Java 集合深入理解 (十四) :Hashtable实现原理研究
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 集合深入理解 (十四) :Hashtable实现原理研究相关的知识,希望对你有一定的参考价值。
Java 集合深入理解 (十一) :HashMap之实现原理及hash碰撞
前言
之前分析的hashmap的实现原理确实在jdk的1.8后经过Doug Lea 大牛的优化,非常适合我们学习优秀算法,以及理解其中的思想;
我们继续看一下hashtable,虽然hashtable jdk已经不推荐使用,但是我们看源码,看出早期java实现哈希表的基本思想;包括 实现线程安全的方式,及解决hash碰撞,早期扩容方式,不允许数据为空
实现示例
public static void main(String[] args) {
System.out.println("--------------Hashtable--------------");
Hashtable<String, String> map=new Hashtable();
map.put("1", "1");
map.put("6", "6");
map.put("3", "3");
map.put("7", "7");
map.put("2", "2");
map.keySet().stream().forEach(m->{
System.out.println(map.get(m));
});
System.out.println("--------------hashmap--------------");
HashMap maps=new HashMap();
maps.put("1", "1");
maps.put("6", "6");
maps.put("3", "3");
maps.put("7", "7");
maps.put("2", "2");
maps.keySet().stream().forEach(m->{
System.out.println(maps.get(m));
});
}
--------------Hashtable--------------
6
3
2
1
7
--------------hashmap--------------
1
2
3
6
7
//规定好容量
public static void main(String[] args) {
System.out.println("--------------Hashtable--------------");
Hashtable<String, String> map=new Hashtable(16);
map.put("1", "1");
map.put("6", "6");
map.put("3", "3");
map.put("7", "7");
map.put("2", "2");
map.keySet().stream().forEach(m->{
System.out.println(map.get(m));
});
System.out.println("--------------hashmap--------------");
HashMap maps=new HashMap();
maps.put("1", "1");
maps.put("6", "6");
