微服务海量日志监控平台
Posted dengbangpang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务海量日志监控平台相关的知识,希望对你有一定的参考价值。
前面几章蜻蜓点水的介绍了elasticsearch、apm相关的内容。本片主要介绍怎么使用ELK Stack帮助我们打造一个支撑起日产TB级的日志监控系统
背景
在企业级的微服务环境中,跑着成百上千个服务都算是比较小的规模了。在生产环境上,日志扮演着很重要的角色,排查异常需要日志,性能优化需要日志,业务排查需要业务等等。然而在生产上跑着成百上千个服务,每个服务都只会简单的本地化存储,当需要日志协助排查问题时,很难找到日志所在的节点。也很难挖掘业务日志的数据价值。那么将日志统一输出到一个地方集中管理,然后将日志处理化,把结果输出成运维、研发可用的数据是解决日志管理、协助运维的可行方案,也是企业迫切解决日志的需求。
我们的解决方案
通过上面的需求我们推出了日志监控系统。

- 日志统一收集、过滤清洗。
- 生成可视化界面、监控,告警,日志搜索。
功能流程概览

- 在每个服务节点上埋点,实时采集相关日志。
- 统一日志收集服务、过滤、清洗日志后生成可视化界面、告警功能。
我们的架构

- 日志文件采集端我们使用filebeat,运维通过我们的后台管理界面化配置,每个机器对应一个filebeat,每个filebeat日志对应的topic可以是一对一、多对一,根据日常的日志量配置不同的策略。除了采集业务服务日志外,我们还收集了mysql的慢查询日志和错误日志,还有别的第三方服务日志,如:nginx等。最后结合我们的自动化发布平台,自动发布并启动每一个filebeat进程。
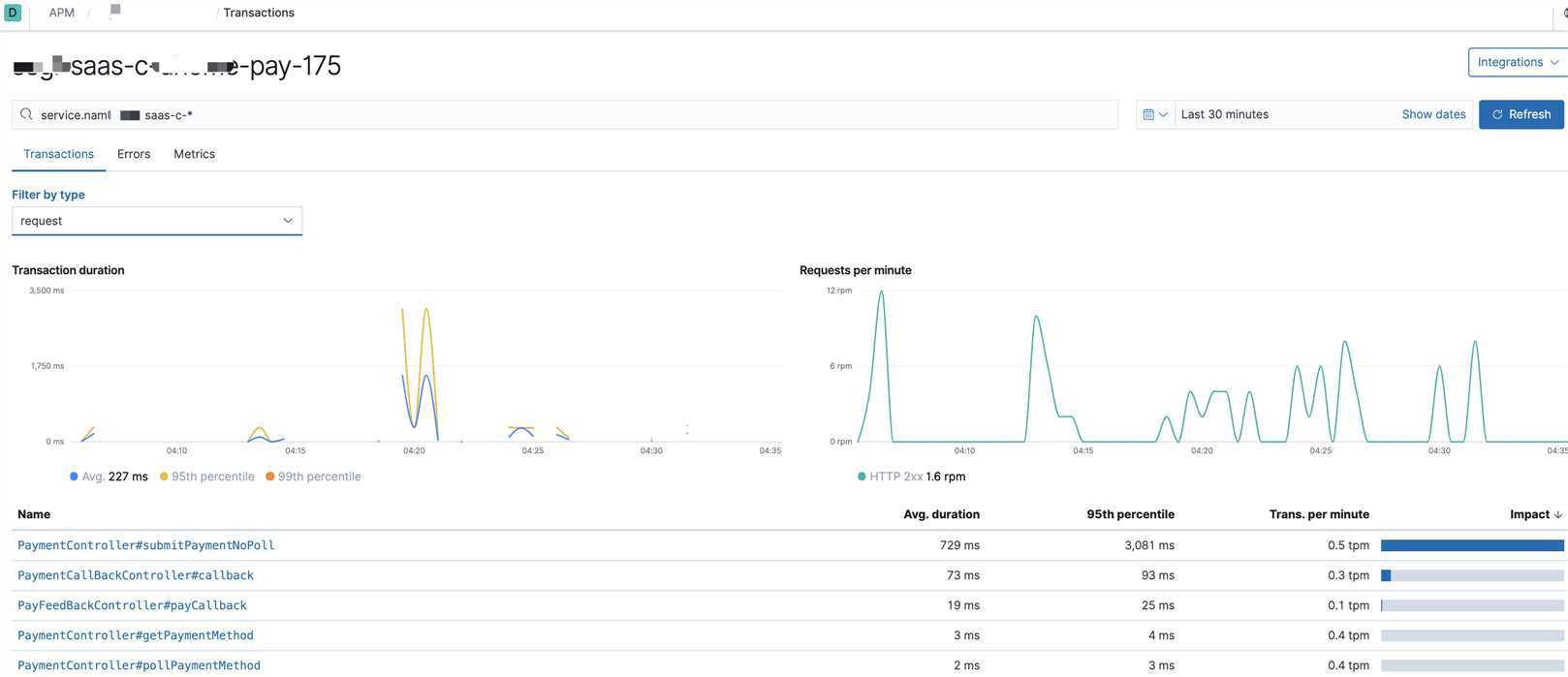
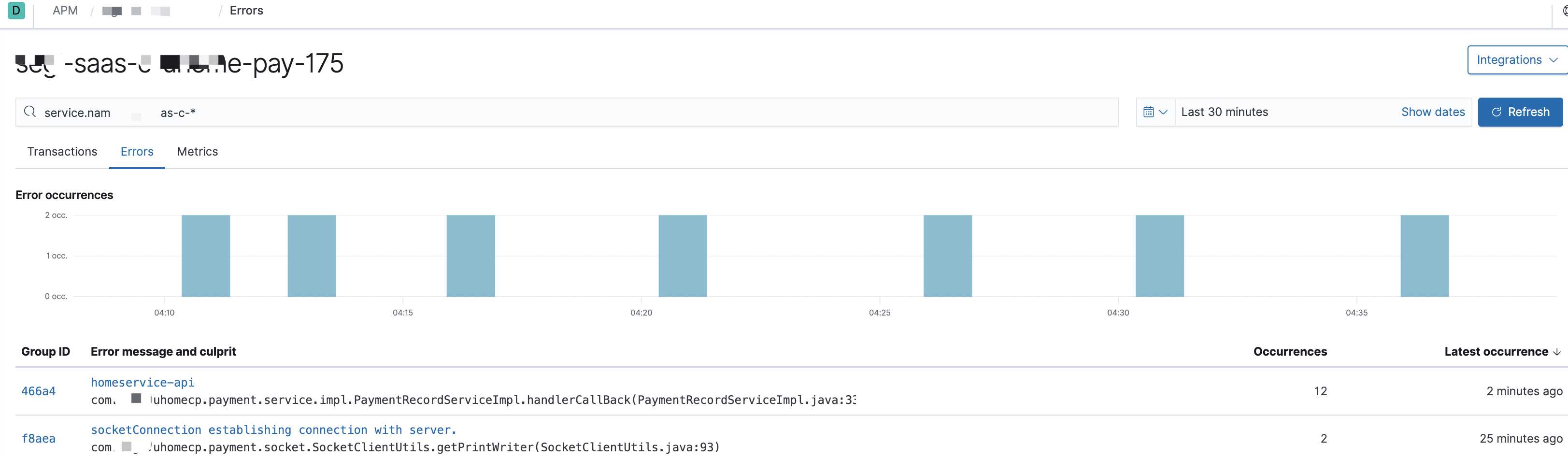
- 调用栈、链路、进程监控指标我们使用的代理方式:Elastic APM,这样对于业务侧的程序无需任何改动。对于已经在运营中的业务系统来说,为了加入监控而需要改动代码,那是不可取的,也是无法接受的。