分布式事务浅析
Posted Qunar技术沙龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务浅析相关的知识,希望对你有一定的参考价值。



罗招材,2016年7月加入去哪儿网技术团队。目前在火车票事业部/技术部,参与了火车票系统服务拆分、数据库中间件以及日志系统的构建,对系统性能优化和高并发的系统感兴趣。个人爱好户外和音乐。
引言
印象中事务是个不太好理解的概念,因为涉及的概念、原理和模型较多,本文梳理了事务涉及到的相关知识,包括事务的概念、特性、本地事务实现原理、Spring事务 和分布式事务模型以及相关的开源实现分析。
概念
参考维基百科对数据库事务定义:
A transaction symbolizes a unit of work performed within a database management system (or similar system) against a database, and treated in a coherent and reliable way independent of other transactions. A transaction generally represents any change in a database. Transactions in a database environment have two main purposes:
To provide reliable units of work that allow correct recovery from failures and keep a database consistent even in cases of system failure, when execution stops (completely or partially) and many operations upon a database remain uncompleted, with unclear status.
To provide isolation between programs accessing a database concurrently. If this isolation is not provided, the programs' outcomes are possibly erroneous.
简单来说,事务是数据库管理系统对数据库进行操作的基本单元,事务中的操作以原子的方式执行,同时事务的执行结果是准确的,并且事务之间彼此隔离执行。
单机事务
分布式事务是建立在单机事务的基础上扩展而来的,因此需要首先了解单机事务的相关概念和基本的实现原理。
事务特性概念
说到事务,就不得不提事务提供的 ACID 特性,维基百科对事务的 ACID 对定义如下:
1.原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
2.一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
3.隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
4.持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。
正是由于引入了数据库事务提供的 ACID 保证,上层应用不用考虑各种异常情况的处理,使得编程模型得到了简化,详细的解释参考:
《Designing Data-Intensive Applications》
Transactions are not a law of nature; they were created with a purpose, namely to simplify the programming model for applications accessing a database. By using transactions, the application is free to ignore certain potential error scenarios and concurrency issues, because the database takes care of them instead (we call these safety guarantees).
特性的理解
理解事务的 ACID 是理解事务的关键,同时分布式事务中的 ACID 也是沿用单机事务的 ACID 概念,因此需要首先理解单机事务的 ACID。对于事务提供了 ACID 的特性,其中原子性和持久性的含义还是比较明确的,但是一致性和隔离性就不那么好理解了,下面尝试分析一下这两个特性的含义。
隔离性
首先隔离性,隔离性是针对多个事务并发执行提供的并发安全性的保证,多个事务并发执行通常会导致以下几个问题,现象可以参考:
并发编程网 - 何为脏读、不可重复读、幻读
1.脏读(dirty read):事务能读到其他已回滚或者未提交的事务对数据的修改 。
2.不可重复读(non-repeatable read):事务多次读同一条数据得到的结果不一致。
不可重复读和脏读的区别在于脏读读的是其他已经回滚或者未提交的事务对数据的修改,而不可重复读虽然读的都是已经提交的事务的数据,但是可能是多个其他事务对同一条数据的修改,因此一个进行中的事务读一条数据时可能读到多个结果。
3.幻读(phantom read):事务多次读取时能读到其他事务新增的数据,幻读主要指的是新数据插入而不是修改。
事务为了解决上述问题因此引入了隔离性,隔离性的本质就是对并发的控制,但在实现上却需要考虑隔离性对事务并发度的影响,通常隔离的越严格,并发度就会越低,通常需要在二者之间找到合适的平衡点。因此就需要引入另一个描述隔离性的概念也就是隔离级别,SQL 标准的事务隔离级别包括:
读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable )
1.读未提交(read uncommitted):一个事务还没提交时,它做的变更就能被别的事务看到,这种级别存在脏读、不可重复读、幻读。
2.读已提交(read committed):一个事务提交之后,它做的变更才会被其他事务看到,这种级别存在不可重复读、幻读。
3.可重复读(repeatable read):一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的,这种级别存在幻读。
4.串行化(serializable ):对于同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。这个级别下脏读、不可重复读、幻读问题都不存在。
如前面提到的,之所以需要定义这四种隔离级别是因为要平衡隔离性和并发效率,不同的隔离级别下能解决的并发导致的问题不一样。实际的应用中需要根据业务的容忍度,选择合适的隔离级别来达到最好的并发度。对于上述四个隔离级别,其中“读未提交”和“串行化”这两个隔离级别比较好理解,也就是“读未提交”对数据的访问完全不加并发控制,而“串行化”则严格的保证各个事务依次串行执行。
对于"读已提交"和"可重复读"这两个隔离级别比较难理解,用一个例子说明这几种隔离级别。假设我们有张 mysql 数据表如下,数据表 T 中只有一列,其中有一行的值为 1,
mysql> create table T(c int) engine=InnoDB;
insert into T(c) values(1);
下面是按照时间顺序执行两个事务的行为,

在不同的隔离级别下,图中 V1、V2、V3 的返回值是不太一致的,
1.若隔离级别是“读未提交”, 则 V1 的值就是 2。这时候事务 B 虽然还没有提交,但是结果已经被 A 看到了。因此,V2、V3 也都是 2。
2.若隔离级别是“读提交”,则 V1 是 1,V2 的值是 2。事务 B 的更新在提交后才能被 A 看到。所以, V3 的值也是 2。
3.若隔离级别是“可重复读”,则 V1、V2 是 1,V3 是 2。之所以 V2 还是 1,遵循的就是这个要求:事务在执行期间看到的数据前后必须是一致的。
4.若隔离级别是“串行化”,则在事务 B 执行将 1 改成 2 的时候,会被锁住。直到事务 A 提交后,事务 B 才可以继续执行。所以从 A 的角度看, V1、V2 值是 1,V3 的值是 2。
在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。在“可重复读”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图(视图的概念后续实现中会再解释)。在“读提交”隔离级别下,这个视图是在每个 SQL 语句开始执行的时候创建的。这里需要注意的是,“读未提交”隔离级别下直接返回记录上的最新值,没有视图概念;而“串行化”隔离级别下直接用加锁的方式来避免并行访问。不同的隔离级别,数据的行为是不一致的。
一致性
数据库中一致性的概念也是比较含糊,理解可以参考 Designing Data-Intensive Applications 以及 如何理解数据库事务中的一致性的概念 中的解释。
The idea of ACID consistency is that you have certain statements about your data (invariants) that must always be true—for example, in an accounting system, credits and debits across all accounts must always be balanced. If a transaction starts with a database that is valid according to these invariants, and any writes during the transaction preserve the validity, then you can be sure that the invariants are always satisfied.
