王道数据结构7(查找)
Posted 晨沉宸辰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了王道数据结构7(查找)相关的知识,希望对你有一定的参考价值。
查找
一、概念
- 查找 —— 在数据集合中寻找满⾜某种条件的数据元素的过程称为查找。
- 查找表(查找结构)—— ⽤于查找的数据集合称为查找表,它由同⼀类型的数据元素(或记录)组成。
- 关键字 —— 数据元素中唯⼀标识该元素的某个数据项的值,使⽤基于关键字的查找,查找结果应该是唯⼀的。
- 查找表操作:①查找符合条件的数据元素 (静态查找表) ②插⼊、删除某个数据元素(动态查找表)
- 评价一个查找表:① 查找⻓度——在查找运算中,需要对⽐关键字的次数称为查找⻓度 ② 平均查找⻓度(ASL, Average Search Length)—— 所有查找过程中进⾏关键字的⽐较次数的平均值
二、顺序查找
1. 基础表
- 顺序查找,⼜叫“线性查找”,通常⽤于线性表
- 代码
//查找表的数据结构——顺序表
typedef struct
ElemType *elem; //动态数组的基址
int TableLen; //表的长度
SSTable;
//顺序查找
//法一:找到数组长度末尾为止(从头到尾找,查找表第一个元素下标为0)
int Search_Seq(SSTable ST, ElemType key)
for(int i = 0; i < ST.TableLen && ST.elem[i] != key; i++)
//查找成功或者没找到时跳出循环
return (i==ST.TableLen? -1 : i);//查找成功时返回元素下标,没找到时返回-1
//法二:找到哨兵为止((从尾到头找查找表第一个元素下标为1,0存放哨兵)
int Search_Seq(SSTable ST, ElemType key)
ST.elem[0]=key; //在数组第一个(下标为0)位置放置哨兵
for(int i = ST.TableLen; ST.elem[i] != key; i--)
//查找成功(找到对应元素)或者没找到(找到哨兵)时跳出循环
return i; //查找成功时返回对应次序,没找到时返回0
- 第二种方法的优点:无需判断是否越界,效率提高,但是时间复杂度的级别没有得到提升。
- 查找效率: 时间复杂度: O(n)
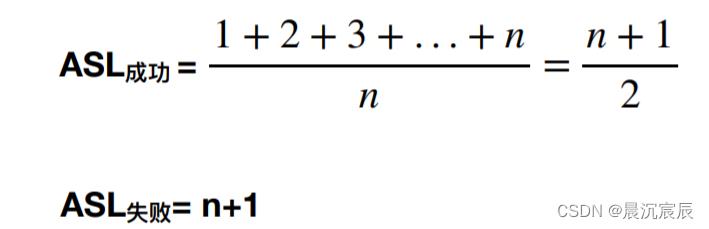
2. 顺序查找优化 — 有序表
- 若当前关键字大于(小于)目标关键字时,可以提前判断查找失败
- 优点:查找失败时ASL更少
- 查找失败情况有n+1种情况,

- 要绘制查找判定树

① ⼀个成功结点的查找⻓度 = ⾃身所在层数。
② ⼀个失败结点的查找⻓度 = 其⽗节点所在层数。
③ 默认情况下,各种失败情况或成功情况都等概率发⽣。
3. 顺序查找优化—被查概率不相等
- 可以让被查概率⼤的放在靠前位置,则查找成功的查找效率提升,但是查找失败的效率会变低,因此需要进行分情况选择。

三、折半查找
(1)算法思想
- 折半查找,⼜称“⼆分查找”,仅适⽤于有序的顺序表
- 使用两个指针low和high,初始化时,low指向0,high指向最后一个元素,查找期间:
① 如果查找元素k>a[(low+high)/2],则说明k属于中间区域即(low+high)/2+1~ high内的元素,并且将low指向(low+high)/2+1;
② 如果如果查找元素k<a[(low+high)/2],则说明k属于中间区域即low ~ (low+high)/2-1内的元素,并且将high指向(low+high)/2-1,重复上述比较,直到找到或者,low>high时则失败
(1)算法实现
- 设置:
① low:指向待查数组的最左侧(左闭,low指向的也有可能要查,故更新时low = mid+1)
② high:指向待查数组的最右侧(右闭,high指向的也有可能要查,故更新时high = mid -1)
③ mid:指向待查数组的中间,分为向下取整和向上取整则判断条件为:low <= high (low>high则查找失败了) - 代码:
//查找表的数据结构——顺序表
typedef struct
ElemType *elem; //动态数组的基址
int TableLen; //表的长度
SSTable;
//折半查找——增序序列(成功返回数组下标,失败返回-1)
int Binary_Search(SSTable L, ElemType key)
//准备指针(下标)
int low = 0;
int high = L.TableLen - 1;
int mid;
while(low<=high)
mid = (low + high)/2;
if(key == L.elem[mid])
return mid;
else if(key < L.elem[mid])
high = mid - 1;
else
low = mid + 1;
return -1;
- 折半查找又称为二分查找,仅适用于有序的顺序表,顺序表拥有随机访问的特性,链表没有,因此链表不可以实现折半查找。
- 查找效率:

ASL成功 = (11+22+34+44)/11 = 3
ASL失败 = (34+48)/12 = 11/3
(3)折半查找判定树的构造
- 利用规律:如果当前low和high之间有奇数个元素,则 mid 分隔后,左右两部分元素个数相等;如果当前low和high之间有奇数个元素,则 mid 分隔后,左右两部分元素个数相等【左子树比右边多一个,或者相同】
- 右子树节点数-左子树节点数=0/1.
- 折半查找判定树一定是一个平衡二叉树,折半查找的判定树中,只有最下面一层是不满的,因此元素为n的树高h=[log2(n+1)] [树高不包括失败结点那一层] [向上取整]。若加上失败结点h=[log2(n+1)] +1 。
- 又符合二叉排序树的定义,失败结点的个数为n+1个(等于成功结点的空链域的数量)。
(4)查找效率
- 查找成功/失败的ASL≤h
- 折半查找的时间复杂度=O(log2n),但是折半查找 [并不是] 一定比顺序查找快。
- (low+high)/2到底是向上取整,还是向下取整,都会影响绘制的判定树,需要注意,本篇是向下取整。
- 由查找判定树可知,树高(不包含失败结点)h = ⌈log2(n + 1)⌉向上取整,查找成功和查找失败的ASL ≤ h ,故折半查找的时间复杂度 = O(log2n)
四、分块查找
(1)算法分析
-
分块查找又称为索引顺序查找,又有动态结构,有适合于快速查找。
-
基本思想:将查找表分为若干个子块,块内的元素可以无序,但块之间是有序的,即第一个块中的最大关键字小于第二个块中的所有记录的关键字,第二个快中的最大关键字小于第三个快中的所有记录的关键字。在建立一个索引表,索引表中的每个元素含有各块的最大关键字和各块中的第一个元素的地址,索引表按关键字有序排列。也就是:块内无序,块间有序。
-
索引表中保存每个块的最大关键字和分块的存储区间。
-
过程:
①在索引表中确定待查记录所属的分块(可顺序、可折半)
②在块内顺序查找
例如:

① 使用指针p,现在索引表中使用顺序查找算法,聚焦到p为2,值为30
② 在2的块内进行顺序查找或者二分查找
③如果p在索引表中查找超出索引长度或者在块内查找,超出块内长度,则认为查找失败 -
代码:
//索引表——保存每个分块的最⼤关键字和分块的存储区间
typedef struct
ElemType maxValue;
int low, high;
Index;
//顺序表——存储实际元素
ElemType List[100];
- 注意:若索引表中不包含⽬标关键字,则折半查找索引表最终停在 low>high,要在low所指分块中查找
原因:最终找不到时high=low=mid:若key大于[mid]时,low后移一位,此时[low]>key;若key小于[mid]时,high前移一位,此时还是[low]>key————⽽分块存储的索引表中保存的是各个分块的最⼤关键字。 - (low超出索引表范围时—查找失败)
(2)查找效率分析ASL
-
使用顺序查找的方法


-
使用折半查找:
30 :4次,第一轮就发现在索引表中mid就是所需的30,则会进入30这个块查找三次,一共1+3=4次。
27:第一轮,会查找mid为三十不是27,且大于27,则会让high指向20,low仍然是10;第二轮会让mid指向10,27>10,则low指向mid+1,为20,high仍然是20;第三轮,20<27,则low指向30,high指向20,此时会进入30这个块,然后第一个发现27,查找成功,因此27一共查找了四次。
算出所有元素的次数,然后相乘概率1/n,然后相加,得到ASL。 -
以上都是查找成功的ASL,失败的ASL的复杂,则跳过。
(3)优化—有规律的分块
1.假设,⻓度为n的查找表被均匀地分为b块,每块s个元素,设索引查找和块内查找的平均查找⻓度分别为LI、LS,则分块查找的平均查找⻓度为ASL=LI + LS
(1)⽤顺序查找查索引表,