maps.put("3", "3");
maps.put("7", "7");
maps.put("2", "2");
maps.keySet().stream().forEach(m->{
System.out.println(maps.get(m));
});
}
--------------Hashtable--------------
7
6
3
2
1
--------------hashmap--------------
1
2
3
6
7
从上面对比出hashmap和hashtable区别
- 首先hashtable是线程安全的,这个就不用写测试用例可以证明了
- 第一次做测试时,为什么hashtable看起来无序,而hashmap看起来有序,关键在在于桶的长度,hashtable默认是11,而hashtable保证了2次幂
- hashmap 和hashtable最后顺序不一致的问题, 因为hashtable 的提供的迭代器,是后往前遍历的
实现原理
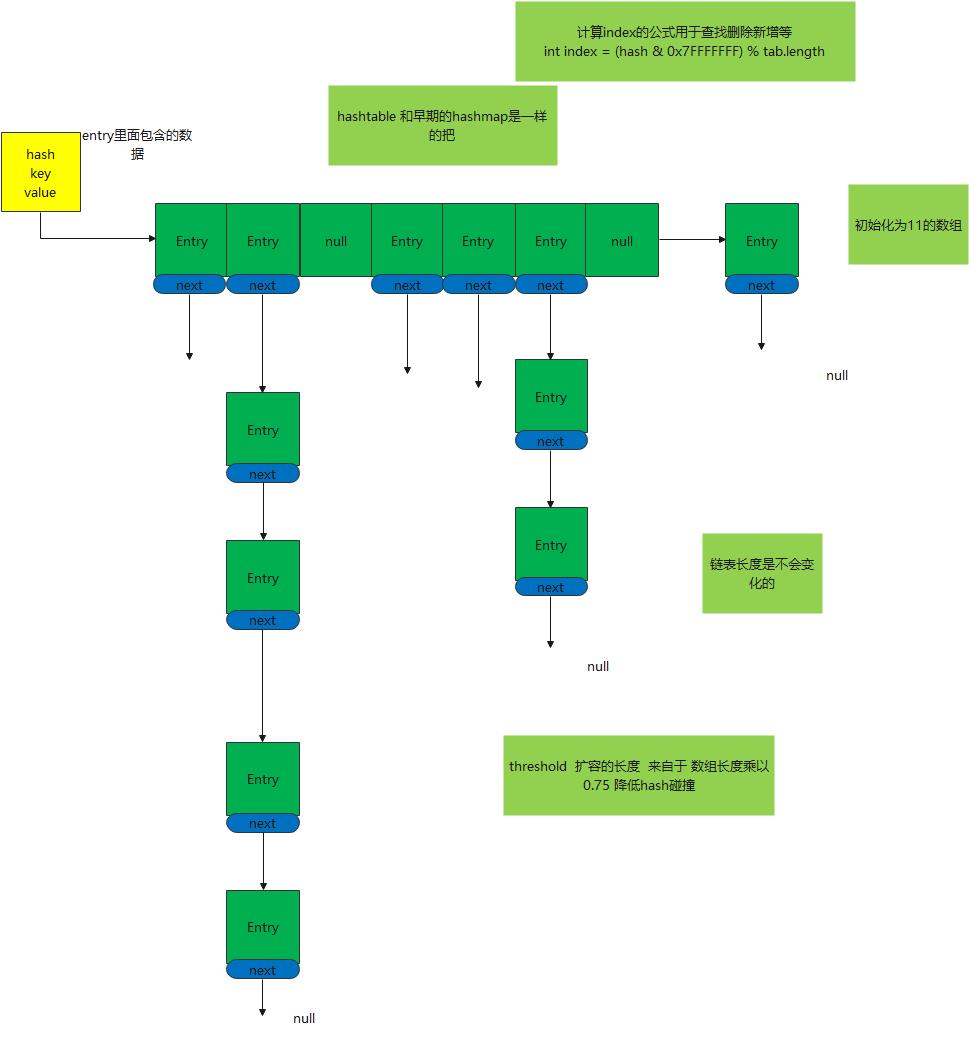
- HashTable类中,保存实际数据的,是Entry对象
- 初始化11的链表数组
- 解决hash碰撞采用链表的方式解决
- 整个hashtable的方法采用synchronized 关键字用来保证数据安全
接下来通过源码分析整个hashtable
全篇注释解析
/**
*这个类实现了一个哈希表,它将键映射到值。任何非空对象可以用作键或值<p>要成功地从哈希表中存储和检索对象用作键的对象必须实现<code>hashCode</code>
*方法和<code>等于<code>方法<p><code>Hashtable的实例有两个参数影响其性能:<i>初始容量</i>和<i>负载系数</i>。这个
*<i>capacity</i>是哈希表中的<i>桶数,以及<i>初始容量</i>只是哈希表运行时的容量已创建。请注意,哈希表是<i>打开的</i>:在“哈希”的情况下“碰撞”,单个bucket存储多个条目,必须对其进行搜索
*按顺序。<i>加载因子</i>是散列的完整程度的度量允许在表的容量自动增加之前获取它。初始容量和负载系数参数只是提示实施。具体的细节是什么时候,是否调用的方法依赖于实现。<p>通常,默认负载系数(.75)提供了一个很好的折衷方案
*时间和空间成本。较高的值会减少空间开销,但增加查找条目的时间成本(这反映在<tt>哈希表操作,包括<tt>get</tt>和<tt>put</tt>)。<p>初始容量控制浪费的空间和
*需要<code>重新刷新</code>操作,这非常耗时。如果初始容量大于最大条目数<tt>哈希表</tt>将包含除以其负载因子的值。然而,初始容量设置过高会浪费空间。<p>
*如果要在<code>哈希表</code>中生成多个条目,创建一个足够大的容量可能会允许比让它执行更有效地插入条目根据需要自动重新灰化以增大桌子<p>
*本例创建了一个数字哈希表。它使用数字作为键:
* <pre> {@code
* Hashtable<String, Integer> numbers
* = new Hashtable<String, Integer>();
* numbers.put("one", 1);
* numbers.put("two", 2);
* numbers.put("three", 3);}</pre>
*