However, this idea of consistency depends on the application’s notion of invariants, and it’s the application’s responsibility to define its transactions correctly so that they preserve consistency. This is not something that the database can guarantee: if you write bad data that violates your invariants, the database can’t stop you. (Some specific kinds of invariants can be checked by the database, for example using foreign key constraints or uniqueness constraints. However, in general, the application defines what data is valid or invalid—the database only stores it.)
Atomicity, isolation, and durability are properties of the database, whereas consistency (in the ACID sense) is a property of the application. The application may rely on the database’s atomicity and isolation properties in order to achieve consistency, but it’s not up to the database alone. Thus, the letter C doesn’t really belong in ACID.
大致来说,ACID 的中的一致性和平常涉及到的其他一致性的概念是不一样的,比如与副本备份的一致性、一致性 hash 以及 CAP 理论中的一致性的含义是不一样的。
ACID 里的 AID 都是数据库的特征,也就是依赖数据库的具体实现。而唯独这个 C 也就是一致性,实际上它依赖于应用层,也就是依赖于开发者。这里的一致性是指数据库中的数据开始是正确的,随着状态转移,总是保持正确的状态,用户在任意时刻的任何请求返回的都是正确的结果。所谓正确的状态,就是当前的状态满足预定的约束条件,而正确性的约束其实是应用层判定的。例如对于一个资金系统来说满足资金平衡这样一个应用层定义的约束条件就可以认为是一个正确的状态。数据库只是以一定的模式存储数据,本质是对真实世界建模,因此这里的正确是指数据满足真实世界各种约束。而事务的 ACID 特性中的 C 的特性其实是通过 AID 来保证我们的一致性。事务一致性保证了事务开始前数据库处于一致状态,结束后数据库依旧满足一致性。
mysql 中的事务
不同的数据库对事务的实现方式是不一致的,这里主要分析最常用的 mysql 中对于事务的实现,以便加深对事务的理解。实现事务其实就是实现事务的 ACID 特性,上面分析中说过一致性是相对于应用层来说的,因此实际的数据库主要实现了事务的 AID 特性,其中 A 原子性实现比较好理解,因为对于数据库的操作的基本单元就是事务,一个事务是由一条或者多条读写操作语句组成,同时通过在异常时通过回滚方式保证了操作的原子性。下面主要分析一下持久性和隔离性的实现。
基本架构
在理解 mysql 对于持久性和隔离性的实现之前,需要简单的说明一下 mysql 的基本架构:
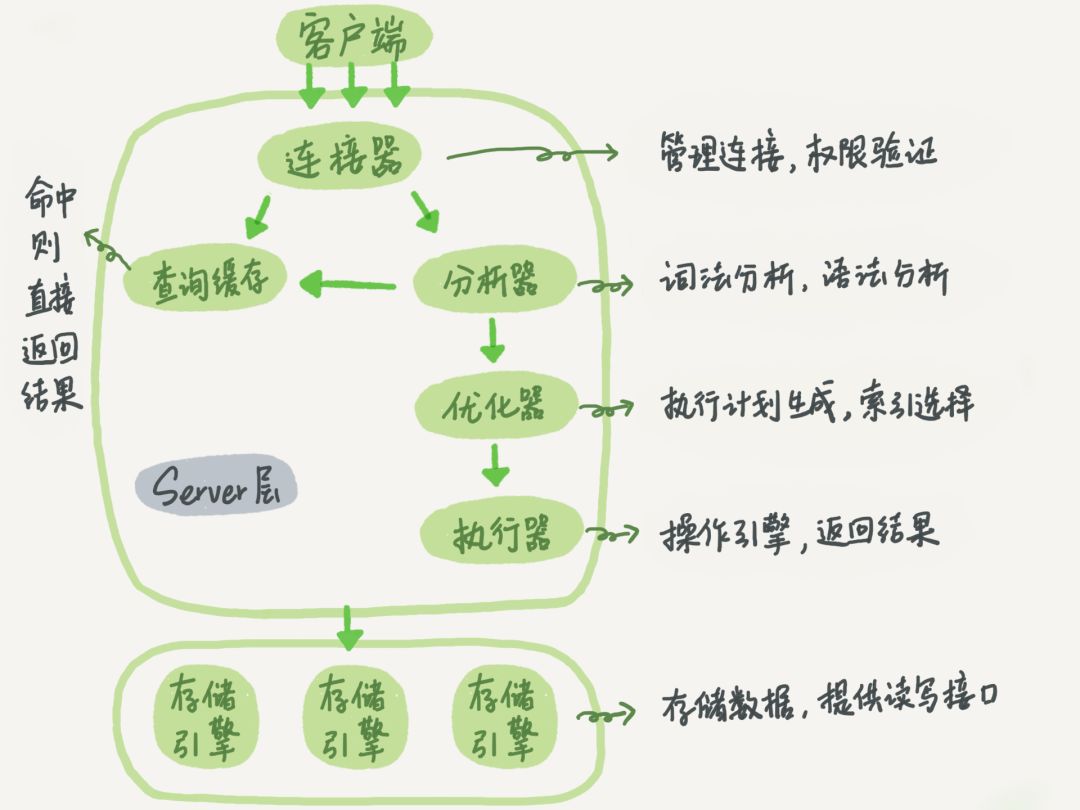
大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。
Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
分析 mysql 的事务的实现,其实需要具体到引擎,因为不是所有的 Mysql 引擎都支持事务,下面分析的也就是最常用的 InnoDB 引擎中对事务的实现。
持久性实现
事务的持久性体现在所有的已经提交的事务都需要进行持久化,正常情况下持久化没有问题,主要是要考虑异常情况如断电、宕机等极端情况下的事务崩溃恢复机制。 首先需要了解一下 mysql 内部是如何将事务更新的数据写入到磁盘中的,事务对数据的修改通常是先修改的内存数据,但最终更新的数据是需要写入磁盘进行持久化的,但 mysql 的做法并不是每次都将事务的更新数据都写入到磁盘,因为写磁盘太慢了,因此 mysql 在实现时引入了一种叫 WAL(Write-Ahead Logging) 的优化机制。WAL 机制的关键点就是先写日志,再写磁盘,这里说的日志就是 mysql 中重要的日志模块 redo log 日志。具体来说,当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log 里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做。( WAL 技术优化在于,用顺序的日志文件的写来代替磁盘的随机写,由于日志文件是连续的,因此可以极大的提升性能,这种类似的技术在其他一些如消息队列中也有应用) InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这个 redo log 总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示:
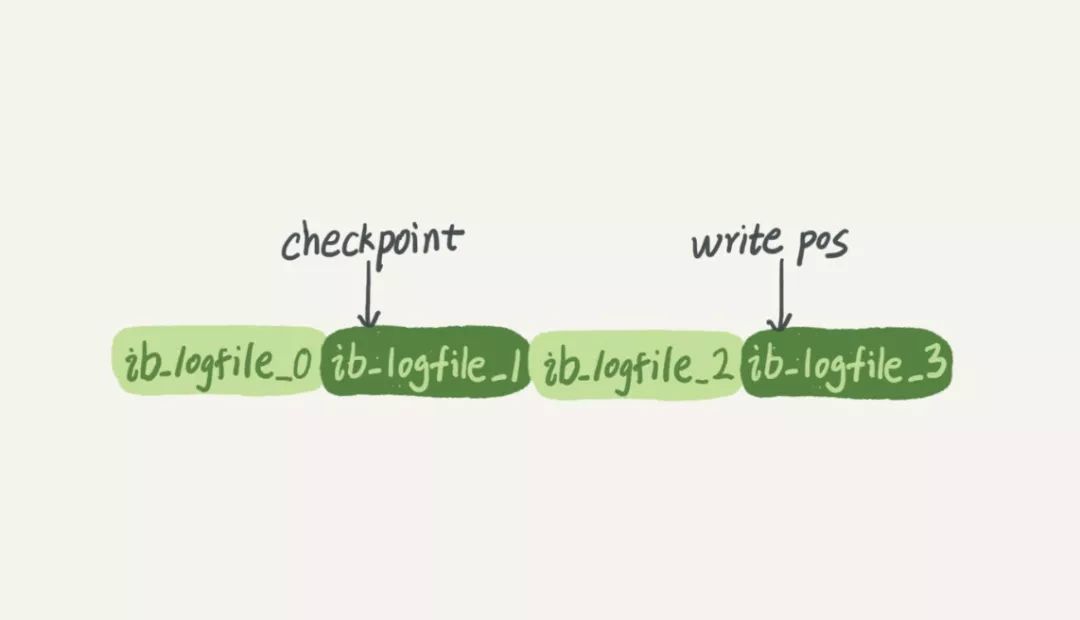
write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录的更新持久化到磁盘中。write pos 和 checkpoint 之间的是 redo log 上还空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示 redo log 满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下( checkpoint 机制可以用来做数据备份和恢复)。有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe 。
同时 mysql 在事务更新中除了写 redo log 之外,为了支持主从数据同步还需要写一个重要的日志文件也就是 binlog,需要注意的是 binlog 是在 server 层写的,而 redo log 是在引擎层写的日志。例如我们要执行一条简单的事务更新语句,
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
) ENGINE=InnoDB;
begin;
update t set c=c+1 where id=2;
commit;
在 mysql 内部这条语句的执行流程简化如下,其中为了保证 redo log 和 binlog 的写入的一致性,mysql 在内部使用了两阶段提交协议来实现,首先会将 redo log 进行 prepare 状态, 然后写 binlog 日志,binlong 日志写成功后再将 redo log 日志的状态更改为 commit ,至此事务提交完成。
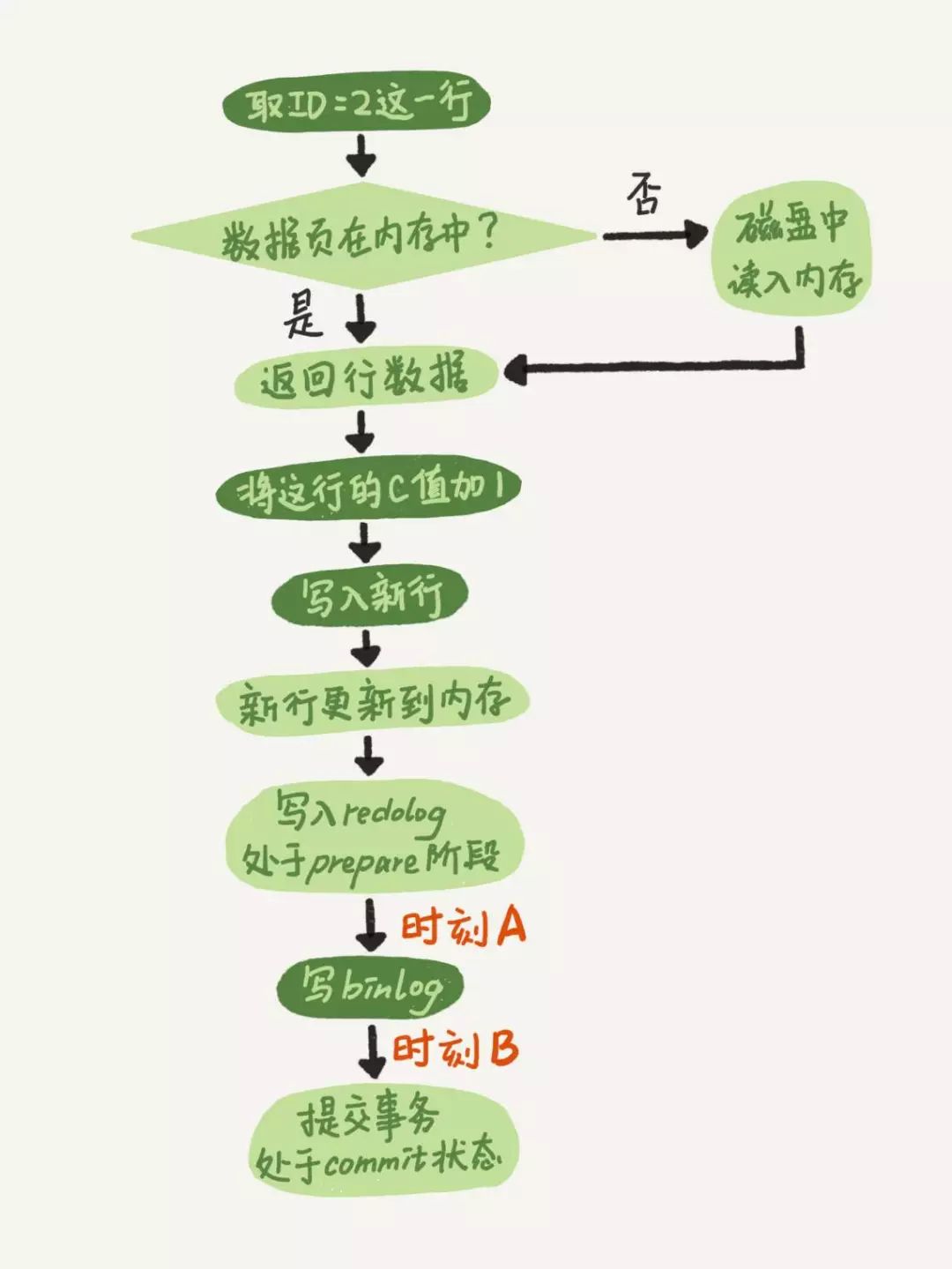
下面看看异常情况下,mysql 是如何实现异常恢复来保证 crash-safe 的,如上图中所示,我们将系统异常宕机/断电的时间点进行划分为四个区间,写入 redo log 的 prepare 之前、时刻 A 、时刻 B 、事务 commit 之后。接下来分析一下在两阶段提交的不同时刻,MySQL 异常重启会出现什么现象。 写入 redo log 的 prepare 之前和事务 commit 之后这两个阶段比较简单,前者回滚事务,后者事务已经提交,没有什么问题,关键在于时刻 A 阶段和时刻 B 阶段。 对于时刻 A ,如果在图中时刻 A 的地方,也就是写入 redo log 处于 prepare 阶段之后、写 binlog 之前,发生了崩溃,由于此时 binlog 还没写,redo log 也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog 还没写,所以也不会传到备库,没有影响。 对于时刻 B,也就是 binlog 写完,redo log 还没 commit 前发生崩溃,那崩溃恢复的时候 MySQL 的崩溃恢复判断规则如下,
1.如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
2.如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:如果是,则提交事务;否则,回滚事务。 mysql 重启之后在提供服务之前会将所有异常的事务先进行如上的崩溃恢复操作,这样保证所有所有已经提交的事务的持久性。
隔离性实现
