深入Java集合学习系列:Hashtable的实现原理
Posted 读书使人进步
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入Java集合学习系列:Hashtable的实现原理相关的知识,希望对你有一定的参考价值。
第1部分 Hashtable介绍
和HashMap一样,Hashtable也是一个散列表,它存储的内容是键值对(key-value)映射。Hashtable继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。Hashtable的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。Hashtable的实例有两个参数影响其性能:初始容量和加载因子。容量是哈希表桶的数量,初始容量就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用rehash方法的具体细节则依赖于该实现。通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间。
第2部分 Hashtable数据结构
java.lang.Object
↳ java.util.Dictionary<K, V>
↳ java.util.Hashtable<K, V>
public class Hashtable<K,V> extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable { }
Hashtable与Map关系如下图:
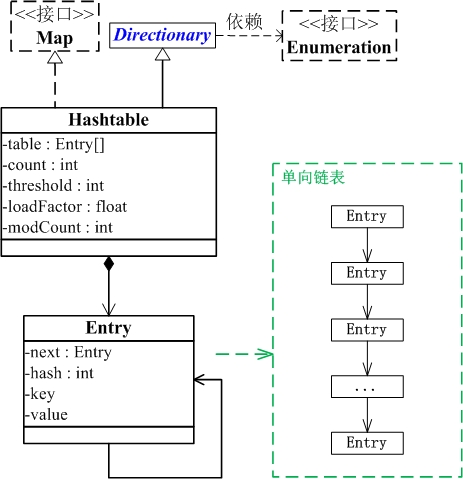
从图中可以看出:
(01) Hashtable继承于Dictionary类,实现了Map接口。Map是"key-value键值对"接口,Dictionary是声明了操作"键值对"函数接口的抽象类。
(02) Hashtable是通过"拉链法"实现的哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。count是Hashtable的大小,它是Hashtable保存的键值对的数量。threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。loadFactor就是加载因子。 modCount是用来实现fail-fast机制的
第3部分 Hashtable源码解析(基于JDK1.6.0_45)


package java.util;
import java.io.*;
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
// Hashtable保存key-value的数组。
// Hashtable是采用拉链法实现的,每一个Entry本质上是一个单向链表
private transient Entry[] table;
// Hashtable中元素的实际数量
private transient int count;
// 阈值,用于判断是否需要调整Hashtable的容量(threshold = 容量*加载因子)
private int threshold;
// 加载因子
private float loadFactor;
// Hashtable被改变的次数
private transient int modCount = 0;
// 序列版本号
private static final long serialVersionUID = 1421746759512286392L;
// 指定“容量大小”和“加载因子”的构造函数
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)(initialCapacity * loadFactor);
}
// 指定“容量大小”的构造函数
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
// 默认构造函数。
public Hashtable() {
// 默认构造函数,指定的容量大小是11;加载因子是0.75
this(11, 0.75f);
}
// 包含“子Map”的构造函数
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
// 将“子Map”的全部元素都添加到Hashtable中
putAll(t);
}
public synchronized int size() {
return count;
}
public synchronized boolean isEmpty() {
return count == 0;
}
// 返回“所有key”的枚举对象
public synchronized Enumeration<K> keys() {
return this.<K>getEnumeration(KEYS);
}
// 返回“所有value”的枚举对象
public synchronized Enumeration<V> elements() {
return this.<V>getEnumeration(VALUES);
}
// 判断Hashtable是否包含“值(value)”
public synchronized boolean contains(Object value) {
// Hashtable中“键值对”的value不能是null,
// 若是null的话,抛出异常!
if (value == null) {
throw new NullPointerException();
}
// 从后向前遍历table数组中的元素(Entry)
// 对于每个Entry(单向链表),逐个遍历,判断节点的值是否等于value
Entry tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
public boolean containsValue(Object value) {
return contains(value);
}
// 判断Hashtable是否包含key
public synchronized boolean containsKey(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值,
// % tab.length 的目的是防止数据越界
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false;
}
// 返回key对应的value,没有的话返回null
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
// 计算索引值,
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
// 调整Hashtable的长度,将长度变成原来的(2倍+1)
// (01) 将“旧的Entry数组”赋值给一个临时变量。
// (02) 创建一个“新的Entry数组”,并赋值给“旧的Entry数组”
// (03) 将“Hashtable”中的全部元素依次添加到“新的Entry数组”中
protected void rehash() {
int oldCapacity = table.length;
Entry[] oldMap = table;
int newCapacity = oldCapacity * 2 + 1;
Entry[] newMap = new Entry[newCapacity];
modCount++;
threshold = (int)(newCapacity * loadFactor);
table = newMap;
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = newMap[index];
newMap[index] = e;
}
}
}
// 将“key-value”添加到Hashtable中
public synchronized V put(K key, V value) {
// Hashtable中不能插入value为null的元素!!!
