Spark Streaming源码解读之No Receivers彻底思考
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming源码解读之No Receivers彻底思考相关的知识,希望对你有一定的参考价值。
本期内容 :
- Direct Acess
- Kafka
Spark Streaming接收数据现在支持的两种方式:
01、 Receiver的方式来接收数据,及输入数据的控制
02、 No Receiver的方式
以上两种方式中,No Receiver的方式更符合读取、操作数据的思路,Spark作为一个计算框架他的底层有数据来源,也就是直接操作数据来源中的数据,
如果操作数据来源的话肯定需要一个封装器,这个封装的类型一定是RDD的封装类型,Spark Streaming为了封装类型推出了自定义的RDD是KafkaRDD。
一、 No Receivers:
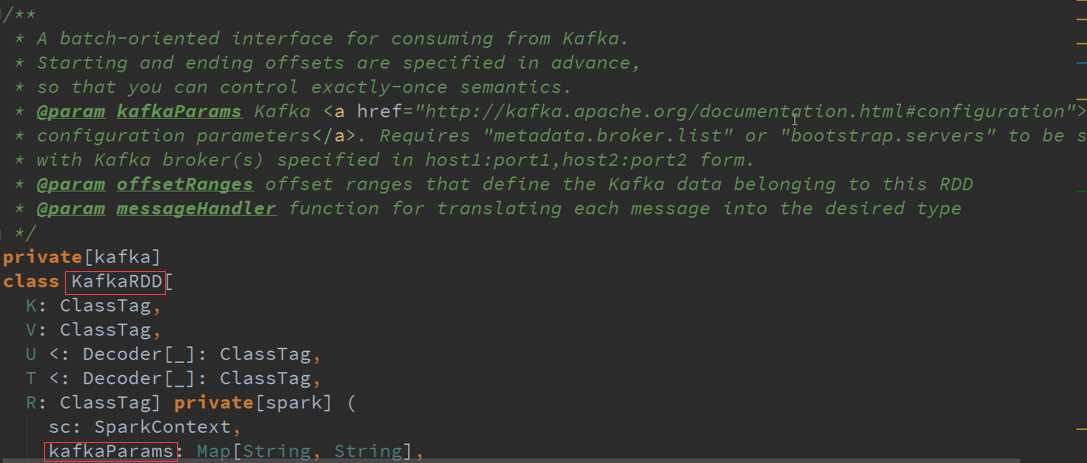
基于Spark Streaming的Bach-Oriented接口是在Kafka消费数据的一个实现,实现需要确定开始与结束的Offset(数据偏移量),Broker是Kafka中的概念,
也就是Spark Streaming直接去操作Kafka中的数据。
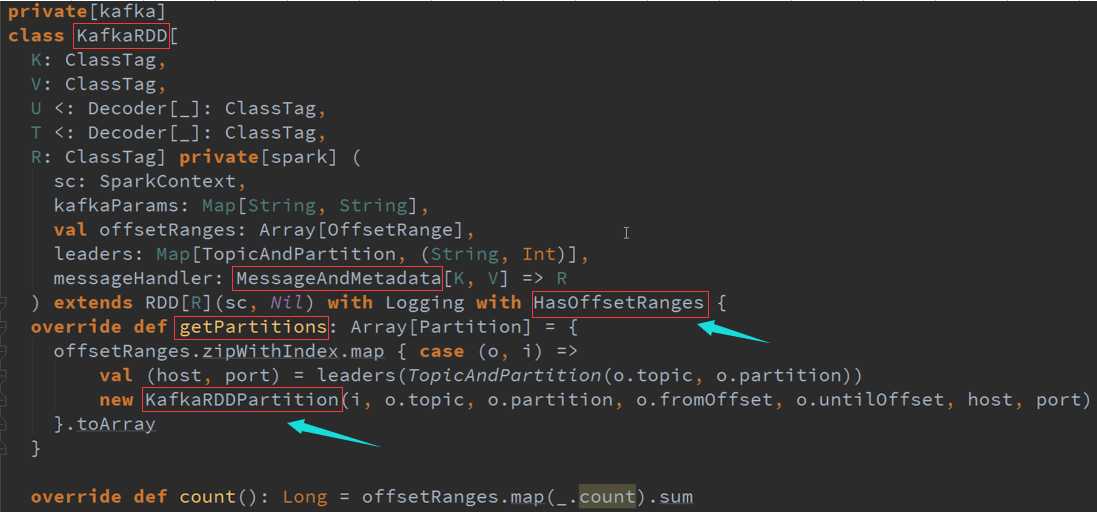
在ForEachRDD中可以获取OffsetRanges中产生所有分区的数据,即对源数据的控制。
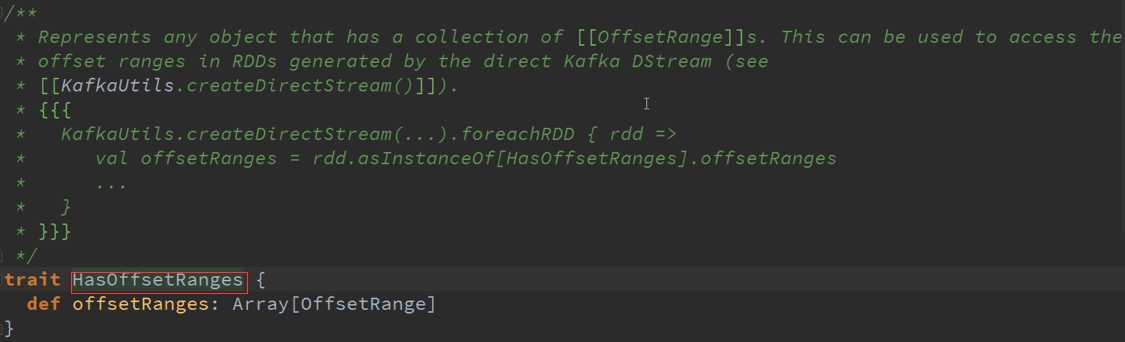
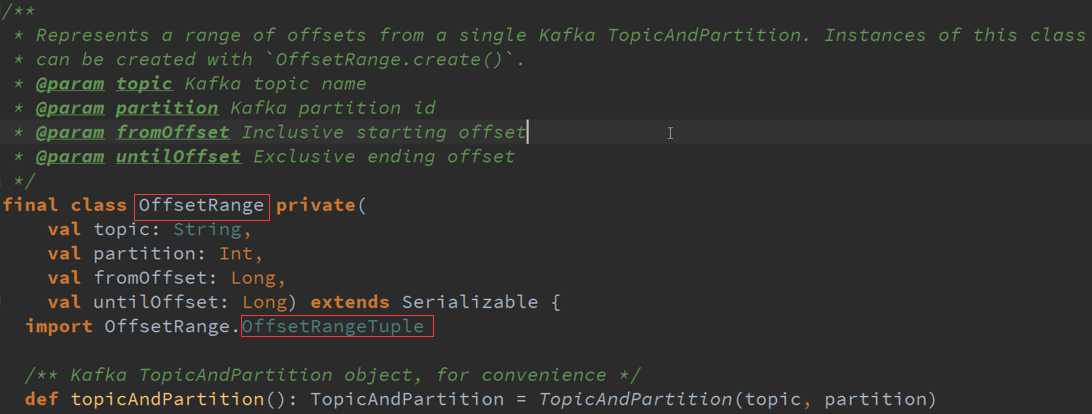
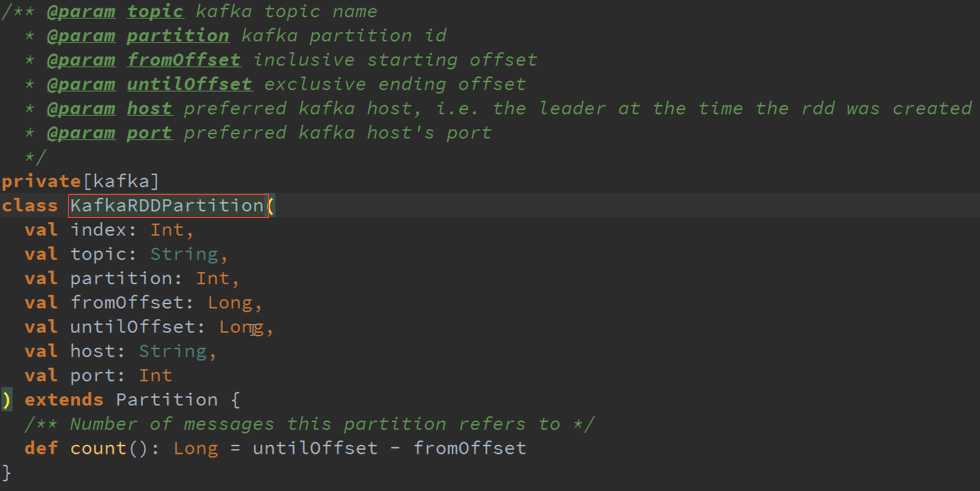
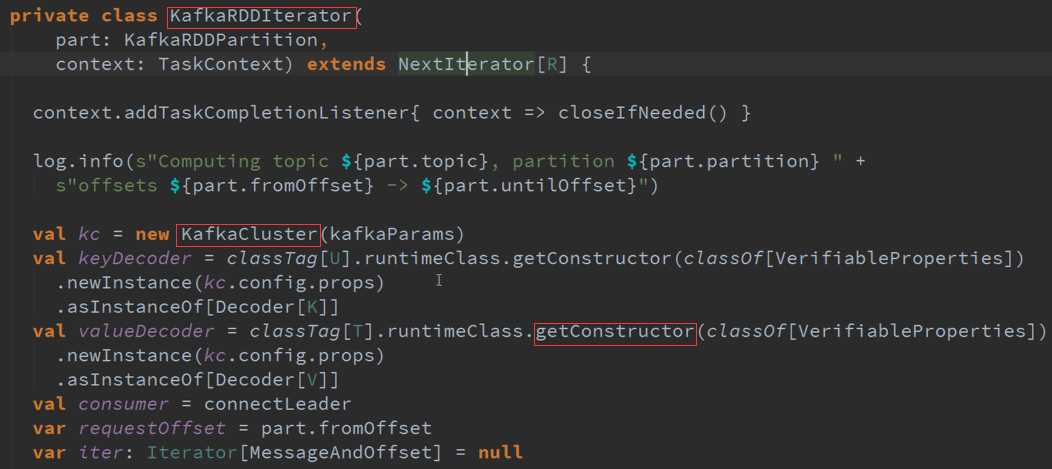