innodb 中隔离性的实现和具体的隔离机制有关,“未提交读”和“串行化”前面也提到过,实现上比较好理解,这里主要分析一下“读已提交”和“可重复读”这两种隔离机制下的实现,因为这两依赖于 Innodb 引擎中的一系列的技术如 MVCC 、“快照”以及“锁”来实现的。
MVCC
隔离性主要是解决多事务同时读写相互干扰的问题,主要是更新操作,在 mysql 内部每一条更新操作都会产生一条回滚日志 undo log ,记录上的最新值,通过回滚操作,都可以得到前一个状态的值。 假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录。当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的视图read-view 。如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制 MVCC 。
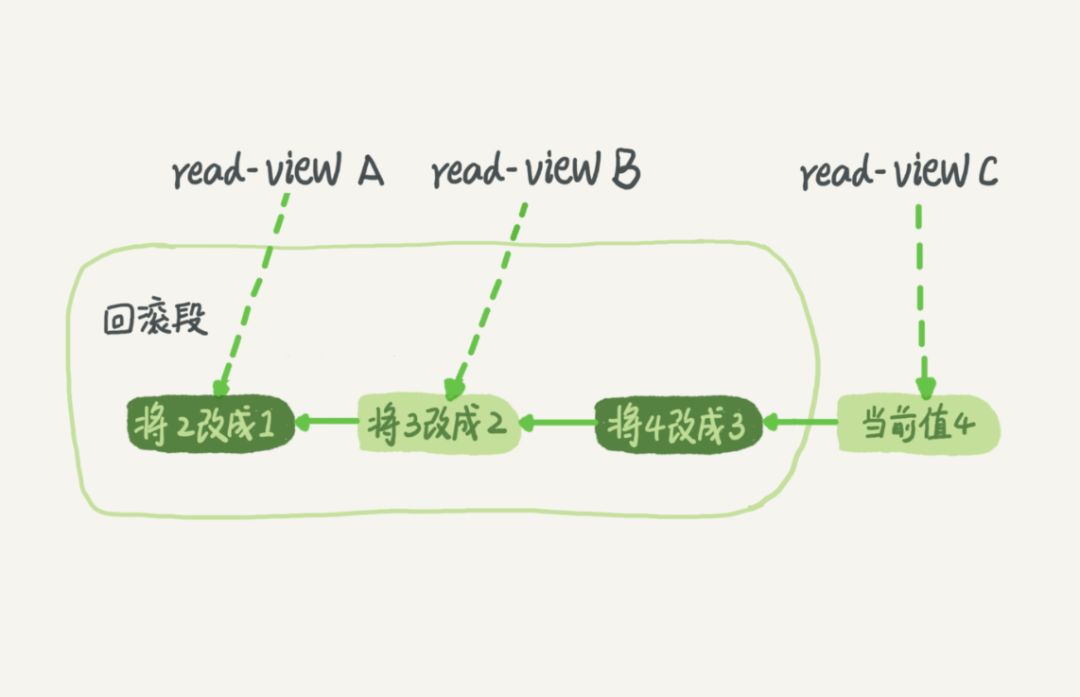
对于 read-view A ,要得到 1,就必须将当前值依次执行图中所有的回滚操作得到。这样,即使现在有另外一个事务正在将 4 改成 5,这个事务跟 read-view A、B、C 对应的事务的读是不会冲突的。当然,回滚段日志也就是 undo log 会在系统不需要时删除,也就是没有比这个回滚段日志更早的 read-view 时。 这里说的视图 read-view 是 MVCC 中用的一致性读视图,实现是通过事务启动时创建的快照和一套数据可见性规则确定的,下面解释快照和数据可见性规则。
快照
前面提到的 read-view 也就是快照是如何创建的?首先快照是基于整个库的,如果一个库有 100G,那么当启动一个事务时,MySQL 并不是拷贝 100G 的数据出来,那样效率太低,下面简单分析一下它的实现原理。 InnoDB 里面每个事务有一个唯一的事务 ID,叫作 transaction id 。它是在事务开始的时候向 InnoDB 的事务系统申请的,是按申请顺序严格递增的。而每行数据也都是有多个版本的。每次事务更新数据的时候,都会生成一个新的数据版本,并且把 transaction id 赋值给这个数据版本的事务 ID,记为 row trxid 。同时,旧的数据版本要保留,并且在新的数据版本中,能够有信息可以直接拿到它。也就是说,数据表中的一行记录,其实可能有多个版本 row ,每个版本有自己的 row trxid 。
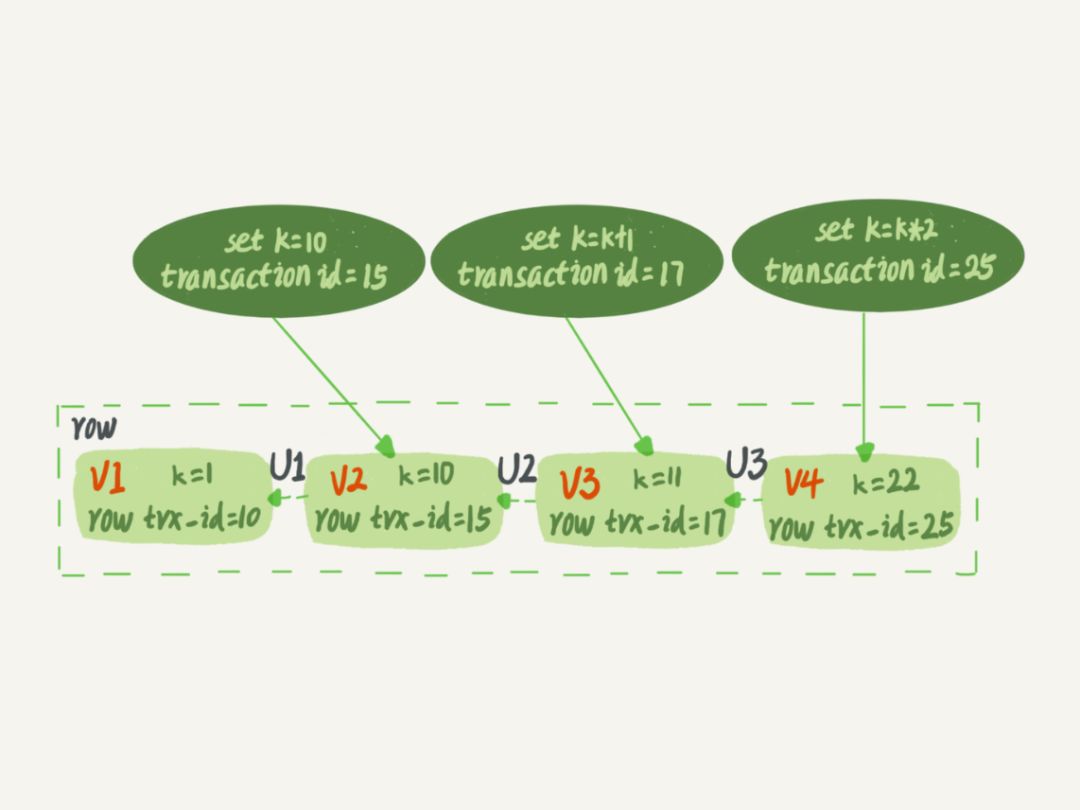
如上图所示,就是一个记录被多个事务连续更新后的状态,那 innodb 是如何定义一个 100G 的快照的呢? 按照可重复读的定义,一个事务启动的时候,能够看到所有已经提交的事务结果。但是之后,这个事务执行期间,其他事务的更新对它不可见。因此,一个事务只需要在启动的时候声明,“以我当前启动的时刻为准,如果一个数据版本是在我启动之前生成的,就认;如果是我启动以后才生成的,我就不认,我必须要找到它的上一个版本”。当然,如果“上一个版本”也不可见,那就得继续往前找。还有,如果是这个事务自己更新的数据,它自己还是要认的。 在实现上, InnoDB 为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前正在“活跃”的所有事务 ID 。“活跃”指的就是,启动了但还没提交。数组里面事务 ID 的最小值记为低水位,当前系统里面已经创建过的事务 ID 的最大值加 1 记为高水位。这个视图数组和高水位,就组成了当前事务的一致性视图(read-view)。而数据版本的可见性规则,就是基于数据的 row trxid 和这个一致性视图的对比结果得到的。这个视图数组把所有的 row trxid 分成了几种不同的情况。
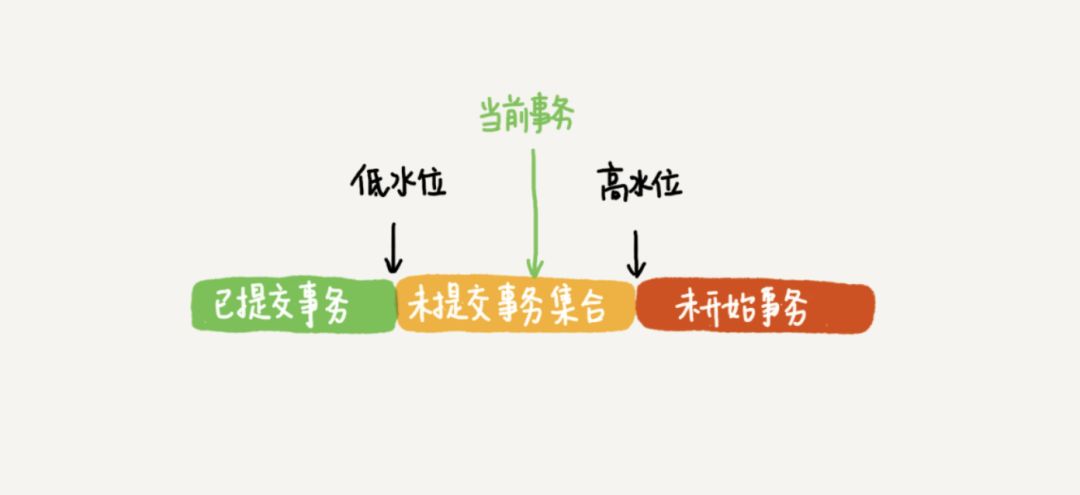
这样,对于当前事务的启动瞬间来说,一个数据版本的 row trxid ,有以下几种可能:
1.如果落在绿色部分,表示这个版本是已提交的事务或者是当前事务自己生成的,这个数据是可见的;
2.如果落在红色部分,表示这个版本是由将来启动的事务生成的,是肯定不可见的
3.如果落在黄色部分,那就包括两种情况:
a. 若 row trxid 在数组中,表示这个版本是由还没提交的事务生成的,不可见;
b. 若 row trxid 不在数组中,表示这个版本是已经提交了的事务生成的,可见。 比如,对于前面图中的数据来说,如果有一个事务,它的低水位是 18 ,那么当它访问这一行数据时,就会从 V4 通过 U3 计算出 V3,所以在它看来,这一行的值是 11。之所以需要记录事务启动时所有活跃的事务 ID 数组,是因为单纯的通过 row trxid 的数值比较是无法确定数据是否可见的,因为有可能会出现事务 ID 小的对数据的更新操作会后于事务 ID 较大的,对于这种情况事务 ID 较大的事务创建快照时会将还未提交的活跃的事务 ID 较小的事务记录到活跃数组中,这样根据上述的判定规则,就可以得到正确的结果。
有了这个声明判定规则后,系统里面随后发生的更新,就跟这个事务看到的内容无关了,因为之后的更新,生成的版本一定属于上面的 2 或者 3(a) 的情况,而对它来说,这些新的数据版本是不存在的,所以这个事务的快照,就是“静态”的了。所以InnoDB 利用了“所有数据都有多个版本”的这个特性,实现了“秒级创建快照”的能力。
锁
当两个事务对一条数据进行更新操作时,需要对该行数据加一个行锁,加锁的规则遵行 mysql 中所谓的两阶段锁协议,两阶段锁协议是指,在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。

例如对于一条初始数据为 (1,1) 的数据表 t 执行上面的事务操作,事务 C 更新后并没有马上提交,在它提交前,事务 B 的更新语句先发起了。前面说过了,虽然事务 C还没提交,但是 (1,2) 这个版本也已经生成了,并且是当前的最新版本。那么,事务 B 的更新语句就需要进行“两阶段锁协议”进行加锁了。事务 C 没提交,也就是说 (1,2) 这个版本上的写锁还没释放。而事务 B 是当前读,也就是必须要读最新版本,而且必须加锁,因此就被锁住了,必须等到事务 C 释放这个锁,才能加锁成功继续它的更新操作。
实现
有了上面关于 MVCC 、视图和锁的概念后,便可以理解 Innodb 引擎是如何实现“读已提交”和“可重复读”的了。
“可重复读”的核心就是“一致性读”(consistent read);而事务更新数据的时候,只能用当前读。如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待。而“读提交”的逻辑和“可重复读”的逻辑类似,它们最主要的区别是,这两种隔离级别的区别就在于创建视图的时机不同。
1.在“可重复读”隔离级别下,只需要在事务开始的时候创建一致性视图,之后事务里的其他查询都共用这个一致性视图;
2.在“读提交”隔离级别下,每一个语句执行前都会重新算出一个新的视图。
幻读问题
一般可重复读下是仍然存在幻读问题的,但是在实际的使用 innodb 引擎时会发现并没有幻读的问题,原因 innodb 引擎实现是引入了间歇锁 Gap-Lock 机制解决了幻读的问题。
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
产生幻读的根本原因是,行锁只能锁住行,但是新插入记录这个动作,要更新的是记录之间的“间隙”。因此,为了解决幻读问题,innodb 引擎只好引入新的锁,也就是间隙锁 Gap Lock 。顾名思义,间隙锁,锁的就是两个值之间的空隙。比如对于一张数据表 t 如下图,初始化插入了 6 个记录,这就产生了 7 个间隙。
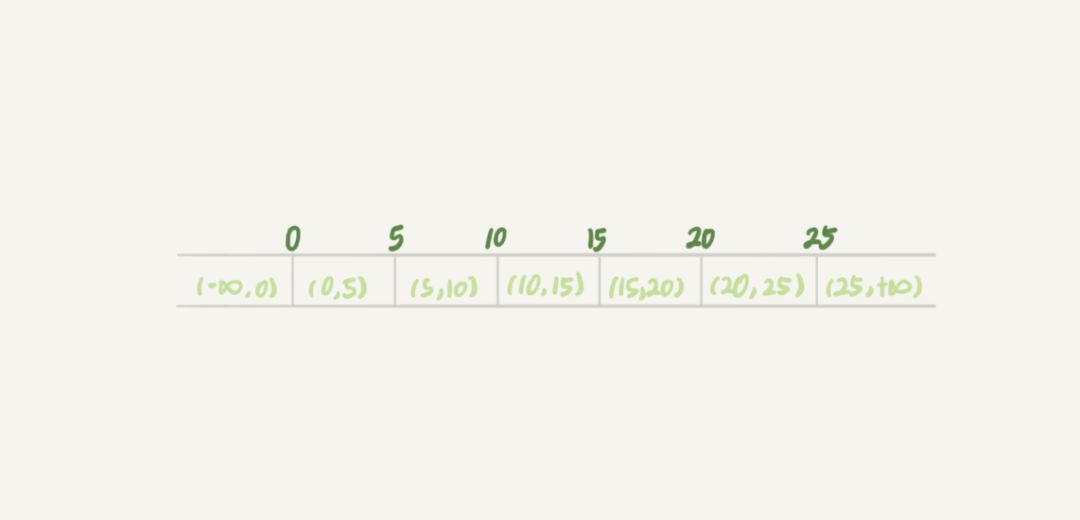
这样,当执行 select * from t where d=5 for update 的时候,由于 d 是无索引的,因此相当于全表扫描,而 mysql 中的加锁规则是扫描到某个值时就需要获取相应的锁,因此这条语句就不止是给数据库中已有的 6 个记录加上了行锁,还同时加了 7 个间隙锁,这样就确保了无法再插入新的记录。需要注意的是跟间隙锁存在冲突关系的,是“往这个间隙中插入一个记录”这个操作,两个间隙锁之间都不存在冲突关系。同时间歇锁的引入其实也会降低事务的并发度,“行锁 + 间歇锁”也称为 mysql 中的 next-key lock 。
分布式事务
概念
引用维基百科中对于分布式事务的定义如下:
A distributed transaction is a database transaction in which two or more network hosts are involved. Usually, hosts provide transactional resources, while the transaction manager is responsible for creating and managing a global transaction that encompasses all operations against such resources. Distributed transactions, as any other transactions, must have all four ACID (atomicity, consistency, isolation, durability) properties, where atomicity guarantees all-or-nothing outcomes for the unit of work (operations bundle).