if (value == null) {
throw new NullPointerException();
}
// 若“Hashtable中已存在键为key的键值对”,
// 则用“新的value”替换“旧的value”
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
// 若“Hashtable中不存在键为key的键值对”,
// (01) 将“修改统计数”+1
modCount++;
// (02) 若“Hashtable实际容量” > “阈值”(阈值=总的容量 * 加载因子)
// 则调整Hashtable的大小
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// (03) 将“Hashtable中index”位置的Entry(链表)保存到e中
Entry<K,V> e = tab[index];
// (04) 创建“新的Entry节点”,并将“新的Entry”插入“Hashtable的index位置”,并设置e为“新的Entry”的下一个元素(即“新Entry”为链表表头)。
tab[index] = new Entry<K,V>(hash, key, value, e);
// (05) 将“Hashtable的实际容量”+1
count++;
return null;
}
// 删除Hashtable中键为key的元素
public synchronized V remove(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
// 找到“key对应的Entry(链表)”
// 然后在链表中找出要删除的节点,并删除该节点。
for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
// 将“Map(t)”的中全部元素逐一添加到Hashtable中
public synchronized void putAll(Map<? extends K, ? extends V> t) {
for (Map.Entry<? extends K, ? extends V> e : t.entrySet())
put(e.getKey(), e.getValue());
}
// 清空Hashtable
// 将Hashtable的table数组的值全部设为null
public synchronized void clear() {
Entry tab[] = table;
modCount++;
for (int index = tab.length; --index >= 0; )
tab[index] = null;
count = 0;
}
// 克隆一个Hashtable,并以Object的形式返回。
public synchronized Object clone() {
try {
Hashtable<K,V> t = (Hashtable<K,V>) super.clone();
t.table = new Entry[table.length];
for (int i = table.length ; i-- > 0 ; ) {
t.table[i] = (table[i] != null)
? (Entry<K,V>) table[i].clone() : null;
}
t.keySet = null;
t.entrySet = null;
t.values = null;
t.modCount = 0;
return t;
} catch (CloneNotSupportedException e) {
// this shouldn\'t happen, since we are Cloneable
throw new InternalError();
}
}
public synchronized String toString() {
int max = size() - 1;
if (max == -1)
return "{}";
StringBuilder sb = new StringBuilder();
Iterator<Map.Entry<K,V>> it = entrySet().iterator();
sb.append(\'{\');
for (int i = 0; ; i++) {
Map.Entry<K,V> e = it.next();
K key = e.getKey();
V value = e.getValue();
sb.append(key == this ? "(this Map)" : key.toString());
sb.append(\'=\');
sb.append(value == this ? "(this Map)" : value.toString());
if (i == max)
return sb.append(\'}\').toString();
sb.append(", ");
}
}
// 获取Hashtable的枚举类对象
// 若Hashtable的实际大小为0,则返回“空枚举类”对象;
// 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口)
private <T> Enumeration<T> getEnumeration(int type) {
if (count == 0) {
return (Enumeration<T>)emptyEnumerator;
} else {
return new Enumerator<T>(type, false);
}
}
// 获取Hashtable的迭代器
// 若Hashtable的实际大小为0,则返回“空迭代器”对象;
// 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口)
private <T> Iterator<T> getIterator(int type) {
if (count == 0) {
return (Iterator<T>) emptyIterator;
} else {
return new Enumerator<T>(type, true);
}
}
// Hashtable的“key的集合”。它是一个Set,意味着没有重复元素
private transient volatile Set<K> keySet = null;
// Hashtable的“key-value的集合”。它是一个Set,意味着没有重复元素
private transient volatile Set<Map.Entry<K,V>> entrySet = null;
// Hashtable的“key-value的集合”。它是一个Collection,意味着可以有重复元素
private transient volatile Collection<V> values = null;
// 返回一个被synchronizedSet封装后的KeySet对象
// synchronizedSet封装的目的是对KeySet的所有方法都添加synchronized,实现多线程同步
public Set<K> keySet() {
if (keySet == null)
keySet = Collections.synchronizedSet(new KeySet(), this);
return keySet;
}
// Hashtable的Key的Set集合。
// KeySet继承于AbstractSet,所以,KeySet中的元素没有重复的。
private class KeySet extends AbstractSet<K> {
public Iterator<K> iterator() {
return getIterator(KEYS);
}
public int size() {
return count;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return Hashtable.this.remove(o) != null;
}
public void clear() {
Hashtable.this.clear();
}
}
// 返回一个被synchronizedSet封装后的EntrySet对象
// synchronizedSet封装的目的是对EntrySet的所有方法都添加synchronized,实现多线程同步
public Set<Map.Entry<K,V>> entrySet() {
if (entrySet==null)
entrySet = Collections.synchronizedSet(new EntrySet(), this);
return entrySet;
}
// Hashtable的Entry的Set集合。
// EntrySet继承于AbstractSet,所以,EntrySet中的元素没有重复的。
private class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return getIterator(ENTRIES);
}
public boolean add(Map.Entry<K,V> o) {