封装了一个与Kafka的交互而已。
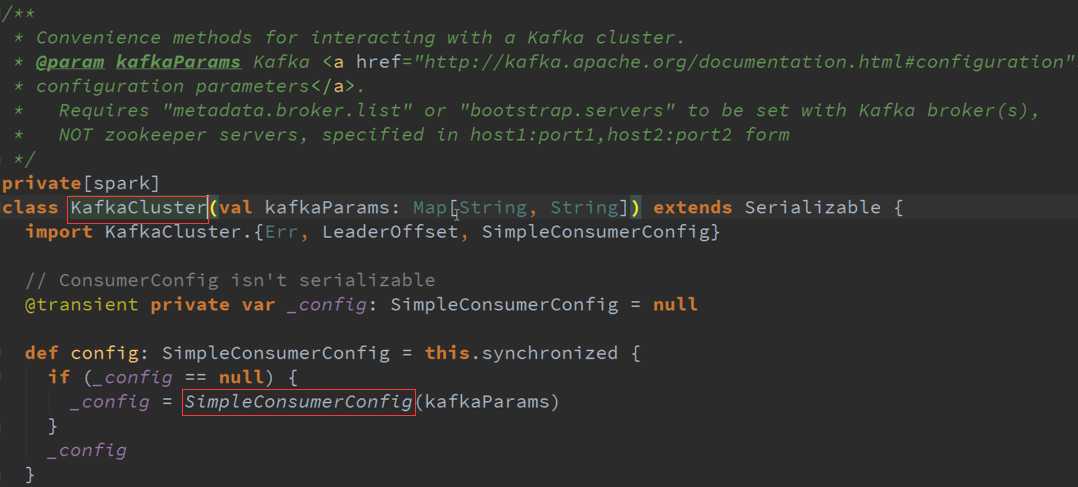
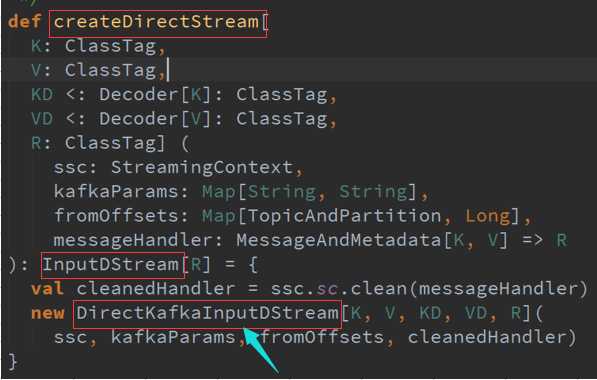
二、 DirectKafkaInPutDStreams :
在实际运行的时候会产生KafkaRDD ,不同的Topic对应不同生成的Partition ,RatePerPartition控制了每秒所能够消费数据的速度,交互接口是KafkaCluster
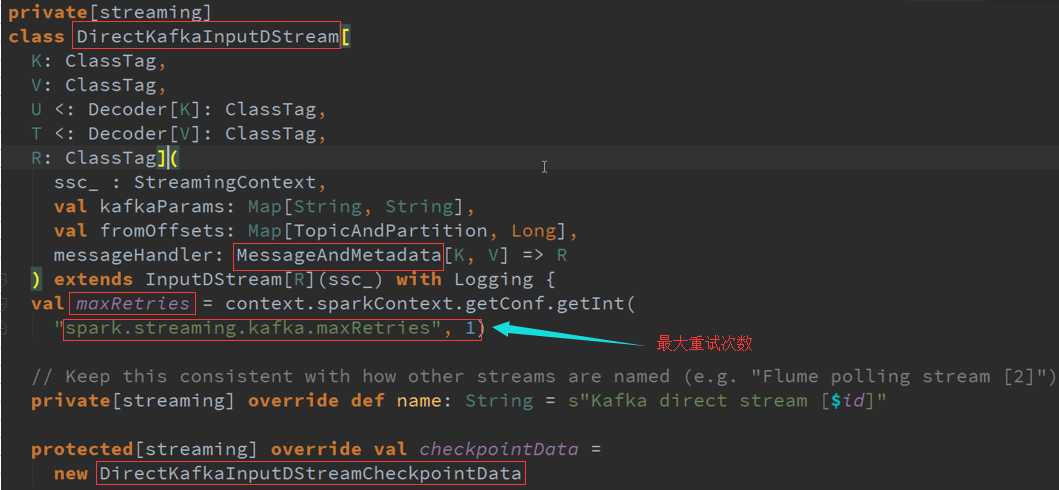
KafkaRDD本身包含很多Partition ,他有多少Partition就对应多少KafkaPartition
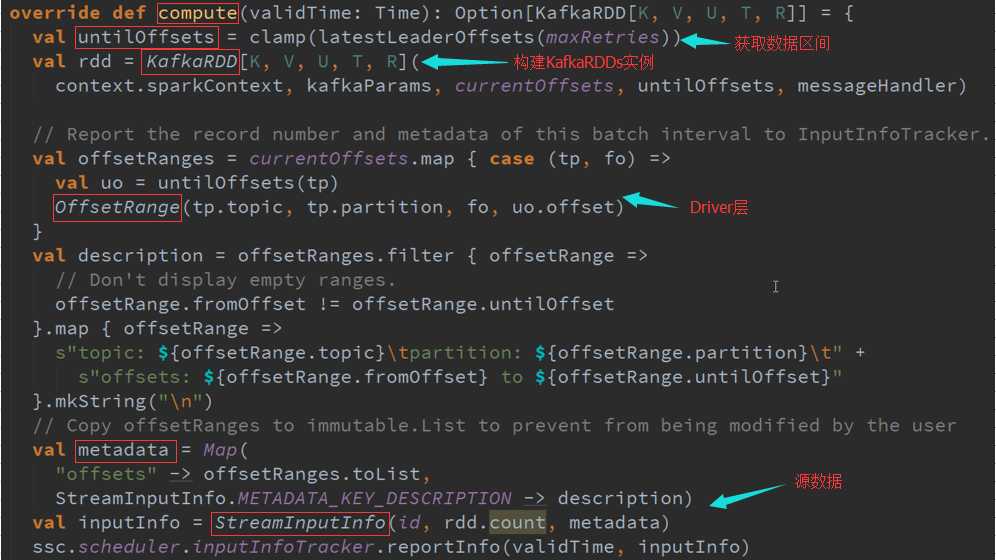
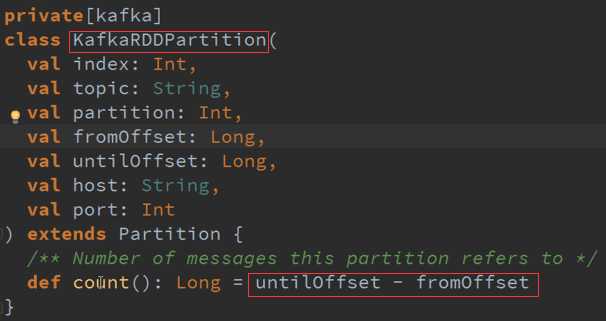