(2)使用折半查找索引表

(4)拓展
若查找表是动态查找表,插入新的元素会让表整体移动,会付出很大的代价,因此使用链式存储方式,增加元素在链表尾部加入新结点即可。
五、B+树
(我考的学校不考)
六、散列查找
(一)散列表的基本概念
- 散列表(Hash Table),又称为哈希表,是一种数据结构,特点是:数据元素的关键字与其存储地址直接相关。
- 散列函数:一个把查找表中的关键字映射成该关键字对应的地址的函数,记为Hash(key)=Addr(这里的地址可以是数组下标、索引或内存地址等)。
- 散列函数可能会把两个或两个以上的不同关键字映射到同一地址上,这种情况就称为冲突。这些发生碰撞的不同关键字称为同义词。
- 例如:
一堆元素,散列函数H(key)=key%13
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| 值 | 14/1 | 19 |
如表:19/13=6,存在6下标的位置,但是14和1形成了冲突
5. 用拉链法(又称为链接法、链地址法)处理冲突:把所有“同义词”存储在一个链表中。
6. 理想情况下,对散列表查找长度为0,时间复杂度为O(1),与表中的元素无关。
7. 例题:
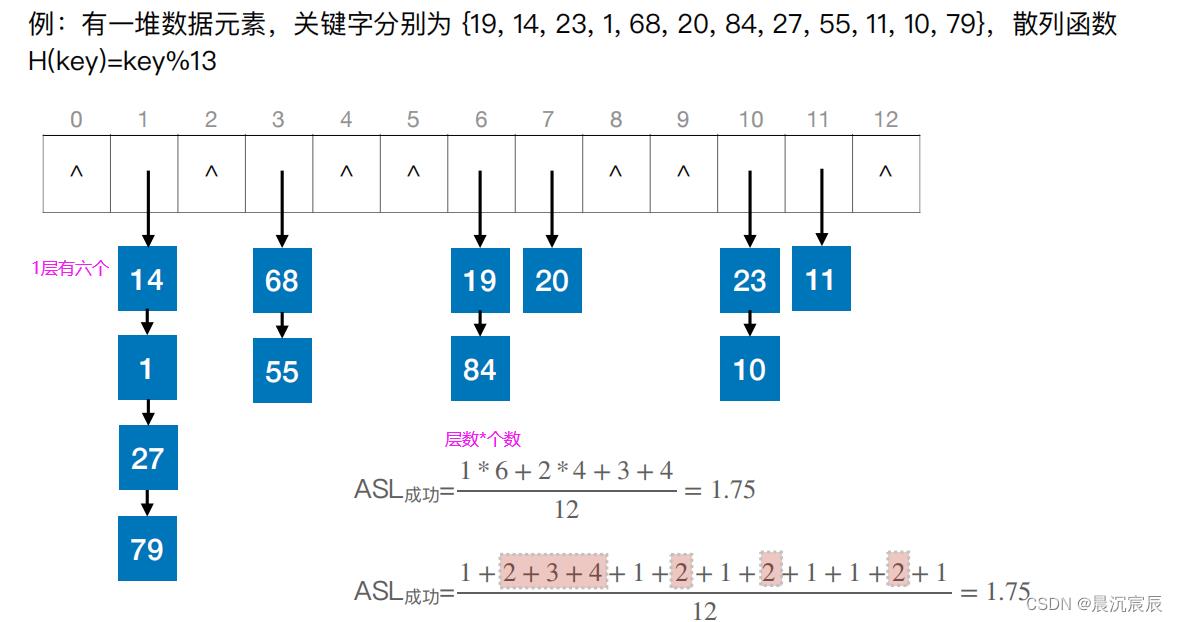