return super.add(o);
}
// 查找EntrySet中是否包含Object(0)
// 首先,在table中找到o对应的Entry(Entry是一个单向链表)
// 然后,查找Entry链表中是否存在Object
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry entry = (Map.Entry)o;
Object key = entry.getKey();
Entry[] tab = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry e = tab[index]; e != null; e = e.next)
if (e.hash==hash && e.equals(entry))
return true;
return false;
}
// 删除元素Object(0)
// 首先,在table中找到o对应的Entry(Entry是一个单向链表)
// 然后,删除链表中的元素Object
public boolean remove(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K,V> entry = (Map.Entry<K,V>) o;
K key = entry.getKey();
Entry[] tab = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index], prev = null; e != null;
prev = e, e = e.next) {
if (e.hash==hash && e.equals(entry)) {
modCount++;
if (prev != null)
prev.next = e.next;
else
tab[index] = e.next;
count--;
e.value = null;
return true;
}
}
return false;
}
public int size() {
return count;
}
public void clear() {
Hashtable.this.clear();
}
}
// 返回一个被synchronizedCollection封装后的ValueCollection对象
// synchronizedCollection封装的目的是对ValueCollection的所有方法都添加synchronized,实现多线程同步
public Collection<V> values() {
if (values==null)
values = Collections.synchronizedCollection(new ValueCollection(),
this);
return values;
}
// Hashtable的value的Collection集合。
// ValueCollection继承于AbstractCollection,所以,ValueCollection中的元素可以重复的。
private class ValueCollection extends AbstractCollection<V> {
public Iterator<V> iterator() {
return getIterator(VALUES);
}
public int size() {
return count;
}
public boolean contains(Object o) {
return containsValue(o);
}
public void clear() {
Hashtable.this.clear();
}
}
// 重新equals()函数
// 若两个Hashtable的所有key-value键值对都相等,则判断它们两个相等
public synchronized boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Map))
return false;
Map<K,V> t = (Map<K,V>) o;
if (t.size() != size())
return false;
try {
// 通过迭代器依次取出当前Hashtable的key-value键值对
// 并判断该键值对,存在于Hashtable(o)中。
// 若不存在,则立即返回false;否则,遍历完“当前Hashtable”并返回true。
Iterator<Map.Entry<K,V>> i = entrySet().iterator();
while (i.hasNext()) {
Map.Entry<K,V> e = i.next();
K key = e.getKey();
V value = e.getValue();
if (value == null) {
if (!(t.get(key)==null && t.containsKey(key)))
return false;
} else {
if (!value.equals(t.get(key)))
return false;
}
}
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
return true;
}
// 计算Hashtable的哈希值
// 若 Hashtable的实际大小为0 或者 加载因子<0,则返回0。
// 否则,返回“Hashtable中的每个Entry的key和value的异或值 的总和”。
public synchronized int hashCode() {
int h = 0;
if (count == 0 || loadFactor < 0)
return h; // Returns zero
loadFactor = -loadFactor; // Mark hashCode computation in progress
Entry[] tab = table;
for (int i = 0; i < tab.length; i++)
for (Entry e = tab[i]; e != null; e = e.next)
h += e.key.hashCode() ^ e.value.hashCode();
loadFactor = -loadFactor; // Mark hashCode computation complete
return h;
}
// java.io.Serializable的写入函数
// 将Hashtable的“总的容量,实际容量,所有的Entry”都写入到输出流中
private synchronized void writeObject(java.io.ObjectOutputStream s)
throws IOException
{
// Write out the length, threshold, loadfactor
s.defaultWriteObject();
// Write out length, count of elements and then the key/value objects
s.writeInt(table.length);
s.writeInt(count);
for (int index = table.length-1; index >= 0; index--) {
Entry entry = table[index];
while (entry != null) {
s.writeObject(entry.key);
s.writeObject(entry.value);
entry = entry.next;
}
}
}
// java.io.Serializable的读取函数:根据写入方式读出
// 将Hashtable的“总的容量,实际容量,所有的Entry”依次读出
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException
{
// Read in the length, threshold, and loadfactor
s.defaultReadObject();
// Read the original length of the array and number of elements
int origlength = s.readInt();
int elements = s.readInt();
// Compute new size with a bit of room 5% to grow but
// no larger than the original size. Make the length
// odd if it\'s large enough, this helps distribute the entries.
// Guard against the length ending up zero, that\'s not valid.
int length = (以上是关于深入Java集合学习系列:Hashtable的实现原理的主要内容,如果未能解决你的问题,请参考以下文章
Java 集合深入理解 (十四) :Hashtable实现原理研究
深入理解JAVA集合系列二:ConcurrentHashMap源码解读