Elastic APM可以帮我们收集http接口的调用链路、内部方法调用栈、使用的sql、进程的cpu、内存使用指标等。可能有人会有疑问,用了Elastic APM,其它日志基本都可以不用采集了。还要用filebeat干嘛?是的,Elastic APM采集的信息确实能帮我们定位80%以上的问题,但是它不是所有的语言都支持的比如:C。其二、它无法帮你采集你想要的非error日志和所谓的关键日志,比如:某个接口调用时出了错,你想看出错时间点的前后日志;还有打印业务相关方便做分析的日志。其三、自定义的业务异常,该异常属于非系统异常,属于业务范畴,APM会把这类异常当成系统异常上报,如果你后面对系统异常做告警,那这些异常将会干扰告警的准确度,你也不能去过滤业务异常,因为自定义的业务异常种类也不少。
- 同时我们对agent进行了二开。采集更详细的gc、堆栈、内存、线程信息。
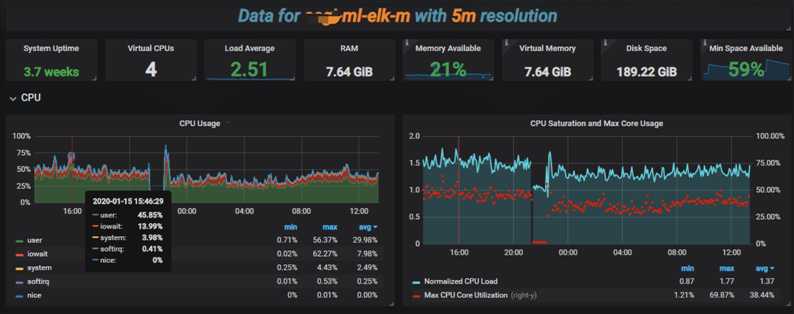
- 服务器采集我们采用普罗米修斯。