大概来说就是当一个事务是由多个且不同的支持单机事务的网路节点组成时,就是一个分布式事务。分布式事务为什么是个问题? 首先,假设对于一个传统的单体应用,通过 3 个 Module 在同一个数据源上更新数据来完成一项业务,整个业务过程的数据一致性是可以由本地事务来保证。
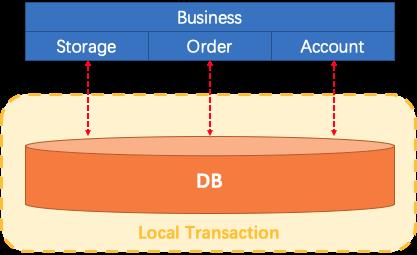
但随着业务需求和架构的变化,单体应用被拆分为微服务:原来的 3 个 Module 被拆分为 3 个独立的服务,分别使用独立的数据源,业务过程将由 3 个服务的调用来完成。
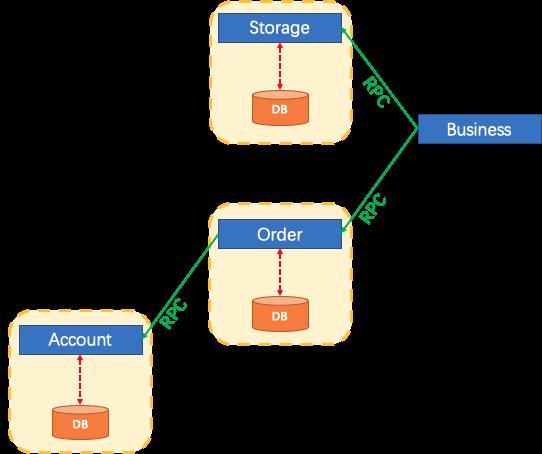
此时,每一个服务内部的数据一致性仍由本地事务来保证,但是整个业务层面的全局数据一致性却是无法保障的。这也就是微服务架构下面临的,因此我们需要一个分布式事务的解决方案保障业务全局的数据一致性。
模型
分布式事务并不是一个新鲜的概念,业界也已经有成熟的解决方案,这是一个业务发展后,架构拆分之后必然要面临的问题,解决方案主要有以下几种模型,按是否对业务有侵入划分:
1.无侵入方案:XA模型
2.侵入方案:
(1)基于可靠消息的最终一致性解决方案
(2)TCC模型
(3)Sagas模型
XA模型
XA 模型是指由 X/Open 组织提出的分布式事务处理的规范。XA 规范主要定义了 Transaction Manager(TM)和 Resource Manager(RM)之间的接口,结构如下图所示:
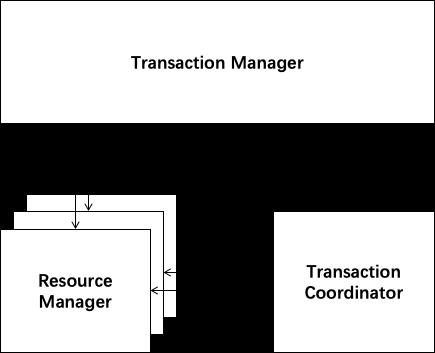
XA事务模型中有三个重要的组成部分:
1.Transaction Coordinator (TC): 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。
2.Transaction Manager (TM): 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。
3.Resource Manager (RM): 控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
一个典型的分布式事务过程:
(1)TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID 。
(2)XID 在微服务调用链路的上下文中传播。
(3)RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖。
(4)TM 向 TC 发起针对 XID 的全局提交或回滚决议。
(5)TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求。
XA 事务模型中 RM 是在数据库一层实现的,也就是说要求数据库支持 XA 事务,应用也通过支持 XA 事务的驱动来进行连接和操作,同时因为 XA 本质上是一个两阶段提交协议,因此存在以下几个问题:
1.要求数据库提供对 XA 的支持。如果遇到不支持 XA(或支持得不好,比如 MySQL 5.7 以前的版本)的数据库,则不能使用。
2.受协议本身的约束,事务资源(数据记录、数据库连接)的锁定周期长。长周期的资源锁定从业务层面来看,往往是不必要的,而因为事务资源的管理器是数据库本身,应用层无法插手。这样形成的局面就是,基于 XA 的应用往往性能会比较差,而且很难优化。
3.已经落地的基于 XA 的分布式解决方案,都依托于重量级的应用服务器(Tuxedo/WebLogic/WebSphere 等),这是不适用于微服务架构的。
可靠消息模型
基于可靠消息的事务模型,本质上是通过将事务日志存储在本地业务库,通过本地事务的方式保证事务日志与本地事务的一致性,然后通过可靠消息去异步推送和补偿事务日志来实现分布式事务的一致性。但以事务日志的存储位置也分为两种实现,一种是将消息表存在本地业务系统库,另一种是存在可靠消息中间中。 基于本地存储事务日志表的实现的事务流程是:
1.事务的主动发起方通过本地事务确保发起方的“业务本地事务”和“消息表”的事务一致性,并通过消息通知事务的被动方执行相应的事务逻辑;
2.当消失异常或者通知失败时,由消息恢复系统定时扫描未发送的消息继续发送。
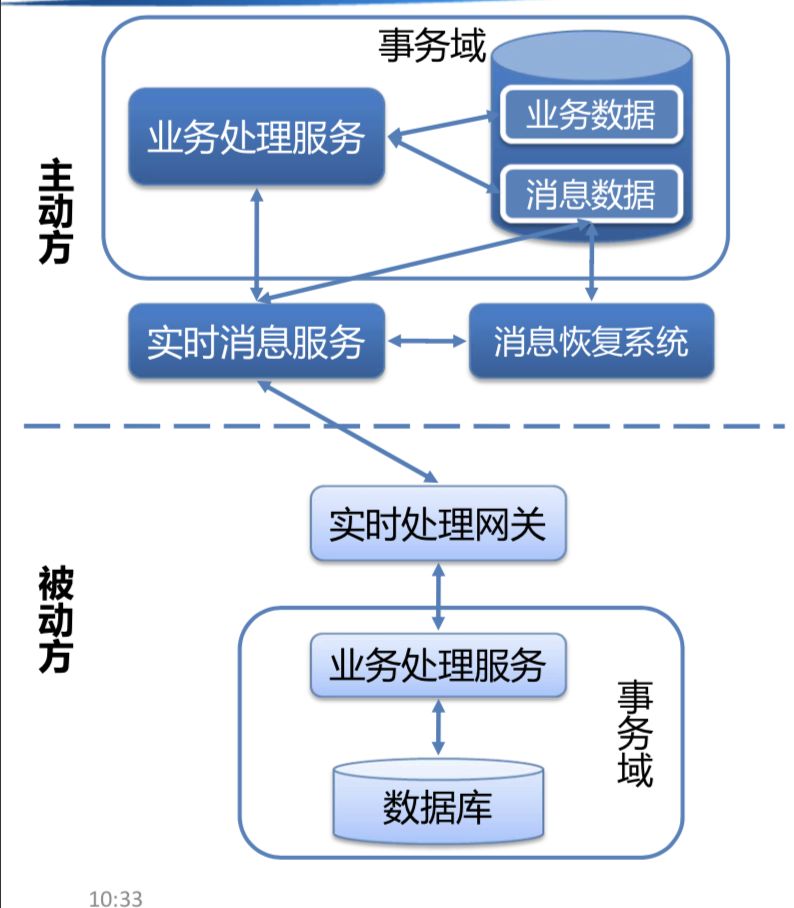
这种实现形式的分布式事务模型(公司的 qmq 的事务就是基于这种模型实现的)使用时也有一些约束:
1.事务的被动方的结果并不会影响业务发起方的结果;
2.事务被动方的事务处理逻辑需要支持幂等性;
3.基于消息中间存储事务日志表的实现原理如下:
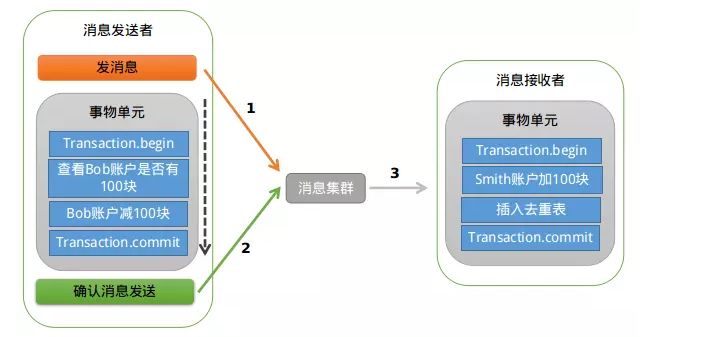
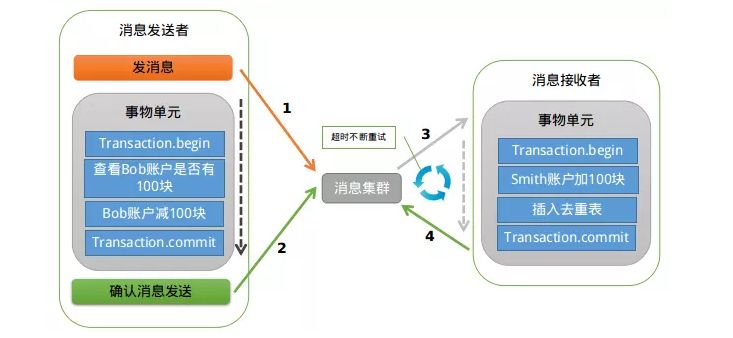
处理流程为:
1.事务发起方在提交事务前会向消息中间件发送消息,此时消息中间件负责存储到其消息表中,此时消息处于 prepare 阶段,并不会发送给事务被动方;
2.当事务发起方提交事务后,再向消息中间件发送确认消息,此时消息中间件将消息表的状态改为 commit 状态,并将消息发送给事务被动方;
3.业务发起方异常时,处于 prepare 状态的消息表中的记录会向事务发起方询问事务是提交还是回滚状态,并一次来做操作;
4.消息中间件本身异常时,有消息重试机制处理未处理的消息表记录。
这种方式的约束和前一种的一样,只是这种方式还需要消息中间支持,消息中间件包装了消息表,使得消息表不再与本地库绑定,
1.事务的被动方的结果并不会影响业务发起方的结果;
2.事务被动方的事务处理逻辑需要支持幂等性;
3.消息中间件需要支持事务消息存储;
4.事务发起方需要提供事务结果查询接口。
基于TCC模型
TCC事务模型是强一致性的分布式事务模型,其处理流程是:
1.主服务方启动一个TCC事务,业务活动管理器中记录并启动事务;
2.业务活动管理器依次调用各个从服务的 try 接口,各个从服务在这个阶段处理业务并锁定必要的资源;
3.业务活动管理器根据各个从服务的反馈,当都成功时调用从服务的 confirm 接口,依次提交各个事务,否则就调用 cancel 接口回滚整个事务;
4.业务活动管理器通过活动日志来保证异常情况下的事务恢复。
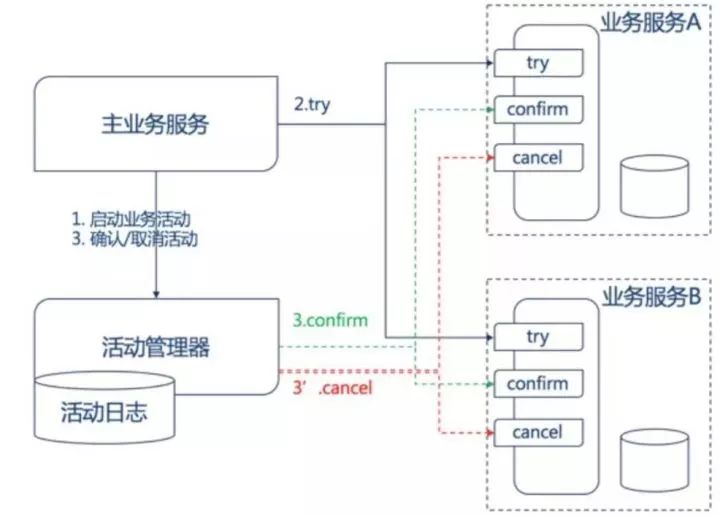
TCC事务模型的约束是:
1.从服务方需要提供 try confirm 和 cancel 三个接口;
2.接口支持幂等;
3.TCC 适用于强一致性场景,因此并发度会比较低,适合时间较短的事务。
sagas事务模型
Sagas 是 1987年 普林斯顿大学的 Hector Garcia-Molina 和 Kenneth Salem 发表了一篇 Paper ,讲述的是如何处理 long lived transaction(长活事务),Saga 是一个长活事务可被分解成可以交错运行的子事务集合。其中每个子事务都是一个保持数据库一致性的真实事务。 在 Sagas 事务模型中每个 Saga 由一系列 sub-transaction Ti 组成,每个 Ti 都有对应的补偿动作 Ci ,补偿动作用于撤销 Ti 造成的结果,可以看到和 TCC 相比,Saga 没有 Try 动作,它的 Ti 就是直接提交到库。Saga 的执行顺序有两种:
1.T1, T2, T3, ..., Tn;
2.T1, T2, ..., Tj, Cj,..., C2, C1,其中0 < j < n。
Saga 定义了两种恢复策略:
1.backward recovery:向后恢复,补偿所有已完成的事务,如果任一子事务失败。即上面提到的第二种执行顺序,其中 j 是发生错误的 sub-transaction ,这种做法的效果是撤销掉之前所有成功的 sub-transation ,使得整个 Saga 的执行结果撤销。
2.forward recovery:向前恢复,重试失败的事务,假设每个子事务最终都会成功。适用于必须要成功的场景,执行顺序是类似于这样的:T1, T2, ..., Tj(失败), Tj(重试),..., Tn,其中 j 是发生错误的 sub-transaction ,这种情况下不需要 Ci 。 显然,向前恢复没有必要提供补偿事务,如果你的业务中,子事务(最终)总会成功,或补偿事务难以定义或不可能,向前恢复更符合你的需求。理论上补偿事务永不失败,然而,在分布式世界中,服务器可能会宕机,网络可能会失败,在这种情况下就需要提供回退措施,比如人工干预。 当然使用 sagas 事务也是有约束的,具体的可以参考 ServiceComb 的实现:
1.每个服务方都需要提供事务的补偿接口方法;
2.服务方需要的事务需要支持幂等,因为有重试;
3.对于 ACID 特性 sagas 事务不保证隔离性,因此需要服务方支持补偿的顺序不影响结果。
小结
上面简单分析了几种分布式事务的实现模型,在实际应用中并没有一种适合所有场景的解决方案,通常也是根据业务特点来进行选择,通常也可能同时存在几种分布式事务模型的解决方案。
Spring事务模型
在日常开发中接触较多的其实是 Spring 的事务模型,Spring 为用户提供了非常简单的接口和注解来使用事务,了解 Spring 事务模型对于构建事务相关的知识体现也非常重要,下面简单分析一下 Spring 的事务模型。