查找失败是:存储单元格,没有元素的查找记为0次,拥有单元格的元素记为元素个数次,相加,除以单元格总数。
① 装填因子:表中记录数/散列表的长度
② 装填因子越小,说明空缺越大,会影响效率。
上述的冲突过大,所以我们要重新设计平均查找长度去提高查找效率。
(二)散列函数的构造法
- 直接定址法
H(key)=key 或H(key)=a*key+b
适用于:数据分布均匀的情况 - 除留余数法
假设散列表长为m,取一个不大于m但最接近或等于m的质数p,利用公式:H(key)=key%p;选择地址p,可以让数据分布均匀,尽量没有空位置,则实现减少冲突。 - 数字分析法
选择数码分布较为均匀的若干位,作为散列地址。 - 平均取中法、
去关键字的平方值的中间几位作为散列地址。这种方法得到的散列地址与关键字的每位都有关系,因此散列地址分布比较均匀。
散列查找实质“用空间换时间”
(三)处理冲突方法
(1)拉链法
(2)开放定址法
- 所谓开放定址法,就是指可存放新表项的空闲地址既向它的同义词表项开放,又向它的非同义词表项开放,其数学递推公式为:
Hi=(H(key)+di)%m
m表示散列表表长,di表示增量序列,i表示第i次发生冲突。 - di增量序列的设定方法:① 线性探测法 ② 平方探测法 ③ 伪随机序列法
1. 线性探测法
di=0,1,2,3,4…m-1,即发生冲突时,每次往后探测相邻的下一个单元是否为空。
(1)填入表格
例: 数组:19,14,23,1,68,20,84,27,55,11,10,79,散列函数H(key)=key%13。
①
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 值 | 14 | 19 | 23 | |||||||||||||
| ② |
1 H(1)=(1)%13=1,与14 冲突,则进行di=1,使用递推公式:H(1)=(1+1)%16=2,则存入2中
后续H(68)=(68)%13=3 H(20)=(20)%13=7
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 值 | 14 | 1 | 68 | 19 | 20 | 23 |
③
84 H(84)=(84)%13=6 与19发生冲突,则使用递推公式H(84)=(6+0)%16=6,还冲突,di=1 H(84)=(6+1)%16=7,还冲突,di=2,H(84)=(7+2)%16=8 。则存入8位置
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 值 | 14 | 1 | 68 | 19 | 20 | 84 | 23 |
④ 最终结果
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 值 | 14 | 1 | 68 | 27 | 55 | 19 | 20 | 84 | 79 | 23 | 11 | 10 | 25 |
发现使用散列函数的位置为0~12,加入递推公式以后,会出现0 ~15的位置
(2)算法查找
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 值 | 14 | 1 | 68 | 27 | 55 | 19 | 20 | 84 | 79 | 23 | 11 | 10 | 25 |
查找27
① H(27)=(27)%13=1,b[1]=14!=27
② 往后移动探测后面位置,2,3,4,得到27,查找长度为4
规律:
① 既可以与同义词(14)查找对比,又可以和非同义词(84)进行对比。
② 找不到元素时,需要将空位置看成一个非合法数据,也算一次查找次数。
③ 因为查找是找到第一个空位置,则算查找失败就不会查找后序,因此越早遇到空位置,查找效率越早得到提升。
(3)删除操作
注意:不可以简单的将被删节点的位置设为空,否则会截断它之后填入散列表的同义词结点的查找路径,可以做一个删除标记,进行逻辑删除。
(4)缺点:
如果删除的结点过多,会造成大量空间的浪费,并且在查找时,还是需要对比那些删除标记的地址,算作一次查找次数。
(5)查找效率分析(ASL)


问:为什么失败这么高?
答:线性探测法很容易造成同义词、⾮同义词的“聚集(堆积)”现象,严重影响查找效率,产⽣原因——冲突后再探测⼀定是放在某个连续的位置
2. 平方探测法
散列表长度必须是一个可以表示成4k+3的素数,才可以检测到所有位置,此方法可以避免堆积问题,但是不能探测到所有的单元,至少能探测到一半单元。
(1)实现方法:di=0,1,-1,2^ 2,-2 ^ 2,3 ^ 2,-3^2……k ^2,-k ^2.
比如 6 19 32 45 58 71在散列函数H(key)=key%13,的条件下,都与6发生冲突,表长为27
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 值 | 58 | 32 | 6 | 19 | 45 | 71 |
① 存入19 使用递推公式:h1=(6+1)%27=7,存入7位置
② 存入32,先于6发生冲突,h1=(6+1)%27=7,与19发生冲突,h2=(7+(-1))%27=5,存入5位置
③ 存入 45,探测6、7、5都冲突,则h3=(5+2^2)%27=10,不冲突,存入10位置
④ 最终结果如上述
(2)查找过程:上述一样的过程
3. 伪随机序列法
di是一个伪随机序列,指定的一个数据,比如di=0,5,24,11
例如数据为6,19,32,45,在19与6冲突以后,则往右寻找5个得到自己的位置11
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 值 | 32 | 6 | 19 | 45 |
(3)再散列法
再散列法(再哈希法):除了原始的散列函数 H(key) 之外,多准备⼏个散列函数,当散列函数冲突时,⽤下⼀个散列函数计算⼀个新地址,直到不冲突。
(四)拉链法的优化

以上是关于王道数据结构7(查找)的主要内容,如果未能解决你的问题,请参考以下文章