分布式文件系统以及对相关节点的简单理解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式文件系统以及对相关节点的简单理解相关的知识,希望对你有一定的参考价值。
Distributed File System
1.数据量越来越多,在一个操作系统管辖的范围存储不下来,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,分布式文件系统由此产生。
2.它是一种允许文件通过网络在多台主机上分享的文件系统,可以让多台机器上的用户分享文件和存储空间。
3.通透性,让实际上是通过网络来访问文件的动作,由程序与用户看来,就像访问本地的磁盘一般。
4.容错性,即使系统中有些节点脱机,整体来说系统任然可以持续运作而不会有数据损失。
5.分布式文件管理系统有很多,HDFS只是其中的一种,HDFS适用于一次写入多次查询的情况,不支持并发写入的情况,对小文件的操作也不太适合。
HDFS:Hadoop Distributed File System 分布式文件系统。
HDFS的架构:
主从式结构
主节点,只有一个:NameNode
从节点,有很多歌:DataNode
NameNode是整个文件系统的管理节点。它维护着整个问加你系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
和NameNode相关的文件包括:
1.fsimage:元数据镜像文件,存储某一段时间NameNode内存元数据信息。
2.edits:操作日志文件。
3.fstime:保存最近一次checkpoint的时间。
注:
1.NameNode在内存中保存metadata,这样可以快速的处理客户端对数据的"读请求",但是内存中的数据容易丢失,例如掉电事,所以我们必须在磁盘上有metadata的副本。
2.当有"写请求"到来时,即要改变hadoop的文件系统时,NameNode会首先写editlog并主动同步到磁盘,成功后才会修改内存中的metadata,并且返回相应的信息给客户端,客户端再根据信息将数据写到对应的DataNode中。
3.fsimage是NameNode中metadata的镜像,fsimage不会随时与NameNode中的metadata保持一致,而是每隔一段时间合并editlog中的内容来更新,由于合并的过程比较消耗内存和CPU,所有hadoop就是用SecondaryNameNode专门用于更新fsimage文件。
以上文件都保存在Linux的文件系统中,目录为${hadoop.tmp.dir}/dfs/name/current中。
DataNode提供真实文件数据的存储服务。
1.文件块(block):最基本的存储单位,对于文件内容而言,一个文件的大小是size,那么从文件的0偏移量开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称为一个block,HDFS默认的block大小是64MB,以一个256MB的文件来说,共有256/64=4个block。
2.不同于普通文件系统的是,HDFS中,如果一个文件小于数据块的大小,并不占用整个数据块存储空间,而是占用文件实际大小的空间。
3.replication 是副本,在hdfs-site.xml文件中通过dfs.replication属性进行设置。
注:真实数据保存在${hadoop.tmp.dir}/dfs/data/current目录中。
SecondaryNameNode
1.是HA的一个解决方案,但不支持热备。配置即可。
2.执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits。
3.默认安装在NameNode节点上,但是建议单独设置一个节点。
4.secondaryNameNode的工作通过实践或者大小进行触发,在core-default.xml文件中可以找到配置。
SecondaryNameNode的工作原理图如下:
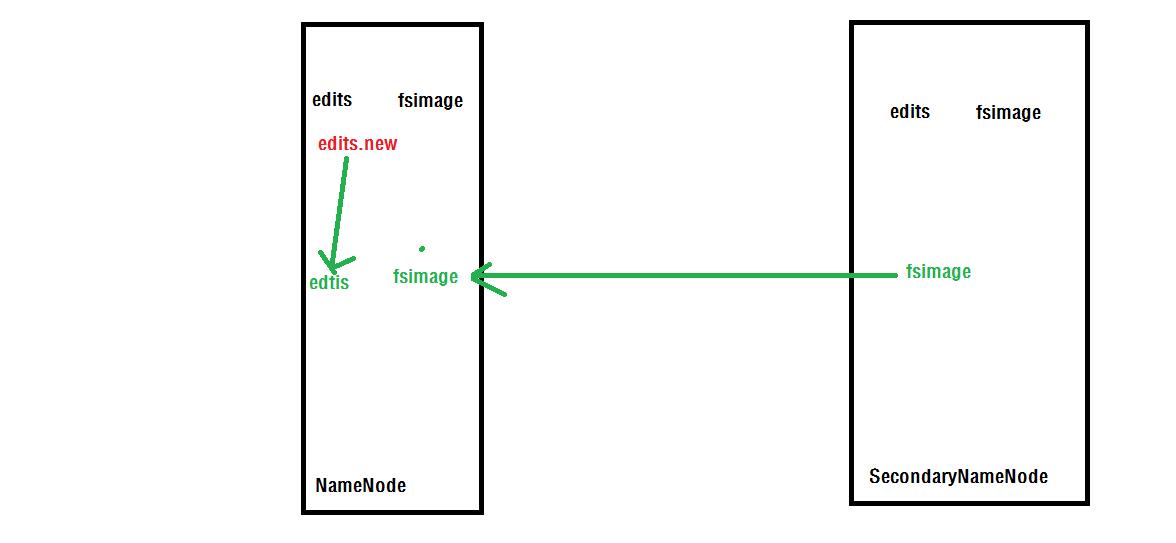
SecondaryNameNode详细工作流程:
1.SecondaryNameNode通知PrimaryNameNode切换editlog。
2.SecondaryNameNode通过HTTP协议从PrimaryNameNode获得fsimage和editlog。
3.SecondaryNameNode将fsimage载入内存,然后开始合并editlog的操作。
4.SecondaryNameNode将合并后的新数据的fsimage发给PrimaryNameNode。
5.PrimaryNameNode收到SecondaryNameNode发过来的新的fsimage后会用新的fsimage替换旧的fsimage。
SecondaryNameNode工作的触发点:
1.fs.checkpoint.period指定两次checkpoint之间最大时间间隔,默认实践为3600秒,即一个小时。
2.fs.checkpoint.size规定editlog文件的最大值,该文件默认的大小是64M,一旦超过这个值则会强制触发SecondaryNameNode工作。
这两个属性可以在core-default.xml文件中找到,配置在core-site.xml文件中。
问题一:在hadoop1.x中,HDFS如何实现高可靠?
答:
1.在hdfs-site.xml文件中配置dfs.name.dir属性,这个属性是NameNode放在元数据信息用的,多个目录用逗号隔离,HDFS会把元数据冗余复制到这些目录,一般这些目录在不同的设备上,不存在的目录会被忽略掉。
2.通过SecondaryNameNode恢复NameNode,详情见http://blog.csdn.net/lzm1340458776/article/details/38820739
3.使用第三方的工具avatarnode
问题二:执行HDFS的格式化时发生了什么事情?
答:NameNode创建了自己的目录结构。
问题三:多次格式后导致DataNode启动不了,怎么办?
答:将 ${hadoop.tmp.dir}/dfs/name/current/VERSION中nameSpaceID的值和${hadoop.tmp.dir}/dfs/data/VERSION中nameSpaceID的值修改为一致。
以上是关于分布式文件系统以及对相关节点的简单理解的主要内容,如果未能解决你的问题,请参考以下文章