模型
Spring 提供了一套统一的事务处理模型框架,作为事务框架并没有实现和解决具体的事务模型,而是为上层业务提供了一套事务处理模版,使得具体的事务管理模型可方便的接入框架中,而保持上层业务代码一致。因此总结而言 Spring 事务框架主要解决的问题是:
1.提供了简单且易于使用的“基于编程方式”以及“基于声明方式”的事务 API ;
2.通过封装具体的事务处理器,使得事务的具体操作和业务逻辑解耦,也就是说不管下层的具体事务管理器是单机事务还是分布式事务,业务代码可以是同一套而不需要做变更。
spring的使用时有分编程式和声明式两种:
编程式通过使用org.springframework.transaction.support.TransactionTemplate 模版方法中定义的事务处理的通用流程来使用事务,
而声明式事务则使用简单的 @Transactional 注解便可以使用 Spring 事务,但不管是编程式还是声明式的使用方式,他们底层都会委托给事务管理器 org.springframework.transaction.PlatformTransactionManager 来处理具体的事务逻辑,这样来达到业务和具体的事务管理器逻辑解耦。PlatformTransactionManager 的结构图如下:
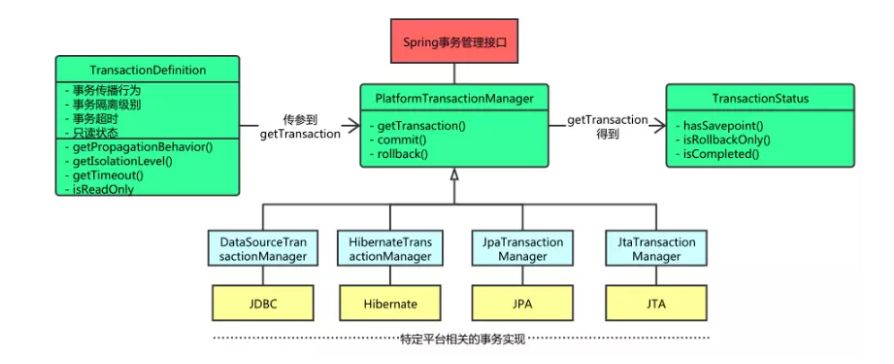
其中, org.springframework.transaction.TransactionDefinition 中定义了 Spring 事务中关于事务的各种属性,例如隔离级别、传播机制、超时时间和异常回滚类型等, org.springframework.transaction.TransactionStatus 定义了当前事务的执行状态。
事务传播机制
上面提到了事务传播机制,实际上事务传播机制是 Spring 事务框架中定义的一个概念,事务的传播机制一般在事务嵌套时候使用,这个事务传播机制定义了嵌套时的行为,比如在事务 A 里面调用了另外一个使用事务的方法,那么这俩个事务是各自作为独立的事务执行提交,还是内层的事务合并到外层的事务一块提交,这就是不同的事务传播机制定义的事务执行的不同的执行行为。
spring 事务传播机制在 org.springframework.transaction.TransactionDefinition 中定义了七种不同的事务执行行为,具体的行为解释参考代码注释:
public interface TransactionDefinition {
/**
* Support a current transaction; create a new one if none exists.
* Analogous to the EJB transaction attribute of the same name.
* <p>This is typically the default setting of a transaction definition,
* and typically defines a transaction synchronization scope.
*/
int PROPAGATION_REQUIRED = 0;
/**
* Support a current transaction; execute non-transactionally if none exists.
* Analogous to the EJB transaction attribute of the same name.
* <p><b>NOTE:</b> For transaction managers with transaction synchronization,
* {@code PROPAGATION_SUPPORTS} is slightly different from no transaction
* at all, as it defines a transaction scope that synchronization might apply to.
* As a consequence, the same resources (a JDBC {@code Connection}, a
* Hibernate {@code Session}, etc) will be shared for the entire specified
* scope. Note that the exact behavior depends on the actual synchronization
* configuration of the transaction manager!
* <p>In general, use {@code PROPAGATION_SUPPORTS} with care! In particular, do
* not rely on {@code PROPAGATION_REQUIRED} or {@code PROPAGATION_REQUIRES_NEW}
* <i>within</i> a {@code PROPAGATION_SUPPORTS} scope (which may lead to
* synchronization conflicts at runtime). If such nesting is unavoidable, make sure
* to configure your transaction manager appropriately (typically switching to
* "synchronization on actual transaction").
* @see org.springframework.transaction.support.AbstractPlatformTransactionManager#setTransactionSynchronization
* @see org.springframework.transaction.support.AbstractPlatformTransactionManager#SYNCHRONIZATION_ON_ACTUAL_TRANSACTION
*/
int PROPAGATION_SUPPORTS = 1;
/**
* Support a current transaction; throw an exception if no current transaction
* exists. Analogous to the EJB transaction attribute of the same name.
* <p>Note that transaction synchronization within a {@code PROPAGATION_MANDATORY}
* scope will always be driven by the surrounding transaction.
*/
int PROPAGATION_MANDATORY = 2;
/**
* Create a new transaction, suspending the current transaction if one exists.
* Analogous to the EJB transaction attribute of the same name.
* <p><b>NOTE:</b> Actual transaction suspension will not work out-of-the-box
* on all transaction managers. This in particular applies to
* {@link org.springframework.transaction.jta.JtaTransactionManager},
* which requires the {@code javax.transaction.TransactionManager} to be
* made available it to it (which is server-specific in standard Java EE).
* <p>A {@code PROPAGATION_REQUIRES_NEW} scope always defines its own
* transaction synchronizations. Existing synchronizations will be suspended
* and resumed appropriately.
* @see org.springframework.transaction.jta.JtaTransactionManager#setTransactionManager
*/
int PROPAGATION_REQUIRES_NEW = 3;
/**
* Do not support a current transaction; rather always execute non-transactionally.
* Analogous to the EJB transaction attribute of the same name.