* <p>To retrieve a number, use the following code:
* <pre> {@code
* Integer n = numbers.get("two");
* if (n != null) {
* System.out.println("two = " + n);
* }}</pre>
*
*<p>集合的<tt>迭代器<tt>方法返回的迭代器所有此类的“集合视图方法”返回的<em>快速失败</em>:如果哈希表在结构上随时被修改在迭代器创建之后,除了通过迭代器自己的
*方法,迭代器将抛出一个{@linkConcurrentModificationException}。因此,面对
*修改后,迭代器会快速而干净地失败,而不是冒着在未来不确定的时间里任意的、不确定的行为。哈希表的键和元素方法返回的枚举是
*<em>不</em>快速故障。<p>请注意,不能保证迭代器的快速失败行为
*一般说来,不可能在未来作出任何硬性保证存在未同步的并发修改。失败快速迭代器尽最大努力抛出ConcurrentModificationException。因此,编写依赖于此的程序是错误的
*其正确性例外:<i>迭代器的快速失败行为应仅用于检测错误。</i>
*<p>从Java2平台v1.2开始,这个类被改进为实现{@linkmap}接口,使其成为
*<a href=“{@docRoot}/./technotes/guides/collections/index.html”>
*Java集合框架</a>。与新系列不同实现时,{@code Hashtable}是同步的。如果不需要线程安全的实现,建议使用
*{@link HashMap}代替了{@code Hashtable}。如果线程安全需要高度并行的实现,然后建议使用{@link java.util.concurrent.ConcurrentHashMap}代替
*{@code Hashtable}。
* @author Arthur van Hoff
* @author Josh Bloch
* @author Neal Gafter
* @see Object#equals(java.lang.Object)
* @see Object#hashCode()
* @see Hashtable#rehash()
* @see Collection
* @see Map
* @see HashMap
* @see TreeMap
* @since JDK1.0
*/注释的主要意思有一下几点
- 这个类实现了一个hash表,任何非空对象可以用作键或值
- Hashtable的实例有两个参数影响其性能 ,初始容量 和负载因素
- 为降低hash碰撞,则默认负载系数(.75)
- 初始容量设置过高会浪费空间
- 迭代器所有此类的“集合视图方法”返回的<em>快速失败</em>
- 如果线程安全需要高度并行的实现,然后建议使用{@link java.util.concurrent.ConcurrentHashMap}代替
重要相对于hashmap优化程度还是差很多,毕竟看起来都不优化它了。
成员属性
/**
* hash table的数据
*/
private transient Entry<?,?>[] table;
/**
* 哈希表中的条目总数。
*/
private transient int count;
/**
* 当表的大小超过此阈值时,将重新刷新该表(这个 此字段的值为(int)(容量*负载系数)
