
- "2018-12-01" = 节点11
取模
<tableRule name="mod-sharding">
<rule>
<columns>user_id</columns>
<algorithm>mod-fun</algorithm>
</rule>
</tableRule>
<function name="mod-fun" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>取模范围分片
<tableRule name="sharding-by-pattern">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-pattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-pattern" class="io.mycat.route.function.PartitionByPattern">
<property name="patternValue">256</property>
<property name="defaultNode">2</property>
<property name="mapFile">partition-pattern.txt</property>
</function>1-32=0 #余数为1-32的放到数据节点0上
33-64=1
65-96=2
97-128=3
129-160=4
161-192=5
193-224=6
225-256=7
0-0=7- patternValue 即求模基数
- defaoultNode 默认节点,如果配置了默认节点,如果id 非数据,则会分配在defaoultNode 默认节点
- mapFile 指定余数范围分片配置文件
二进制取模范围分片
<tableRule name="rule1">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">2,1</property>
<property name="partitionLength">256,512</property>
</function>- partitionCount 分片个数列表。
- partitionLength 分片范围列表
- count,length 两个数组的长度必须是一致的。
- 1024 = sum((count[i] * length[i])),count 和length 两个向量的点积恒等于1024
范围取模分片
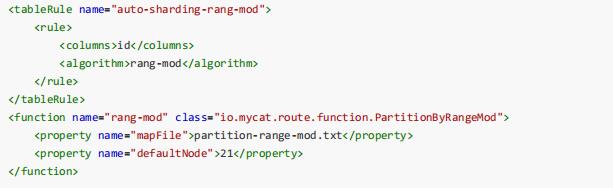
- mapFile 配置文件路径
- defaultNode 超过范围后的默认节点顺序号,节点从0 开始。
- partition-range-mod.txt 以下配置一个范围代表一个分片组,=号后面的数字代表该分片组所拥有的分片的数量。

一致性hash
<tableRule name="sharding-by-murmur">
<rule>
<columns>user_id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<!-- 默认是0-->
<property name="seed">0</property>
<!-- 要分片的数据库节点数量,必须指定,否则没法分片-->
<property name="count">2</property>
<!-- 一个实际的数据库节点被映射为多少个虚拟节点,默认是160 -->
<property name="virtualBucketTimes">160</property>
<!-- <property name="weightMapFile">weightMapFile</property>
节点的权重,没有指定权重的节点默认是1。以properties 文件的格式填写,以从0 开始到count-1 的整数值也 就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1 代替-->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property> 用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash 值与物理 节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西-->
</function>应用指定
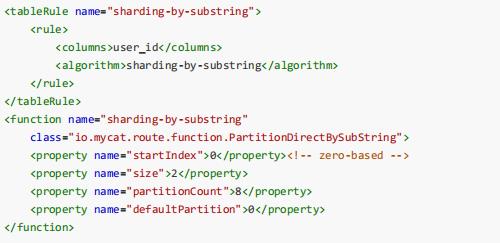
截取字符ASCII求和求模范围分片


- patternValue 即求模基数,
- prefifixLength ASCII 截取的位数,求这几位字符的ASCII码值的和,再求余patternValue
- mapFile 配置文件路径,配置文件中配置余数范围分片规则。
主键值生成
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。
为此,MyCat 提供了全局sequence,并且提供了包含本地配置和数据库配置等多种实现方式。
本地文件方式
GLOBAL.HISIDS=
GLOBAL.MINID=1001
GLOBAL.MAXID=1000000000
GLOBAL.CURID=1000<system><property name="sequnceHandlerType">0</property></system>insert into table1(id,name) values(next value for MYCATSEQ_GLOBAL,‘test’);T_COMPANY.CURID=501
T_COMPANY.MINID=1
T_COMPANY.MAXID=1000000000就可以使用了。
<table name="t_company" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="range-sharding-by-members-count" />数据库方式
- 1. 当初次使用该sequence 时,根据传入的sequence 名称,从数据库这张表中读取current_value,和 increment 到MyCat 中,并将数据库中的current_value 设置为原current_value 值+increment 值。
- 2. MyCat 将读取到current_value+increment 作为本次要使用的sequence 值,下次使用时,自动加1,当使用increment 次后,执行步骤1)相同的操作。
<system><property name="sequnceHandlerType">1</property></system>- 创建MYCAT_SEQUENCE 表

- 创建相关function

- sequence_db_conf.properties 相关配置,指定sequence 相关配置在哪个节点上:
USER_SEQ=test_dn1insert into table1(id,name) values(next value for MYCATSEQ_GLOBAL,'test');INSERT INTO MYCAT_SEQUENCE(name,current_value,increment) VALUES ('T_COMPANY', 1,100);T_COMPANY=dn1<table name="t_company" primaryKey以上是关于Mycat核心概念工作原理及高级特性分析的主要内容,如果未能解决你的问题,请参考以下文章