* <p><b>NOTE:</b> Actual transaction suspension will not work out-of-the-box
* on all transaction managers. This in particular applies to
* {@link org.springframework.transaction.jta.JtaTransactionManager},
* which requires the {@code javax.transaction.TransactionManager} to be
* made available it to it (which is server-specific in standard Java EE).
* <p>Note that transaction synchronization is <i>not</i> available within a
* {@code PROPAGATION_NOT_SUPPORTED} scope. Existing synchronizations
* will be suspended and resumed appropriately.
* @see org.springframework.transaction.jta.JtaTransactionManager#setTransactionManager
*/
int PROPAGATION_NOT_SUPPORTED = 4;
/**
* Do not support a current transaction; throw an exception if a current transaction
* exists. Analogous to the EJB transaction attribute of the same name.
* <p>Note that transaction synchronization is <i>not</i> available within a
* {@code PROPAGATION_NEVER} scope.
*/
int PROPAGATION_NEVER = 5;
/**
* Execute within a nested transaction if a current transaction exists,
* behave like {@link #PROPAGATION_REQUIRED} else. There is no analogous
* feature in EJB.
* <p><b>NOTE:</b> Actual creation of a nested transaction will only work on
* specific transaction managers. Out of the box, this only applies to the JDBC
* {@link org.springframework.jdbc.datasource.DataSourceTransactionManager}
* when working on a JDBC 3.0 driver. Some JTA providers might support
* nested transactions as well.
* @see org.springframework.jdbc.datasource.DataSourceTransactionManager
*/
int PROPAGATION_NESTED = 6;
}
核心源码
对于 Spring 事务框架的核心逻辑源码,这里主要分析一下事务的使用接入和事务管理器。
就接入方式而言如果是编程式的接入,代码为:
org.springframework.transaction.support.TransactionTemplate 中的 execute 事务处理模版流程方法,TransactionTemplate 中采用的是"模版模式 + 策略模式" 的设计模式,通用流程用模版方式定义了通用的执行流程,策略模式体现在其内部字段 transactionManager 事务处理器中,
public class TransactionTemplate extends DefaultTransactionDefinition
implements TransactionOperations, InitializingBean {
@Nullable
private PlatformTransactionManager transactionManager;
@Override
@Nullable
public <T> T execute(TransactionCallback<T> action) throws TransactionException {
Assert.state(this.transactionManager != null, "No PlatformTransactionManager set");
if (this.transactionManager instanceof CallbackPreferringPlatformTransactionManager) {
// 异步处理方式
return ((CallbackPreferringPlatformTransactionManager) this.transactionManager).execute(this, action);
}
else {
TransactionStatus status = this.transactionManager.getTransaction(this);
T result;
try {
// 执行具体的业务逻辑
result = action.doInTransaction(status);
}
catch (RuntimeException | Error ex) { // 运行时异常和错误,直接回滚
// Transactional code threw application exception -> rollback
rollbackOnException(status, ex);
throw ex;
}
catch (Throwable ex) { // 处理其他类型的异常
// Transactional code threw unexpected exception -> rollback
rollbackOnException(status, ex);
throw new UndeclaredThrowableException(ex, "TransactionCallback threw undeclared checked exception");
}
this.transactionManager.commit(status); // 提交事务
return result;
}
}
}
对于声明式事务,xml 配置标签通过 TxNamespaceHandler 来注册相应的标签处理器,实际上使用的是 AnnotationDrivenBeanDefinitionParser 来处理 Spring 声明式事务框架的加载和处理,
public class TxNamespaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
registerBeanDefinitionParser("advice", new TxAdviceBeanDefinitionParser());
registerBeanDefinitionParser("annotation-driven", new AnnotationDrivenBeanDefinitionParser());
registerBeanDefinitionParser("jta-transaction-manager", new JtaTransactionManagerBeanDefinitionParser());
}
}
到 AnnotationDrivenBeanDefinitionParser 中处理解析逻辑,其解析时会创建三个重要的类,在如下注释中,分别是用于解析事务相关属性的 AnnotationTransactionAttributeSource ;创建声明式事务的的处理流程逻辑拦截器类 TransactionInterceptor ;以及嵌入到 Spring 的 AOP 处理流程中的切入逻辑处理类 TransactionAttributeSourceAdvisor 。这里有兴趣的可以参考 Spring源码解析之事务篇 跟踪一下具体的处理流程。
private static class AopAutoProxyConfigurer {
public static void configureAutoProxyCreator(Element element, ParserContext parserContext) {
// 注册代理生成器
AopNamespaceUtils.registerAutoProxyCreatorIfNecessary(parserContext, element);
String txAdvisorBeanName = TransactionManagementConfigUtils.TRANSACTION_ADVISOR_BEAN_NAME;
if (!parserContext.getRegistry().containsBeanDefinition(txAdvisorBeanName)) {
Object eleSource = parserContext.extractSource(element);
// 创建用于解析事务相关属性的解析器
// Create the TransactionAttributeSource definition.
RootBeanDefinition sourceDef = new RootBeanDefinition(
"org.springframework.transaction.annotation.AnnotationTransactionAttributeSource");
sourceDef.setSource(eleSource);
sourceDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
String sourceName = parserContext.getReaderContext().registerWithGeneratedName(sourceDef);
// 创建声明式事务的拦截器,事务的处理流程逻辑就在这个拦截器中
// Create the TransactionInterceptor definition.
RootBeanDefinition interceptorDef = new RootBeanDefinition(TransactionInterceptor.class);
interceptorDef.setSource(eleSource);
interceptorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registerTransactionManager(element, interceptorDef);
interceptorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
String interceptorName = parserContext.getReaderContext().registerWithGeneratedName(interceptorDef);
// Spring事务是基于AOP机制实现的,这里创建用于接入到AOP中的切入点处理逻辑类
// Create the TransactionAttributeSourceAdvisor definition.
RootBeanDefinition advisorDef = new RootBeanDefinition(BeanFactoryTransactionAttributeSourceAdvisor.class);
advisorDef.setSource(eleSource);
advisorDef.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
advisorDef.getPropertyValues().add("transactionAttributeSource", new RuntimeBeanReference(sourceName));
advisorDef.getPropertyValues().add("adviceBeanName", interceptorName);
if (element.hasAttribute("order")) {
advisorDef.getPropertyValues().add("order", element.getAttribute("order"));
}
parserContext.getRegistry().registerBeanDefinition(txAdvisorBeanName, advisorDef);
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), eleSource);
compositeDef.addNestedComponent(new BeanComponentDefinition(sourceDef, sourceName));
compositeDef.addNestedComponent(new BeanComponentDefinition(interceptorDef, interceptorName));
compositeDef.addNestedComponent(new BeanComponentDefinition(advisorDef, txAdvisorBeanName));
parserContext.registerComponent(compositeDef);
}
}
}
最终声明式事务处理流程逻辑在 TransactionInterceptor 中,
@Nullable
protected Object invokeWithinTransaction(Method method, @Nullable Class<?> targetClass,
final InvocationCallback invocation) throws Throwable {
// If the transaction attribute is null, the method is non-transactional.
// 获取事务相关配置属性
TransactionAttributeSource tas = getTransactionAttributeSource();
final TransactionAttribute txAttr = (tas != null ? tas.getTransactionAttribute(method, targetClass) : null);
// 获取配置的具体的事务处理器
final PlatformTransactionManager tm = determineTransactionManager(txAttr);
final String joinpointIdentification = methodIdentification(method, targetClass, txAttr);
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) {
// Standard transaction demarcation with getTransaction and commit/rollback calls.
// 事务开始
TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);
Object retVal = null;
try {
// This is an around advice: Invoke the next interceptor in the chain.
// This will normally result in a target object being invoked.
retVal = invocation.proceedWithInvocation(); // 执行业务逻辑
}
catch (Throwable ex) {
// target invocation exception
// 处理异常回滚
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
// 清空事务相关信息
cleanupTransactionInfo(txInfo);
}
// 正常情况下提交事务
commitTransactionAfterReturning(txInfo);
return retVal;
}
...
}
可以看到不管是编程式还是声明式最后都是采用"模版 + 策略"的设计模式将业务代码与事务处理逻辑进行了解耦,PlatformTransactionManager 事务处理器中定义了事务的具体逻辑,主要包括三个接口,getTransaction、commit 和 rollback ,其抽象实现类 AbstractPlatformTransactionManager 中会处理事务传播机制定义的行为,事务传播机制的行为本质上是处理同一个线程中事务嵌套时的行为,当线程中已经存在事务时,需要根据事务传播行为来进行不同的处理,handleExistingTransaction 方法中,内部使用链表的方式挂起和恢复事务,具体可参考 Spring 的统一事务模型。
/**
* Create a TransactionStatus for an existing transaction.
*/
private TransactionStatus handleExistingTransaction(
TransactionDefinition definition, Object transaction, boolean debugEnabled)
throws TransactionException {
// 对于PROPAGATION_NEVER这种传播机制,当前线程已经存在事务时直接抛异常
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NEVER) {
throw new IllegalTransactionStateException(
"Existing transaction found for transaction marked with propagation 'never'");
}
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NOT_SUPPORTED) {
// 挂起当前事务
Object suspendedResources = suspend(transaction);
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);
return prepareTransactionStatus(definition, null, false, newSynchronization, debugEnabled, suspendedResources);
}
// 对于PROPAGATION_REQUIRES_NEW,则直接开启一个新的事务
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_REQUIRES_NEW) {
SuspendedResourcesHolder suspendedResources = suspend(transaction); // 挂起当前事务
try {
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
DefaultTransactionStatus status = newTransactionStatus(
definition, transaction, true, newSynchronization, debugEnabled, suspendedResources); // 创建一个新的事务
doBegin(transaction, definition); // 执行新事务
prepareSynchronization(status, definition);
return status;
} catch (RuntimeException | Error beginEx) {
resumeAfterBeginException(transaction, suspendedResources, beginEx);
throw beginEx;
}
}
// 处理PROPAGATION_REQUIRES_NEW的情况
if (definition.getPropagationBehavior() == TransactionDefinition.PROPAGATION_NESTED) {
...