作为一个KafkaPartition 核心的方法就是消费多少数据,而且KafkaRDD的一个Partition只能属于一个Topic的,其实一般就是直接消费了一个Kafka的Topic
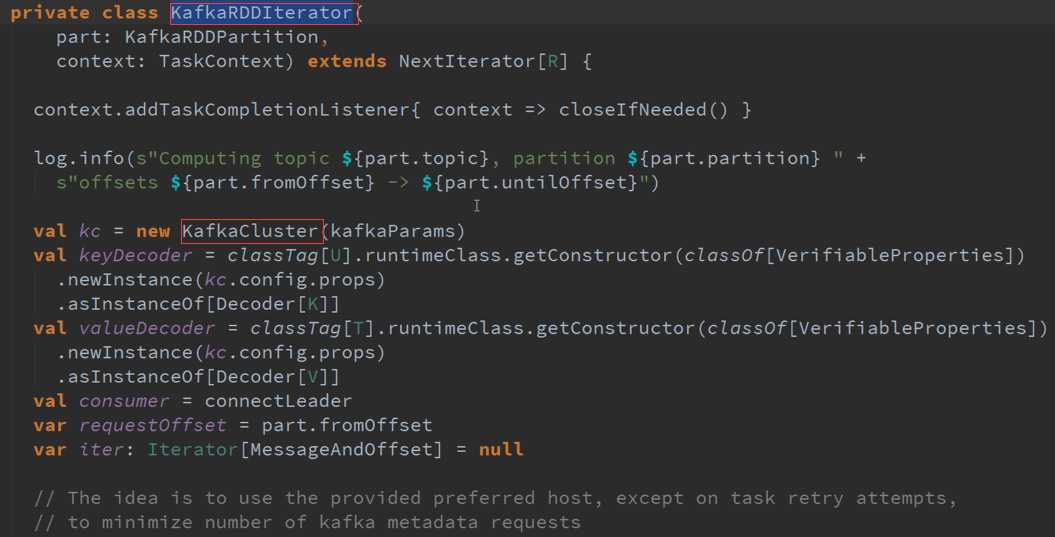
是从KafkaRDD的角度看,下一步就是读取数据。
直接抓Kafka数据的方式与Receiver的方式的实际价值 :
1、 Direct的方式读取数据,因为Direct是没有缓存的,也就是不存在内存溢出等问题,
2、 使用Receiver的方式去读取数据是存在缓存问题
2、 使用Direct的方式,KafkaRDD默认数据就是分布在多个Executor ,KafkaRDD默认就是分布式的
3、 使用Receiver的方式,默认情况下是和具体的Worker的Executor绑定了,Receiver方式是不方便做分布式,但是需要配置才可以做分布式的
4、如果是Direct方式是直接读取Kafka数据,Dream多少次都无所谓,如果Dream就不会再进行下一步的处理了
5、 使用Receiver方式,如果数据来不及处理,也就是数据操作Dream,如果操作多次Spark程序可能程序崩溃
备注:
-
- 资料来源于:王家林(Spark发行版本定制)
- 新浪微博:http://www.weibo.com/ilovepains
以上是关于Spark Streaming源码解读之No Receivers彻底思考的主要内容,如果未能解决你的问题,请参考以下文章
第15课:Spark Streaming源码解读之No Receivers彻底思考
Spark Streaming源码解读之No Receivers详解
Spark Streaming源码解读之No Receivers详解
(版本定制)第15课:Spark Streaming源码解读之No Receivers彻底思考