*
* @serial
*/
private int threshold;
private float loadFactor;
private transient int modCount = 0;整个成员属性分析
- 包括hash table的主要存储数据的结构 entry<?,?> 散列表 链表数组
- 条目总数,count 从这个字段的定义感觉就和其他集合的数据结构不一样,都是以size命名了,这个集合的命名方式还是count
- 我们的扩容阈值默认负载系数(0.75)提供了良好的性能时间和空间成本之间的权衡。 这也是为什么设置这个为0.75的原因
- 也包括所有的集合都共有的参数,记录操作的modcount ,在遍历集合时,然后直接调用remove等方法,快速失败,抛出异常
构造函数
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}整个构造函数,主要初始化 负载因子,及初始化阈值和初始化个空数组
- 与其他集合对比构造函数的差别,很多比较新的集合都会考虑不在构造时创建数组,因为会占用很大的内存,例如arraylist , 当然 vector arraydeque priorityque 这些还是保持着在 构造函数中创建数组
- 其次对于默认容量设置,保持着和vector 大多数集合一样 在10 和11容量中考虑了11,不会像 之后 道格利优化过的代码那样 ,都会考虑2的幂次方,更好的分布数据
- 在计算扩容阈值时,在这里主要用initialCapacity * loadFactor 来计算
核心put方法
public synchronized V put(K key, V value) {
// 确保该值不为null
if (value == null) {
throw new NullPointerException();
}
// 确保该键不在哈希表中。
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// 如果超过阈值,则重新刷新表
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}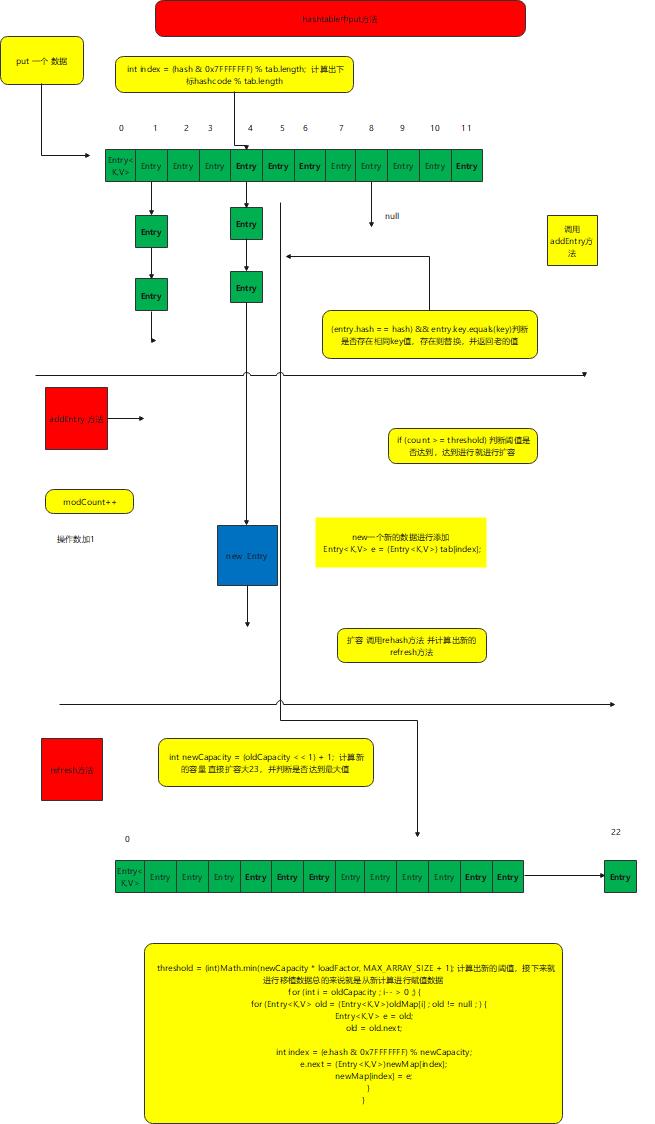
从上面的图进行分析出整个put的流程
- 判断值是否为空,并且判断数据key值是否已经存在,存在则进行覆盖并返回原有值
- 添加数据 操作数加 1 如果达到阈值,则进行扩容 扩容为老容量 +1 ,并进行重新计算hash进行赋值
- 最后进行赋值
remove方法
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}整个remove方法涉及到的是链表的遍历并删除某个节点
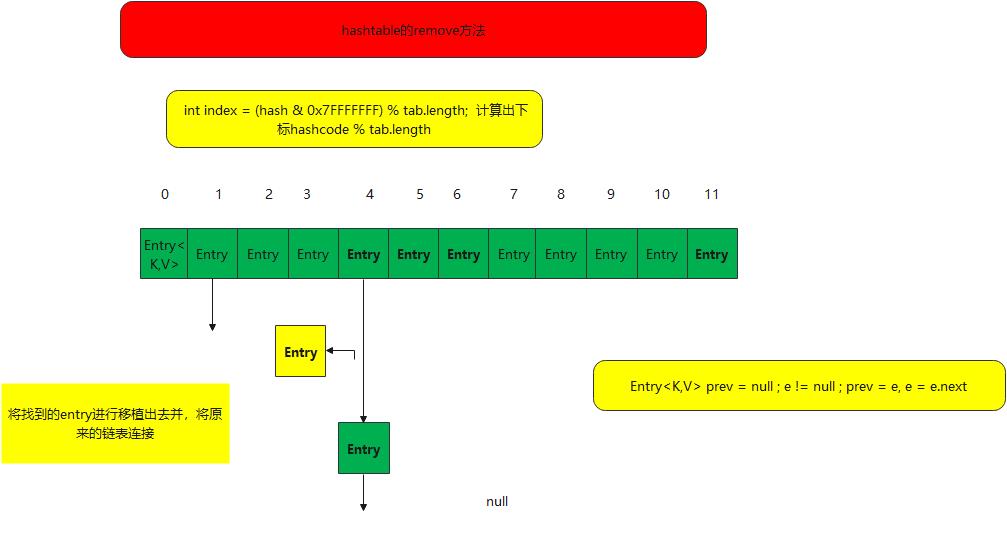
整个remove方法 先找下标节点进行遍历数据然后删除 这个和get操作等都比较简单,我就不继续研究其他方法了
总结
整个hashtable 实现了散列表,保证了多线程下数据安全,并且提供很多操作方法供我们使用,不允许添加null值,但对于高并发情况下,性能效果就比较差了,作者也建议我我们使用concurrenthashmap进行代替
以上是关于Java 集合深入理解 (十四) :Hashtable实现原理研究的主要内容,如果未能解决你的问题,请参考以下文章