}
...
boolean newSynchronization = (getTransactionSynchronization() != SYNCHRONIZATION_NEVER);
return prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, null);
}
开源实现分析
Fescar
Fescar 是阿里近期开源的一个分布式事务框架,是一个对业务代码的无入侵高性能的分布式事务解决方案。其特点是;
1.其采用 XA 模型类似的解决方案,但却不需要数据库支持 XA 协议的要求;
2.优化两阶段提交,降低了资源锁定的粒度提升了并发性能;
3.自动生成补偿回滚操作,对业务零入侵;
4.全局默认隔离是"读未提交”, 并且目前最高支持的隔离基本是“读已提交”;
5.分支事务模式支持 AT 自动模式和 MT 手动模式,即可以将非数据库资源通过实现接口的方式纳入到分布式事务的管理范围内。
接入 fescar 的方式比较,使用方式可以参考官方的例子 :
1.必须使用 fescar 指定的 datasource ,因为其中自动补偿的逻辑都在 datasource 中;
2.分布式 rpc 框架中需要有传递全局 transaction id 的机制。
Fescar 的基本架构与 XA 模型的类似,但是 Fescar 在 XA 模型的基础上进行了改进,去除了对数据库对 XA 协议的支持的限制同时也保留了 XA 模型架构的灵活性,
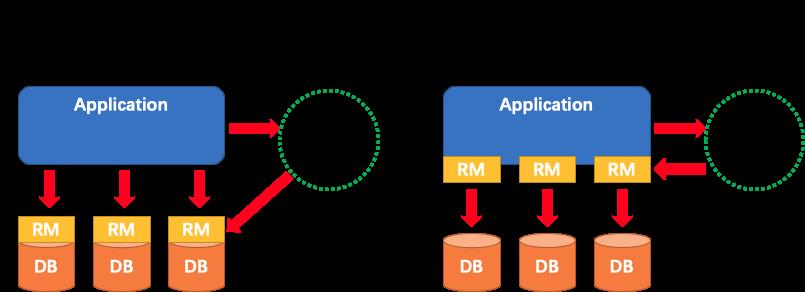
根据前面的介绍,XA 方案的 RM 实际上是在数据库层,RM 本质上就是数据库自身(通过提供支持 XA 的驱动程序来供应用使用)。而 Fescar 的 RM 是以二方包的形式作为中间件层部署在应用程序这一侧的,不依赖与数据库本身对协议的支持,当然也不需要数据库支持 XA 协议。这点对于微服务化的架构来说是非常重要的:应用层不需要为本地事务和分布式事务两类不同场景来适配两套不同的数据库驱动。这个设计,剥离了分布式事务方案对数据库在协议支持上的要求。 总体上 TM、RM 和 TC 三者之间的交互是个两阶段提交协议,如下图所示:
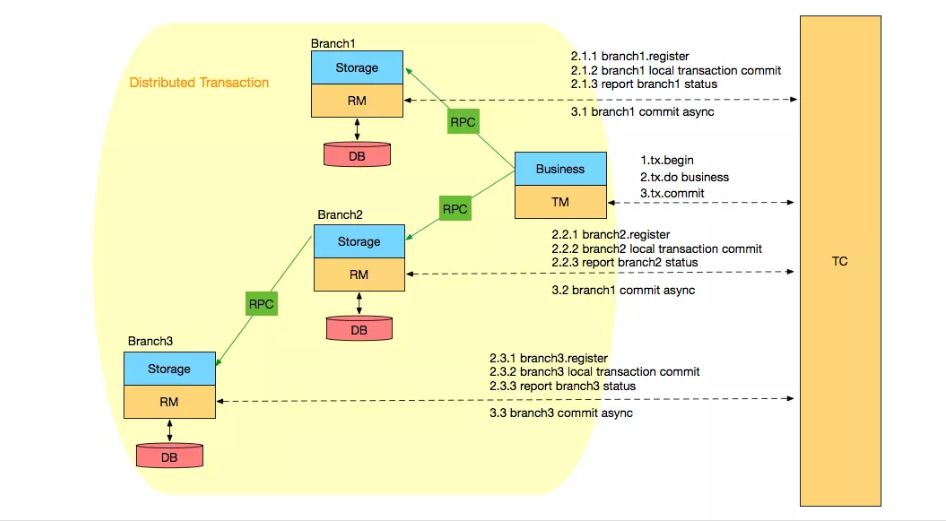
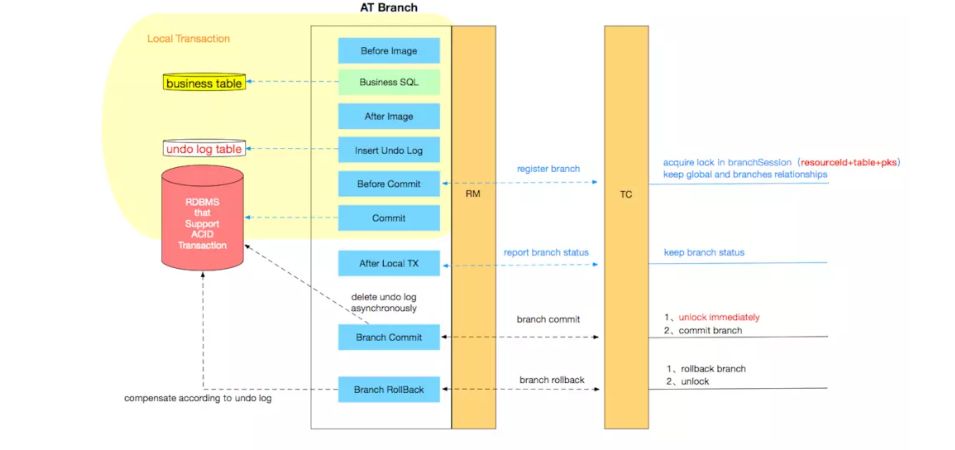
其中 TM 是全局事务的发起方、RM 是全局事务的参与方,TM 与 RM 之间是通过服务 RPC 框架进行调用同时传递全局事务 ID , TC 是事务协调器负责全局事务 ID 生成、协调各个参与方的分支事务的提交和回滚、全局锁等功能。其中 RM 通过代理增强 datasource 实现了 Fescar 的自动补偿,其基本原理如下图所示:
更详细的原理的介绍可以参考其 官方文档 和 Fescar全局锁分析。目前 Fescar 的开源程度还是比较初期,还不具备线上应用的基本功能,例如高可用集群、TCC 事务模型的支持等还未开源,预计到 5月底 可以发布第一个可用于线上的版本。 下面简单分析一下 Fescar 的源码,下载下来的源码包含如下模块:
1.fescar-common:公共工具类,命名线程以及 Fescar 的 SPI 类加载器; 2.fescar-config:用于解析 Fescar 中用到的配置文件的解析,目前只支持文件配置方式;
3.fescar-core:Fescar 的核心模块,主要是基于 Netty 实现了 TM 与 TC 、 RM 与 TC 之间的底层通信模块;
4.fescar-distribution:目前为空,应该是为后期用于支持 TC 集群准备的;
5.fescar-rm-datasource:RM 模块的实现,包括自动补偿、代理增强 datasource;
6.fescar-tm:TM 全局事务发起方模块实现;
7.fescar-server:TC 模块的实现,用于协调分支事务的提交和回滚,以及全局锁来实现全局事务隔离;
8.fescar-spring:提供了与 Spring 框架的集成相关的处理类;
9.fescar-dubbo:使用 Dubbo 这个 RPC 框架传递全局事务 id 的拦截器实现; 10.fescar-test:测试相关。
事务发起方TM的核心流程逻辑呈现在:
com.alibaba.fescar.tm.api.TransactionalTemplate ,主要流程在代码注释中已经非常清晰,
/**
* Template of executing business logic with a global transaction.
*/
public class TransactionalTemplate {
/**
* Execute object.
*
* @param business the business
* @return the object
* @throws TransactionalExecutor.ExecutionException the execution exception
*/
public Object execute(TransactionalExecutor business) throws TransactionalExecutor.ExecutionException {
// 1\. get or create a transaction
GlobalTransaction tx = GlobalTransactionContext.getCurrentOrCreate();
// 2\. begin transaction
// 与TC通信,向TC请求开启一个事务,此时TC会为其生成一个全局事务ID、开启session等操作
try {
tx.begin(business.timeout(), business.name());
} catch (TransactionException txe) {
throw new TransactionalExecutor.ExecutionException(tx, txe,
TransactionalExecutor.Code.BeginFailure);
}
Object rs = null;
try {
// Do Your Business
rs = business.execute();
} catch (Throwable ex) {
// 3\. any business exception, rollback.
// 与TC通信,向其提交全局回滚请求,后续由TC协调各个分支事务的回滚
try {
tx.rollback();
// 3.1 Successfully rolled back
throw new TransactionalExecutor.ExecutionException(tx, TransactionalExecutor.Code.RollbackDone, ex);
} catch (TransactionException txe) {
// 3.2 Failed to rollback
throw new TransactionalExecutor.ExecutionException(tx, txe,
TransactionalExecutor.Code.RollbackFailure, ex);
}
}
// 4\. everything is fine, commit.
// 与TC通信,向其提交全局提交请求,后续由TC协调各个分支事务的提交
try {
tx.commit();
} catch (TransactionException txe) {
// 4.1 Failed to commit
throw new TransactionalExecutor.ExecutionException(tx, txe,
TransactionalExecutor.Code.CommitFailure);
}
return rs;
}
}
RM 模块中是通过代理和增强 datasource 来实现的,RM 中两阶段提交的阶段一的主要的逻辑嵌入在 com.alibaba.fescar.rm.datasource.PreparedStatementProxy 和 com.alibaba.fescar.rm.datasource.ConnectionProxy 的各个方法中,例如对于普通的更新操作 PreparedStatementProxy 会将其提交给 UpdateExecutor 执行器执行,
public abstract class AbstractDMLBaseExecutor<T, S extends Statement> extends BaseTransactionalExecutor<T, S> {
private static final Logger LOGGER = LoggerFactory.getLogger(AbstractDMLBaseExecutor.class);
public AbstractDMLBaseExecutor(StatementProxy<S> statementProxy, StatementCallback<T, S> statementCallback, SQLRecognizer sqlRecognizer) {
super(statementProxy, statementCallback, sqlRecognizer);
}
@Override
public T doExecute(Object... args) throws Throwable {
AbstractConnectionProxy connectionProxy = statementProxy.getConnectionProxy();
if (connectionProxy.getAutoCommit()) {
return executeAutoCommitTrue(args); // 自动提交
} else {
return executeAutoCommitFalse(args); // 不自动提交
}
}
protected T executeAutoCommitFalse(Object[] args) throws Throwable {
// 执行前通过sql解析构造查询得到影响的行的执行前的值
TableRecords beforeImage = beforeImage();
// 执行操作
T result = statementCallback.execute(statementProxy.getTargetStatement(), args);
// 查询得到执行后的影响行的值
TableRecords afterImage = afterImage(beforeImage);
// 将undo log更新到预提交状态
statementProxy.getConnectionProxy().prepareUndoLog(sqlRecognizer.getSQLType(), sqlRecognizer.getTableName(), beforeImage, afterImage);
return result;
}
protected T executeAutoCommitTrue(Object[] args) throws Throwable {
T result = null;
AbstractConnectionProxy connectionProxy = statementProxy.getConnectionProxy();
LockRetryController lockRetryController = new LockRetryController();
try {
// 先将自动提交设置为非自动提交
connectionProxy.setAutoCommit(false);
while (true) {
try {
// 执行非自动提交逻辑
result = executeAutoCommitFalse(args);
// 提交
connectionProxy.commit();
break;
} catch (LockConflictException lockConflict) {
lockRetryController.sleep(lockConflict);
}
}
} catch (Exception e) {
...
