Spark 安装
Posted moonlight-lin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 安装相关的知识,希望对你有一定的参考价值。
架构
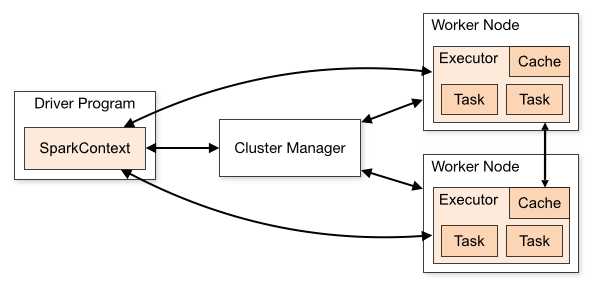
- Driver Program:每个 Spark 应用的主程序
- Spark Context:在 Driver 里面构建,用于协调、调度在各个节点运行的进程
- Cluster Manager:管理节点,分配资源(可以是 Spark standalone、Mesos、Yarn、K8S)
- Worker Node:可以运行计算任务的节点(Driver 也是跑在 Worker 上)
- Executor:用于运行计算任务的进程,Worker Node 可以有多个 Executor,每个 Executor 可以有多个用于计算的 Task 线程,每个 Spark 应用都有一个或多个分布在各个节点的、只属于自己的 Executor
Client 提交 Spark 应用后,会在 Client 所在节点或由 Manager 选择的节点(取决于提交的方式)启动 Driver,在 Driver 需要构建 SparkContext,通过 SparkContext 构建要执行的任务,然后 SparkContext 会向 Manager 申请资源(Executor 个数、内存等),由 Manager 在各个 Worker Node 分配启动 Executor,然后 SparkContext 会计算如何调度任务,并将程序传给 Executor,并调度 Executor 执行
部署模式
Spark 现在支持几种部署模式
- Standalone:启动 Spark 自己的 Manager 和 Worker,不依赖于其他集群管理程序
- Mesos:基于 Mesos 集群
- Yarn:基于 Yarn 集群,直接使用 Yarn 的 ResourceManager 和 NodeManager 作为自己的 Manager 和 Worker
- Kubernetes:基于 Kubernetes 部署容器化应用
这里只介绍 Spark on Yarn 模式
要求
Hadoop/Yarn 集群已经安装好
下载
https://archive.apache.org/dist/spark/spark-2.2.0/
选择 spark-2.2.0-bin-without-hadoop.tgz
安装
> sudo tar -zxf spark-2.2.0-bin-without-hadoop.tgz -C /usr/local/
> cd /usr/local
> sudo mv ./spark-2.2.0-bin-without-hadoop/ ./spark
> sudo chown -R hadoop:hadoop ./spark
> vi ~/.bashrc ## 添加 PATH=$PATH:/usr/local/spark/bin:/usr/local/spark/sbin
> source ~/.bashrc
Spark 自带 Scala,所以不需要再额外安装
配置
cd /usr/local/spark
sudo cp ./conf/spark-env.sh.template ./conf/spark-env.sh
sudo vi ./conf/spark-env.sh
# 添加下面内容
# export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
# export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop/
有了上面的配置,Spark 就可以读取 Hadoop 的信息
在所有节点上安装配置 Spark
使用
配置完成后就可以直接使用,不需要像 Hadoop 运行启动命令
pyspark --version
run-example SparkPi
spark-shell ## scala
pyspark ## python
spark-shell 和 pyspark 都是交互界面,其中 spark-shell 用 scala 语言,pyspark 用 python 语言
例子
pyspark
>>> from pyspark.sql import SQLContext
>>> sqlc = SQLContext(sc)
>>> columnName = ["name", "type", "value"]
>>> values = [["n1",1,123],["n2",2,456]]
>>> df = sqlc.createDataFrame(values, columnName)
>>> df.write.parquet("/user/hadoop/test.parquet", mode="overwrite")
>>> sqlc.read.parquet("/user/hadoop/test.parquet").show()
+----+----+-----+
|name|type|value|
+----+----+-----+
| n1| 1| 123|
| n2| 2| 456|
+----+----+-----+
spark-submit
# spark_test.py
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext(appName="Spark_Test")
sqlc = SQLContext(sc)
columnName = ["name", "type", "value"]
values = [["n1",1,123],["n2",2,456]]
df = sqlc.createDataFrame(values, columnName)
df.write.parquet("/user/hadoop/test.parquet", mode="overwrite")
sqlc.read.parquet("/user/hadoop/test.parquet").show()
spark-submit --master local ./spark_test.py
spark-submit --master yarn ./spark_test.py
local 模式不会提交到 Yarn 而是在本地运行
yarn 模式会把程序提交到 Yarn,在 Yarn 的 UI 或 yarn application -list 可以查看程序
Spark 2.0 开始建议用 SparkSession 做入口,SparkSession 封装了 SparkContext 和 SQLContext
# spark_test.py
from pyspark.sql import SparkSession
spark = SparkSession .builder .appName("Python Spark SQL basic example") #.config("spark.some.config.option", "some-value") .getOrCreate()
sc = spark.sparkContext
rdd_1 = sc.parallelize([0, 2, 3, [6, 8], "Test"])
rdd_2 = rdd_1.map(lambda x : x*2)
print rdd_2.collect()
df = spark.read.load("/user/hadoop/test.parquet")
df.createOrReplaceTempView("test")
sqlDF = spark.sql("SELECT * FROM test")
sqlDF.show()
spark-submit 的参数
--master local ## 单机模式,使用 1 个 worker 线程
--master local[K] ## 单机模式,使用 K 个 worker 线程
--master yarn ## 集群模式(基于 yarn)
--master yarn --deploy-mode client ## driver 跑在本机,默认 client
--master yarn --deploy-mode cluster ## driver 跑在集群的任意节点,注意 log 不一定存在本机
--master yarn-client ## 等同于 --master yarn --deploy-mode client
--master yarn-cluster ## 等同于 --master yarn --deploy-mode cluster
--jars JARS ## Comma-separated list of local jars to include on driver/executor classpaths.
