4 基于概率论的分类方法:朴素贝叶斯
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4 基于概率论的分类方法:朴素贝叶斯相关的知识,希望对你有一定的参考价值。
4.7 示例:使用朴素贝叶斯分类器从个人广告中获取区域倾向
前面介绍了两个应用:1.过滤网站的恶意留言;2.过滤垃圾邮件。
4.7.1 收集数据:导入RSS源
Universal Feed Parser是Python中最常用的RSS程序库。
在Python提示符下输入:


构建类似于spamTest()函数来对测试过程自动化。
#RSS源分类器及高频词去除函数 def calcMostFreg(vocabList, fullText): import operator freqDict = {} for token in vocabList:#遍历词汇表中的每个词,统计它在文本中出现的次数 freqDict[token] = fullText.count(token) sortedFreq = sorted(freqDict.iteritems(), key = operator.itemgetter(1), reverse = True) return sortedFreq[:30]#返回排序最高的30个单词 def localWords(feed1, feed0): import feedparser docList = []; classList = []; fullText = [] minLen = min(len(feed1[‘entries‘]), len(feed0[‘entries‘])) for i in range(minLen):#每次访问一条RSS源 wordList = textParse(feed1[‘entries‘][i][‘summary‘]) docList.append(wordList) fullText.extend(wordList) classList.append(1) wordList = textParse(feed0[‘entries‘][i][‘summary‘]) docList.append(wordList) fullText.extend(wordList) classList.append(0) vocabList = createVocabList(docList) #去掉出现次数最高的那些词 top30Words = calcMostFreg(vocabList, fullText) for pairW in top30Words: if pairW[0] in vocabList: vocabList.remove(pairW[0]) trainingSet = range(2 * minLen); testSet = [] for i in range(20):#随机抽取20个文件作为testSet randIndex = int(random.uniform(0, len(trainingSet))) testSet.append(trainingSet[randIndex]) del(trainingSet[randIndex]) trainMat = []; trainClasses = [] for docIndex in trainingSet: trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) trainClasses.append(classList[docIndex]) p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses)) errorCount = 0 for docIndex in testSet: wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]) if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: errorCount += 1 print ‘the error rate is: ‘, float(errorCount)/len(testSet) return vocabList, p0V, p1V

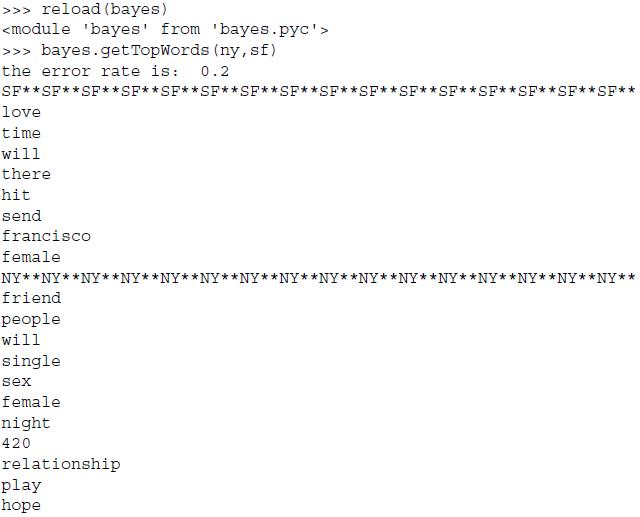
4.7.2 分析数据:显示地域相关的用词
#最具表特征的词汇显示函数 def getTopWords(ny, sf): import operator vocabList, p0V, p1V = locablWords(ny, sf) topNY = []; topSF = []#创建列表用于元祖的存储 for i in range(len(p0V)): if p0V[i] > -6.0:topSF.append((vocabList[i], p0V[i])) if p1V[i] > -6.0:topNY.append((vocabList[i], p1V[i])) sortedSF = sorted(topSF, key = lambda pair: pair[1], reverse = True) print "SF**SF**SF**SF**SF**SF**SF**SF**" for item in sortedSF: print item[0] sortedNY = sorted(topNY, key = lambda pair: pair[1], reverse = True) print "NY**NY**NY**NY**NY**NY**NY**NY**" for item in sortedNY: print item[0]
以上是关于4 基于概率论的分类方法:朴素贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章