排序小结
Posted weibao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了排序小结相关的知识,希望对你有一定的参考价值。
计数排序:最差运行时间复杂度:,平均:,k是数字范围区间长度,n是数组长度。
这是一种稳定的线性时间排序
如果要排序的内容已知其范围,比如要排序的所有数字都是1~100之间的数(使用计数排序是最好的选择)
KEY-IDEA:由于计数的范围已经确定,因此,可以开辟一个额外的空间来记录所有数字出现的次数,然后,直接按照数字的出现的顺序,就能够得到该序列的排序。
特点:借用了数字的固有顺序,帮助了排序。
举个栗子:
给定一个序列:{1,2,3,4,5,6,7,8,9,0,0,0,1,2,3,4,5,6,7,8,3,2,5,6,3,1,1,5,6,6,7,8,8,9,0}
由于数字都是0~9。因此,使用一个长度为10的数组,统计0~9的数字出现的次数,直接就能知道排序的顺序。{0:4,1:4:,2:3,…,9:2} 如key=2:value=3,说明数字2在数组中出现了三次。
如果所有的元素都是只出现一次,那么可以使用位图来存储。存储办法和类似例子见《编程珠玑》第一章。
下面是维基百科的一个实现例子:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void print_arr(int *arr, int n) {
int i;
printf("%d", arr[0]);
for (i = 1; i < n; i++)
printf(" %d", arr[i]);
printf("\\n");
}
void counting_sort(int *ini_arr, int *sorted_arr, int n) {
int *count_arr = (int *) malloc(sizeof(int) * 100);
int i, j, k;
for (k = 0; k < 100; k++)
count_arr[k] = 0;
for (i = 0; i < n; i++)
count_arr[ini_arr[i]]++;
for (k = 1; k < 100; k++)
count_arr[k] += count_arr[k - 1];
for (j = n; j > 0; j--)
sorted_arr[--count_arr[ini_arr[j - 1]]] = ini_arr[j - 1];
free(count_arr);
}
int main(int argc, char **argv) {
int n = 10;
int i;
int *arr = (int *) malloc(sizeof(int) * n);
int *sorted_arr = (int *) malloc(sizeof(int) * n);
srand(time(0));
for (i = 0; i < n; i++)
arr[i] = rand() % 100;
printf("ini_array: ");
print_arr(arr, n);
counting_sort(arr, sorted_arr, n);
printf("sorted_array: ");
print_arr(sorted_arr, n);
free(arr);
free(sorted_arr);
return 0;
}
基数排序:最差运行时间复杂度,平均:,k是数字位数
KEY IDEA:将数组中的元素按位从上到下末尾对齐排好。由于一位数只有0~9,因此可以用数字的固有顺序来排序。使用链表尤为合理。举个栗子:
326 421 902 218
218 902 218 326
902 543 421 345
421 345 326 387
867 326 543 421
345 456 345 456
456 867 456 543
698 987 867 698
987 387 987 867
387 218 387 902
543 698 698 987
下面也是维基百科的例子:
int maxbit(int data[], int n) //辅助函数,求数据的最大位数
{
int maxData = data[0]; ///< 最大数
/// 先求出最大数,再求其位数,这样有原先依次每个数判断其位数,稍微优化点。
for (int i = 1; i < n; ++i)
{
if (maxData < data[i])
maxData = data[i];
}
int d = 1;
int p = 10;
while (maxData >= p)
{
//p *= 10; // Maybe overflow
maxData /= 10;
++d;
}
return d;
/* int d = 1; //保存最大的位数
int p = 10;
for(int i = 0; i < n; ++i)
{
while(data[i] >= p)
{
p *= 10;
++d;
}
}
return d;*/
}
void radixsort(int data[], int n) //基数排序
{
int d = maxbit(data, n);
int *tmp = new int[n];
int *count = new int[10]; //计数器
int i, j, k;
int radix = 1;
for(i = 1; i <= d; i++) //进行d次排序
{
for(j = 0; j < 10; j++)
count[j] = 0; //每次分配前清空计数器
for(j = 0; j < n; j++)
{
k = (data[j] / radix) % 10; //统计每个桶中的记录数
count[k]++;
}
for(j = 1; j < 10; j++)
count[j] = count[j - 1] + count[j]; //将tmp中的位置依次分配给每个桶
for(j = n - 1; j >= 0; j--) //将所有桶中记录依次收集到tmp中
{
k = (data[j] / radix) % 10;
tmp[count[k] - 1] = data[j];
count[k]--;
}
for(j = 0; j < n; j++) //将临时数组的内容复制到data中
data[j] = tmp[j];
radix = radix * 10;
}
delete []tmp;
delete []count;
}
希尔排序:最差运行时间复杂度:决定于gap的选取,平均:决定于gap的选取
,最坏时间复杂度是:
希尔排序是插入排序的一个改进版本,总的来说,它是基于下面两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
希尔排序通过将比较的全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素可以一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了(此时插入排序较快)。
例如,假设有这样一组数[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10
然后我们对每列进行排序:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45
将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ].这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45
排序之后变为:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94
最后以1步长进行排序(此时就是简单的插入排序了)。
显而易见,希尔排序的时间复杂度和步长的选择是有关系的,步长选择越好,时间复杂度越低。
下面依然是维基百科的代码:
template<typename T>
void shell_sort(T arr[], int len) {
int gap, i, j;
T temp;
for (gap = len >> 1; gap > 0; gap >>= 1)
for (i = gap; i < len; i++) {
temp = arr[i];
for (j = i - gap; j >= 0 && arr[j] > temp; j -= gap)
arr[j + gap] = arr[j];
arr[j + gap] = temp;
}
}
桶排序:最差运行时间复杂度,平均:
桶排序(Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间()。但桶排序并不是比较排序,他不受到O(n log n)下限的影响。
排序以下列程序进行:
- 设置一个定量的数组当作空桶子。
- 寻访序列,并且把项目一个一个放到对应的桶子去。
- 对每个不是空的桶子进行排序。
- 从不是空的桶子里把项目再放回原来的序列中。
我们可以理解为,桶排序实际上也是借用了数字的固有顺序,通过分组,将数据分到几个不同的区间内。而且,分组完毕以后,区间内的数字也比较少,排序的时间是常数时间复杂度。综合起来得到线性的时间复杂度。不过空间复杂度比较高,因此,需要慎用。
实例分析
设有数组 array = [29, 25, 3, 49, 9, 37, 21, 43],那么数组中最大数为 49,先设置 5 个桶,那么每个桶可存放数的范围为:0~9、10~19、20~29、30~39、40~49,然后分别将这些数放人自己所属的桶,如下图:
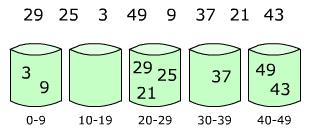
然后,分别对每个桶里面的数进行排序,或者在将数放入桶的同时用插入排序进行排序。最后,将各个桶中的数据有序的合并起来,如下图:
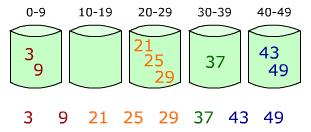
下面还是来自维基百科的代码:
假设数据分布在[0,100)之间,每个桶内部用链表表示,在数据入桶的同时插入排序。然后把各个桶中的数据合并。
#include<iterator>
#include<iostream>
#include<vector>
using namespace std;
const int BUCKET_NUM = 10;
struct ListNode{
explicit ListNode(int i=0):mData(i),mNext(NULL){}
ListNode* mNext;
int mData;
};
ListNode* insert(ListNode* head,int val){
ListNode dummyNode;
ListNode *newNode = new ListNode(val);
ListNode *pre,*curr;
dummyNode.mNext = head;
pre = &dummyNode;
curr = head;
while(NULL!=curr && curr->mData<=val){
pre = curr;
curr = curr->mNext;
}
newNode->mNext = curr;
pre->mNext = newNode;
return dummyNode.mNext;
}
ListNode* Merge(ListNode *head1,ListNode *head2){
ListNode dummyNode;
ListNode *dummy = &dummyNode;
while(NULL!=head1 && NULL!=head2){
if(head1->mData <= head2->mData){
dummy->mNext = head1;
head1 = head1->mNext;
}else{
dummy->mNext = head2;
head2 = head2->mNext;
}
dummy = dummy->mNext;
}
if(NULL!=head1) dummy->mNext = head1;
if(NULL!=head2) dummy->mNext = head2;
return dummyNode.mNext;
}
void BucketSort(int n,int arr[]){
vector<ListNode*> buckets(BUCKET_NUM,(ListNode*)(0));
for(int i=0;i<n;++i){
int index = arr[i]/BUCKET_NUM;
ListNode *head = buckets.at(index);
buckets.at(index) = insert(head,arr[i]);
}
ListNode *head = buckets.at(0);
for(int i=1;i<BUCKET_NUM;++i){
head = Merge(head,buckets.at(i));
}
for(int i=0;i<n;++i){
arr[i] = head->mData;
head = head->mNext;
}
}
插入排序:最差运行时间复杂度,平均:
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