--py-files PY_FILES ## Comma-separated list of .zip, .egg, or .py files to place
## on the PYTHONPATH for Python apps.
--files FILES ## 逗号分隔的文件列表,会放到每个 executor 的工作目录
## Spark 使用下面几种 URI 来处理文件的传播:
## file://,由 driver 的 HTTP server 提供文件服务,executor 从 driver 上拉回文件
## hdfs:, http:, https:, ftp:, executor 直接从 URL 拉回文件
## local:, executor 本地本身存在的文件,不需要拉回
## --files 是放到 local:
--driver-cores NUM ## Number of cores used by the driver, only in cluster mode (Default: 1)
--driver-memory MEM ## Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options ## Extra Java options to pass to the driver.
--driver-library-path ## Extra library path entries to pass to the driver.
--driver-class-path ## Extra class path entries to pass to the driver.
## Note:jars added with --jars are automatically included in the classpath.
## 所以 --jars 有的就不用写到 --dirver-class-path 了
--executor-memory MEM ## Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--executor-cores NUM ## Number of cores per executor.
## (Default: 1 in YARN, or all available cores on the worker in standalone)
--num-executors NUM ## Number of executors to launch, only in YARN mode (Default: 2)
--queue QUEUE_NAME ## The YARN queue to submit to (Default: "default").
--conf PROP=VALUE ## Arbitrary Spark configuration property.
--properties-file FILE ## Path to a file from which to load extra properties.
## If not specified, this will look for conf/spark-defaults.conf
--class CLASS_NAME ## Your application‘s main class (for Java / Scala apps)
只用过基于 Yarn 的,不清楚其他模式是否有所不同
RDD、DataFrame、DataSet
RDD(Resilient Distributed Dataset,弹性分布式数据集)
- Spark 的基本数据集
- 存储的是非结构化数据,即每个元素的数据类型、结构都可以不一样
- 可以通过函数式编程自定义对数据的处理计算
DataFrame
- 结构化数据,带有 schema,有字段名,同一字段的数据类型一致,像行列式关系表一样
- 基于结构化数据,支持很多数据源(postgres、hbase、json、csv 等等),提供了更多数据处理的 API
- 可以通过 Spark SQL 处理数据
- 不能直接通过函数式编程自定义处理数据,除非先转换成 RDD
- 有针对性的优化,包括序列化的优化,数据存储的优化(减少 GC),任务执行的优化
- 在 Spark 2.0 开始,DataFrame 是 DataSet 的一个特例
- Python、R 没有 DataSet,因为没有强类型
DataSet
- 和 DataFrame 类似
- 强类型,编译时即可发现错误(Python、R 不支持 DataSet)
- 可自定义对象(即每行数据由自定义的类表示)
- Tungsten 引擎对序列化、编解码、内存管理、缓存命中率、CPU 使用的优化
- 任务执行的优化
- DataFrame 和 DataSet 最终都通过构建 RDD DAG 运行
- 官方建议用 DataSet
Spark 1.6 和 Spark 2 的区别
Spark 2 大体上是兼容 Spark 1.6 的,主要的改变有
Programming APIs
- 统一了 DataFrame 和 Dataset(限 Scala 和 Java),DataFrame 是 DataSet 的特例
type DataFrame = Dataset[Row] - 引入了新的类 SparkSession,替代 SparkContext、SQLContext、HiveContext,旧的类还可以用,实际上 SparkSession 也是用的这些类,相当于封装了一个统一入口类
- 更简单高效的 accumulator API
- A new, improved Aggregator API for typed aggregation in Datasets
SQL
- 原生 SQL parser 支持 ANSI-SQL 和 Hive QL,支持 SQL2003 标准
- 原生 DDL 命令的实现
- 支持子查询
- view 规范化
New Features
- 原生支持 CSV 数据源
- Off-heap memory management(堆外内存管理)for both caching and runtime execution
- Hive style bucketing support
- Approximate summary statistics using sketches, including approximate quantile, Bloom filter, and count-min sketch
Performance and Runtime
- Substantial (2 - 10X) performance speedups for common operators in SQL and DataFrames via a new technique called whole stage code generation.
- Improved Parquet scan throughput through vectorization
- Improved ORC performance
- Many improvements in the Catalyst query optimizer for common workloads
- Improved window function performance via native implementations for all window functions
- Automatic file coalescing for native data sources
MLlib New features
- The DataFrame-based API is now the primary API. The RDD-based API is entering maintenance mode
- ML persistence: The DataFrames-based API provides near-complete support for saving and loading ML models and Pipelines in Scala, Java, Python, and R
- Python: PySpark now offers many more MLlib algorithms, including LDA, Gaussian Mixture Model, Generalized Linear Regression, and more.
- Algorithms added to DataFrames-based API: Bisecting K-Means clustering, Gaussian Mixture Model, MaxAbsScaler feature transformer.
Streaming
- 引入了 Structured Streaming,基于 Spark SQL,使得用户可以使用 DataFrame/DataSet 的 API 处理流数据,也可以使用 SQL 处理流数据,就像处理批数据一样,支持 event-time windows、stream-to-batch joins、fault-tolerant、end-to-end exactly-once
- DStream 支持 Kafka 0.10
以上是关于Spark 安装的主要内容,如果未能解决你的问题,请参考以下文章
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)(代码片段