}
finally {
// 恢复为自动提交
connectionProxy.setAutoCommit(true);
}
return result;
}
protected abstract TableRecords beforeImage() throws SQLException;
protected abstract TableRecords afterImage(TableRecords beforeImage) throws SQLException;
}
阶段一的真正的提交逻辑流程在 ConnectionProxy 中,
@Override
public void commit() throws SQLException {
if (context.inGlobalTransaction()) { // 在全局事务中
try {
// 与TC通信,向TC注册分支事务
register();
} catch (TransactionException e) {
recognizeLockKeyConflictException(e);
}
try {
if (context.hasUndoLog()) {
// 写入undo log到表中
UndoLogManager.flushUndoLogs(this);
}
// 本地事务直接提交
targetConnection.commit();
} catch (Throwable ex) {
// 向TC报告分支提交执行状态为失败
report(false);
if (ex instanceof SQLException) {
throw (SQLException) ex;
} else {
throw new SQLException(ex);
}
}
// 向TC报告分支提交执行状态为成功
report(true);
context.reset();
} else {
// 不在全局事务中的为了不影响性能直接提交
targetConnection.commit();
}
}
当 RM 准备提交时,会向 TC 注册分支事务,其逻辑如下:
public Long branchRegister(BranchType branchType, String resourceId, String clientId, String xid, String lockKeys) throws TransactionException {
GlobalSession globalSession = assertGlobalSession(XID.getTransactionId(xid), GlobalStatus.Begin);
// 构建分支事务session
BranchSession branchSession = new BranchSession();
branchSession.setTransactionId(XID.getTransactionId(xid));
branchSession.setBranchId(UUIDGenerator.generateUUID());
branchSession.setApplicationId(globalSession.getApplicationId());
branchSession.setTxServiceGroup(globalSession.getTransactionServiceGroup());
branchSession.setBranchType(branchType);
branchSession.setResourceId(resourceId);
branchSession.setLockKey(lockKeys);
branchSession.setClientId(clientId);
// 回去全局锁
if (!branchSession.lock()) {
throw new TransactionException(LockKeyConflict);
}
try {
// 添加到全局事务seesion中
globalSession.addBranch(branchSession);
} catch (RuntimeException ex) {
throw new TransactionException(FailedToAddBranch);
}
return branchSession.getBranchId();
}
这里获取锁就是全局排它锁,用于解决全局事务隔离性的问题,锁的存储在 com.alibaba.fescar.server.lock.DefaultLockManagerImpl 中,
private static final ConcurrentHashMap<String, ConcurrentHashMap<String, ConcurrentHashMap<Integer, Map<String, Long>>>> LOCK_MAP = new ConcurrentHashMap<~>();
其结构如下,
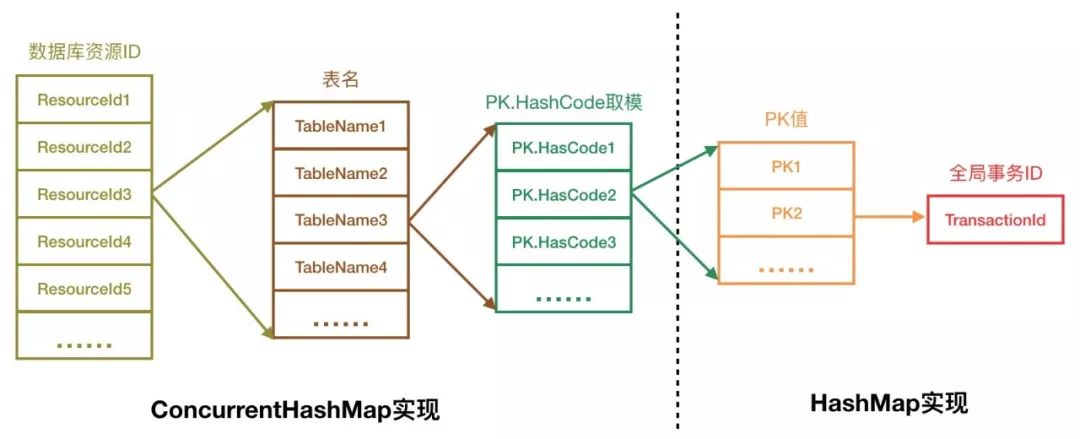
其中 PK 是指 Primary Key 主键值,构建 PK 的代码位于 RM 模块中,所以 Fescar 中全局锁的粒度是行锁,
private String buildLockKey(TableRecords rowsIncludingPK) {
if (rowsIncludingPK.size() == 0) {
return null;
}
StringBuilder sb = new StringBuilder();
sb.append(rowsIncludingPK.getTableMeta().getTableName());
sb.append(":");
boolean flag = false;
for (Field field : rowsIncludingPK.pkRows()) {
if (flag) {
sb.append(",");
} else {
flag = true;
}
sb.append(field.getValue());
}
return sb.toString();
}
上面简单的介绍了两阶段提交的阶段一的主要过程,阶段二的过程在 TC 收集完分支事务的状态后,由 TM 向 TC 发送提交或者回滚的操作,TC 根据全局事务 ID 将各个分支事务 RM 发送提交或者回滚的请求。对于分支阶段二提交过程逻辑为,
public class RMHandlerAT extends AbstractRMHandlerAT implements RMInboundHandler, TransactionMessageHandler {
@Override
protected void doBranchCommit(BranchCommitRequest request, BranchCommitResponse response) throws TransactionException {
String xid = request.getXid();
long branchId = request.getBranchId();
String resourceId = request.getResourceId();
String applicationData = request.getApplicationData();
LOGGER.info("AT Branch committing: " + xid + " " + branchId + " " + resourceId + " " + applicationData);
BranchStatus status = dataSourceManager.branchCommit(xid, branchId, resourceId, applicationData);
response.setBranchStatus(status);
LOGGER.info("AT Branch commit result: " + status);
}
}
public class DataSourceManager implements ResourceManager {
@Override
public BranchStatus branchCommit(String xid, long branchId, String resourceId, String applicationData) throws TransactionException {
// 异步执行
return asyncWorker.branchCommit(xid, branchId, resourceId, applicationData);
}
}
public class AsyncWorker implements ResourceManagerInbound {
@Override
public BranchStatus branchCommit(String xid, long branchId, String resourceId, String applicationData) throws TransactionException {
if (ASYNC_COMMIT_BUFFER.size() < ASYNC_COMMIT_BUFFER_LIMIT) {
// 添加到ASYNC_COMMIT_BUFFER队列中,由定时任务定期执行undo log的清理工作
ASYNC_COMMIT_BUFFER.add(new Phase2Context(xid, branchId, resourceId, applicationData));
} else {
LOGGER.warn("Async commit buffer is FULL. Rejected branch [" + branchId + "/" + xid + "] will be handled by housekeeping later.");
}
return BranchStatus.PhaseTwo_Committed;
}
}
回滚过程与提交不同,回滚过程是同步执行的,
public class RMHandlerAT extends AbstractRMHandlerAT implements RMInboundHandler, TransactionMessageHandler {
@Override
protected void doBranchRollback(BranchRollbackRequest request, BranchRollbackResponse response) throws TransactionException {
String xid = request.getXid();
long branchId = request.getBranchId();
String resourceId = request.getResourceId();
String applicationData = request.getApplicationData();
LOGGER.info("AT Branch rolling back: " + xid + " " + branchId + " " + resourceId);
BranchStatus status = dataSourceManager.branchRollback(xid, branchId, resourceId, applicationData);
response.setBranchStatus(status);
LOGGER.info("AT Branch rollback result: " + status);
}
}
public class DataSourceManager implements ResourceManager {
@Override
public BranchStatus branchRollback(String xid, long branchId, String resourceId, String applicationData) throws TransactionException {
DataSourceProxy dataSourceProxy = get(resourceId);
if (dataSourceProxy == null) {
throw new ShouldNeverHappenException();
}
try {
// 同步执行,使用undo log回滚事务
UndoLogManager.undo(dataSourceProxy, xid, branchId);
} catch (TransactionException te) {
if (te.getCode() == TransactionExceptionCode.BranchRollbackFailed_Unretriable) {
return BranchStatus.PhaseTwo_RollbackFailed_Unretryable;
} else {
return BranchStatus.PhaseTwo_RollbackFailed_Retryable;
}
}
return BranchStatus.PhaseTwo_Rollbacked;
}
}
到此就分析完了整个 Fescar 的分布式事务处理的主要流程。
其他
Servicecomb
Servicecomb sagas 是华为开源的一个基于 sagas 模型实现的分布式事务解决方案,并且已经集成到另一个分布式数据库中间件 sharding-sphere 作为其分布式事务的处理器,根据官网的介绍 Servicecomb sagas 具有如下特点:
1.高可用:支持高可用的集群模式部署;
2.高可靠:所有的关键事务事件都持久化存储在数据库中;
3.高性能:事务事件是通过高性能 gRPC 来上报的,且事务的请求和响应消息都是通过 Kyro 进行序列化和反序列化;
4.低侵入:仅需 2-3 个注解和编写对应的补偿方法即可引入分布式事务;
5.部署简单:支持通过容器(Docker)进行快速部署和交付;
6.补偿机制灵活:支持前向恢复(重试)及后向恢复(补偿)功能;
7.扩展简单:基于 Pack 架构很容易实现多种协调协议,目前支持 TCC、Saga 协议,未来还可以添加其他协议支持。
EasyTransaction
EasyTransaction 这个开源解决方案将多种事务模型的实现进行了整合,依赖并和 spring 的事务模型进行结合,提供了许多的特性:
1.一个框架包含多种事务形态,一个框架搞定所有类型的事务;
2.多种事务形态可混合使用;
3.高性能:大多数业务系统瓶颈在业务数据库,若不启用框架的幂等功能,对业务数据库的额外消耗仅为写入 25 字节的一行;
4.可选的框架自带幂等实现及调用错乱次序处理,大幅减轻业务开发工作量,但启用的同时会在业务数据库增加一条幂等控制行;
5.业务代码可实现完全无入侵;
6.支持嵌套事务;
7.无需额外部署协调者,不同 APP 的服务协调自身发起的事务,也避免了单点故障;
8.分布式事务 ID 可关联业务 ID ,业务类型,APPID,便于监控各个业务的分布式事务执行情况;
9.整合并大幅改造阿里 Fescar 的自动补偿核心功能,提供分布式高可用的协调功能(Alpha)。
实现原理和实用性还需要深入的分析。
总结
本文简单分析事务的概念,以及事务的 ACID 属性,以及本地事务中 ACID 的实现基本原理,基于本地事务扩展而来的分布式事务问题的解决的基本模型,并简单分析了一些目前开源的分布式事务框架。总的来说,分布式事务理论方面已经比较成熟,而且在很多大型分布式系统中也有广泛的应用和实践,不过考虑到性能和具体的业务场景,其实并没有一种通用的分布式事务解决方案,因此开源的框架能直接拿来用的很少,基本上需要进行改造或者功能的完善,或者使用组合的方式运用在具体的业务场景中。
参考资料
1.概念:
https://en.wikipedia.org/wiki/Distributedtransaction
2.入门:
https://juejin.im/post/5b5a0bf9f265da0f6523913b
3.开源框架 EasyTransaction:
https://github.com/QNJR-GROUP/EasyTransaction
4.开源框架 shardingsphere:
https://github.com/apache/incubator-shardingsphere
5.开源框架 fescar:
https://github.com/alibaba/fescar
6.fescar的概览:
https://github.com/alibaba/fescar/wiki/%E6%A6%82%E8%A7%88
7.框架的对比:
https://www.cnblogs.com/skyesx/p/10041923.html 、https://www.cnblogs.com/skyesx/p/9697817.html
8.支付宝ppt:
sd2cdtpbyalipaychenglifinal-1228704068777723-9.pdf
9.sagas:
http://servicecomb.apache.org/cn/docs/distributed-transactions-saga-implementation/
10.sagas简介:
https://www.jianshu.com/p/e4b662407c66
11.分布式事务解决方案选型:
https://mp.weixin.qq.com/s/Vwh4RuwEocsMpOFyvmFJfw
12.mysql事务:
https://time.geekbang.org/column/article/68633
13.mysql中事务与锁的理解和实践:
https://www.imooc.com/article/17291
14.mysql事务中隔离级别的实现原理分析:
https://www.imooc.com/article/17290
15.mysql一致性的理解:
https://www.zhihu.com/question/56073588/answer/253106572
16.事务概念:
https://books.google.nl/books?id=zFheDgAAQBAJ&pg=PA221&lpg=PA221#v=onepage&q&f=false
17.隔离级别在mysql中的实现分析:
https://blog.pythian.com/understanding-mysql-isolation-levels-repeatable-read/
18.mysql事务的实现分析:
https://draveness.me/mysql-transaction
19.spring 事务框架:
https://zhuanlan.zhihu.com/p/38772486
20.spring声明式事务源码:
http://www.linkedkeeper.com/1045.html
21.xa事务:
https://docs.oracle.com/cd/E1188201/timesten.112/e21637/xa_dtp.htm#TTCDV328
22.fescar分析:
http://www.iocoder.cn/Fescar/Afei/GTS-decryption-principles-architecture-and-features-of-GTS/
23.fescar锁:
https://www.jishuwen.com/d/2Eaz
以上是关于分布式事务浅析的主要内容,如果未能解决你的问题,请参考以下文章