由于比较的次数比较多,因此,插入排序的时间复杂度是
以为我还会引用维基百科的代码么,你们想错了,下面是我写的代码:
void insertionSort (int *a, int len){
int key=0,i=0;
for(int j=1;j<len;j++){
key=a[j];
i=j-1;
while(i>=0 && a[i]>key){
a[i+1]=a[i];
i--;
}
a[i+1]=key;
}
}
归并排序:最差运行时间复杂度,平均:
归并排序被认为是分治法的典型,归并排序的核心思想见下图:
[6 2 4 1 5 7 8 3]
[2 6 1 4] [5 7 8 3]
[2 6] [1 4] [5,7] [8,3]
[2] [6] [1] [4] [5] [7] [8] [3]
[2 6] [1 4] [5 7] [3 8]
[1 2 4 6] [3 5 7 8]
[1 2 3 4 5 6 7 8]
上面的图形象化地描述了归并排序的过程。
通过将数据集一次次的划分,最终变成一个个更小的问题,然后,将这些小问题逐步击破,最后,通过合并的办法,让小问题的答案组合成大问题的答案,这就是归并排序所体现出来的含义。
而这,也是分治法的核心。
惯例,下面的是我写的代码,献丑了:
void merge(int* a,int begin,int end,int mid){
vector<int> L,R;
for(int i=begin;i<mid+1;i++) L.push_back(a[i]);
for(int j=mid+1;j<end+1;j++) R.push_back(a[j]);
L.push_back(INT_MAX);
R.push_back(INT_MAX);
int i=0,j=0;
for(int t=begin;t<end+1;t++){
if(L[i]<=R[j]) a[t]=L[i++];
else a[t]=R[j++];
}
}
void mergeSort(int* a,int begin,int end){
if(begin<end){
int mid=begin+(end-begin)/2;
mergeSort(a,begin,mid);
mergeSort(a,mid+1,end);
merge(a,begin,end,mid);
}
}
堆排序:最差运行时间复杂度,平均:---
要理解堆排序,首先得清楚堆这种数据结构的性质:
堆分为两种,最大堆和最小堆。(这里仅讨论二叉堆)
最大堆的特点是:根节点的值是整个堆里面最大的值,举个栗子:(最大堆)
[15]
[13] [14]
[9] [10] [11] [12]
直接相连的节点中,位于上一层节点的值都会比下一层节点的值要大。
而堆排序(用最大堆实现)的原理是:每一次都将最末位的叶子节点和根节点交换,然后,调整除去末位叶子节点部分,使得这些部分依然还是一个最大堆。栗子如下:
[15] [12]
[13] [14] [13] [14]
[9] [10] [11] [12] [9] [10] [11] [15]
然后,调整除去[15]剩余部分,得到新的最大堆:
[14] [9]
[13] [12] ....... [10] [11]
[9] [10] [11] [15] [12] [13] [14] [15]
如此迭代,最终会得到如上图右边的结果:
废话就不多说了,下面又到了献丑时间,实现代码如下:
void max_heapify(int a[] , int start, int end) {
int dad=start;
int son=dad*2+1;
while(son<end){
(son+1<end && a[son]<a[son+1])?++son:son;
if (a[dad]>a[son]) return;
else{
swap(a[son],a[dad]);
dad=son;
son=dad*2+1;
}
}
}
void heapSort(int* a, int len) {
for (int i = len / 2 - 1; i >= 0; i--)
max_heapify(a, i, len);
for (int i = len - 1; i > 0; i--) {
swap(a[0], a[i]);
max_heapify(a, 0, i);
}
}
写到这里,终于来到了重点。压轴的是工业上用的最广泛,面试中让人又爱又恨欲罢不能的快排:
快速排序:最差运行时间复杂度,平均:(期望)
话不用多说,先上图吧:
[3 7 8 5 2 1 9 5 4] 数组中随机选择一个元素,如现在选择了key=5
[3 7 8 4 2 1 9 5 5] 将其和末尾元素交换
[3 4 2 1 5 7 9 8 5] 将0~7位置的元素划分成小于5和大于5的部分
[3 4 2 1 5 5 9 8 7] 末位元素和大于5部分的首位元素交换
上面描述的是一次partition的过程,而快排就是将元素分成大于key和小于key的部分,然后,将这两部分(不包括key)[3 4 2 1 5] 和 [9 8 7]作为两个子问题递归解决。
下面又是show 代码时间:
int partition(int* a,int begin,int end){
int key=a[end];
int i=begin-1;
for(int j=begin;j<end;j++){
if(a[j]<=key){
i++;
swap(a[i],a[j]);
}
}
swap(a[i+1],a[end]);
return i+1;
}
int randomized_partition(int* a,int begin,int end){
int i=(rand() % (end-begin+1))+ begin;
//cout<<i<<endl;
swap(a[i],a[end]);
return partition(a,begin,end);
}
void quickSort(int* a,int begin,int end){
if(begin<end){
int q=randomized_partition(a,begin,end);
quickSort(a,begin,q-1);
quickSort(a,q+1,end);
}
}
参考文献:1、维基百科
2、《算法导论》
转载请注明源地址:http://www.cnblogs.com/weibao/p/5561139.html
有任何问题请联系:weibao798@gmail.com
以上是关于排序小结的主要内容,如果未能解决你的问题,请参考以下文章
十大排序算法-快排-希尔-堆排-归并-冒泡-桶排-选择-插入-计数-基数-1