朴素贝叶斯分类垃圾短信和R实现
Posted SimonCat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯分类垃圾短信和R实现相关的知识,希望对你有一定的参考价值。
以下为<机器学习与R语言>的学习笔记,如果需要文中提及的代码和数据,可以加我微信。
朴素贝叶斯算法思想起源18世纪数学家托马斯.贝叶斯(Thomas Bayes),基于贝叶斯定理和特征条件独立假设的分类方法,它通过特征计算分类的概率,选取概率大的情况,是基于概率论的一种机器学习分类(监督学习)方法。
1 贝叶斯方法的名词解释
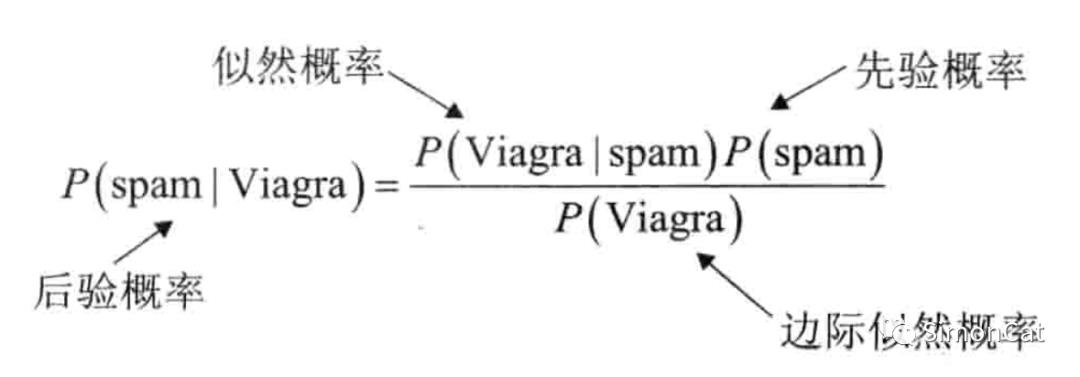
联合概率: 联合概率指的是包含多个条件且所有条件同时成立的概率,记作P(X=a,Y=b)或P(a,b),有的书上也习惯记作P(ab)。
边缘概率:边缘概率是与联合概率对应的,P(X=a)或P(Y=b),这类仅与单个随机变量有关的概率称为边缘概率
条件概率:条件概率表示在条件Y=b成立的情况下,X=a的概率,记作P(X=a|Y=b)或P(a|b)
先验概率:知道原因推结果
后验概率:知道结果推原因
拉普斯估计:给频率表上每个计数加上一个较小的数字,从而保证每一类中每一个特征发生的概率是非零的。
2 朴素贝叶斯的优势
优点:简单、快速、有效;能处理噪音和缺失值;需要训练的例子少;很容易获得一个预测的估计概率值;
缺点:依赖常用的错误假设。大量特征值并不理想。所有的特征都具有相同的重要性和独立性,然而实际上很难成立的。
3 实战:垃圾短信的识别
测试数据集包含5559条短信,第一列表示特征,表示其是否是垃圾短信,spam垃圾短信,而ham则表示不是。文本第二列为短信文字内容。如果是垃圾短信的概率大于非垃圾短信,则将其分为垃圾短信。
3.1 数据获取
使用str()查看文本结构,将是否垃圾短信变量转化为因子,使用table查看骚扰短信和非骚扰短信的条数。
setwd("/Users/tin/Learn/机器学习/1机器学习/Chapter 04")
# read the sms data into the sms data frame
sms_raw <- read.csv("sms_spam.csv", stringsAsFactors = FALSE)
# examine the structure of the sms data
str(sms_raw)
# convert spam/ham to factor.
sms_raw$type <- factor(sms_raw$type)
# examine the type variable more carefully
str(sms_raw$type)
table(sms_raw$type)
ham spam
4812 747
以上是关于朴素贝叶斯分类垃圾短信和R实现的主要内容,如果未能解决你的问题,请参考以下文章