- 由于我们是saas服务化,服务N多,很多的服务日志做不到统一规范化,这也跟历史遗留问题有关,一个与业务系统无关的系统去间接或直接地去对接已有的业务系统,为了适配自己而让其更改代码,那是推不动的。牛逼的设计是让自己去兼容别人,把对方当成攻击自己的对象。很多日志是没有意义的,比如:开发过程中为了方便排查跟踪问题,在if else里打印只是有标志性的日志,代表是走了if代码块还是else代码块。甚至有些服务还打印着debug级别的日志。在成本、资源的有限条件下,所有所有的日志是不现实的,即使资源允许,一年下来将是一比很大的开销。所以我们采用了过滤、清洗、动态调整日志优先级采集等方案。首先把日志全量采集到kafka集群中,设定一个很短的有效期。我们目前设置的是一个小时,一个小时的数据量,我们的资源暂时还能接受。
- Log Streams是我们的日志过滤、清洗的流处理服务。我们采用Kafka Streams作ETL流处理。通过界面化配置实现动态过滤清洗的规则。大概规则如下:
- 界面化配置日志采集。默认error级别的日志全量采集
- 以错误时间点为中心,在流处理中开窗,辐射上下可配的N时间点采集非error级别日志,默认只采info级别
- 每个服务可配100个关键日志,默认关键日志全量采集
- sql日志按配置耗时过滤
- 高峰时段按业务类型的权重指标、日志等级指标、每个服务在一个时段内日志最大限制量指标、时间段指标等动态清洗过滤日志
- 根据不同的时间段动态收缩时间窗口
- 日志索引生成规则:按服务生成的日志文件规则生成对应的index,比如:某个服务日志分为:debug、info、error、xx_keyword,那么生成的索引也是debug、info、error、xx_keyword加日期作后缀。这样做的目的是为研发以原习惯性地去使用日志
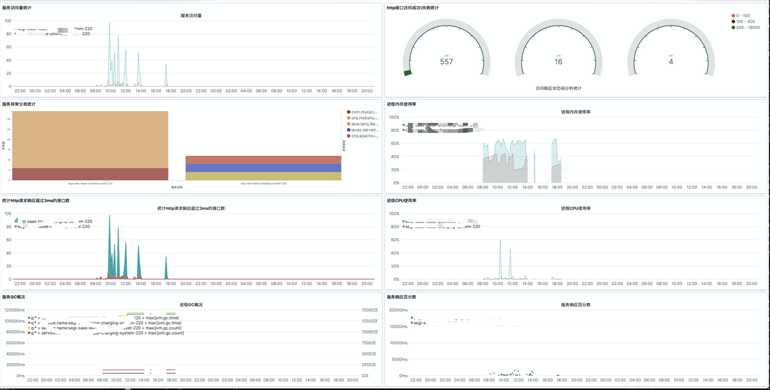
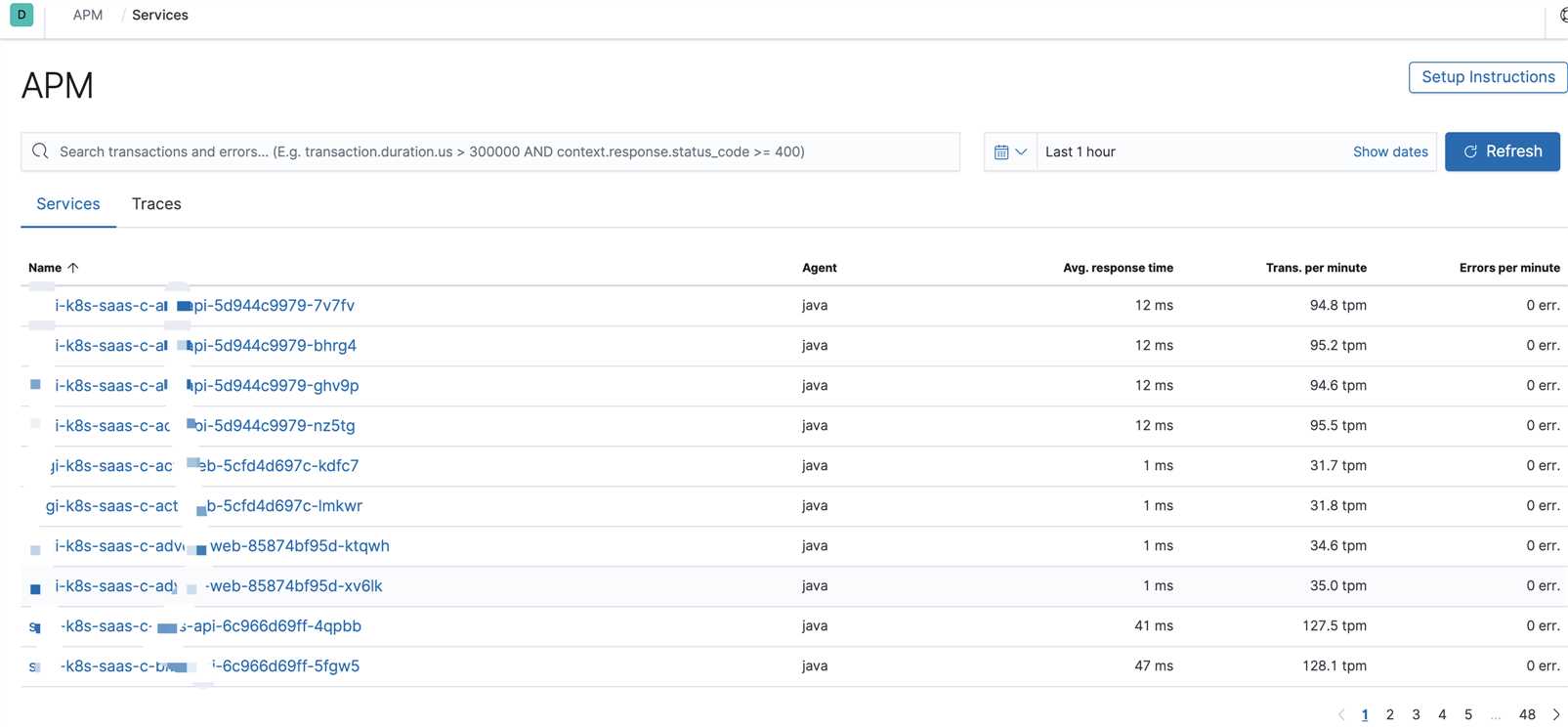
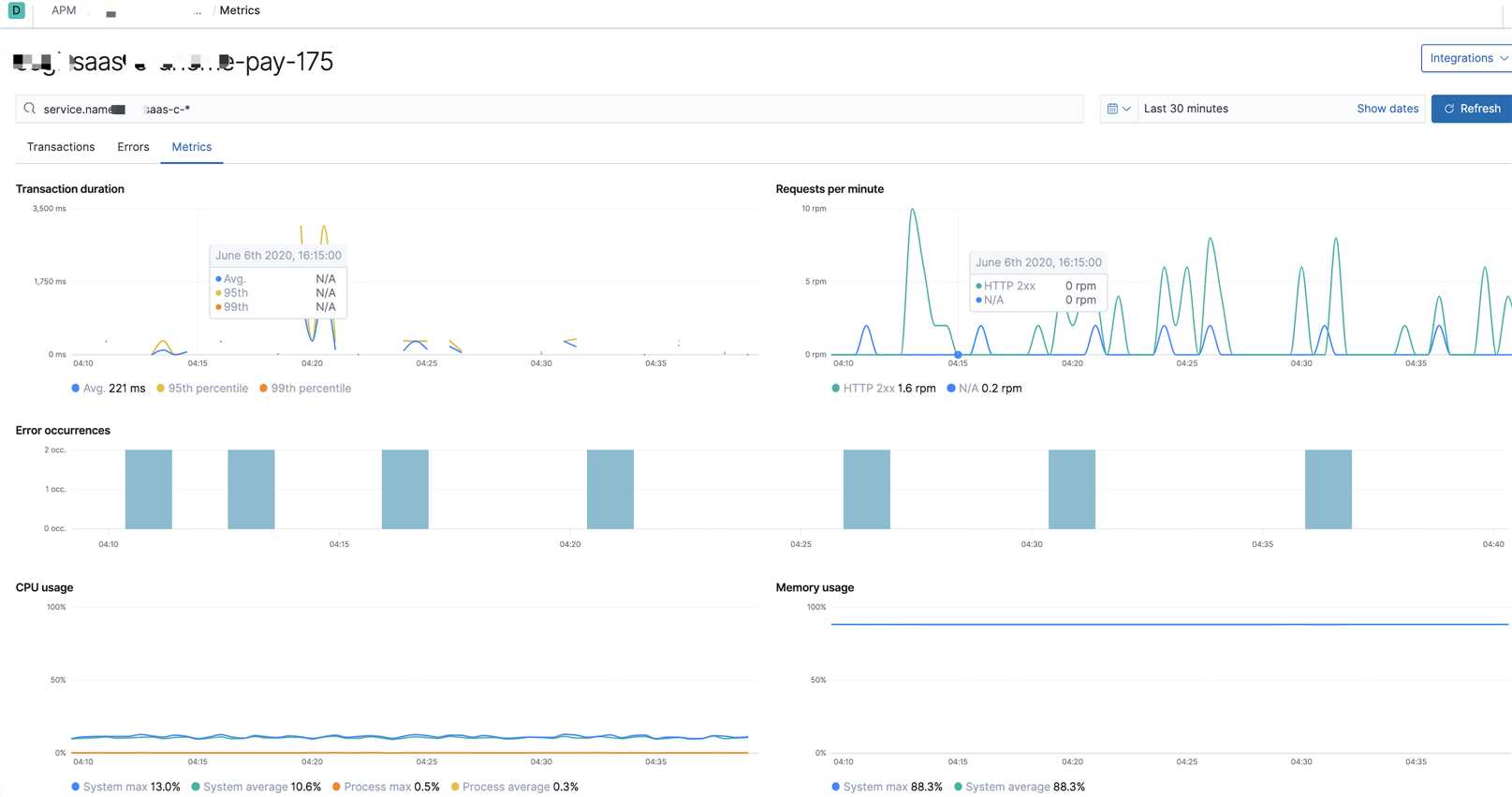
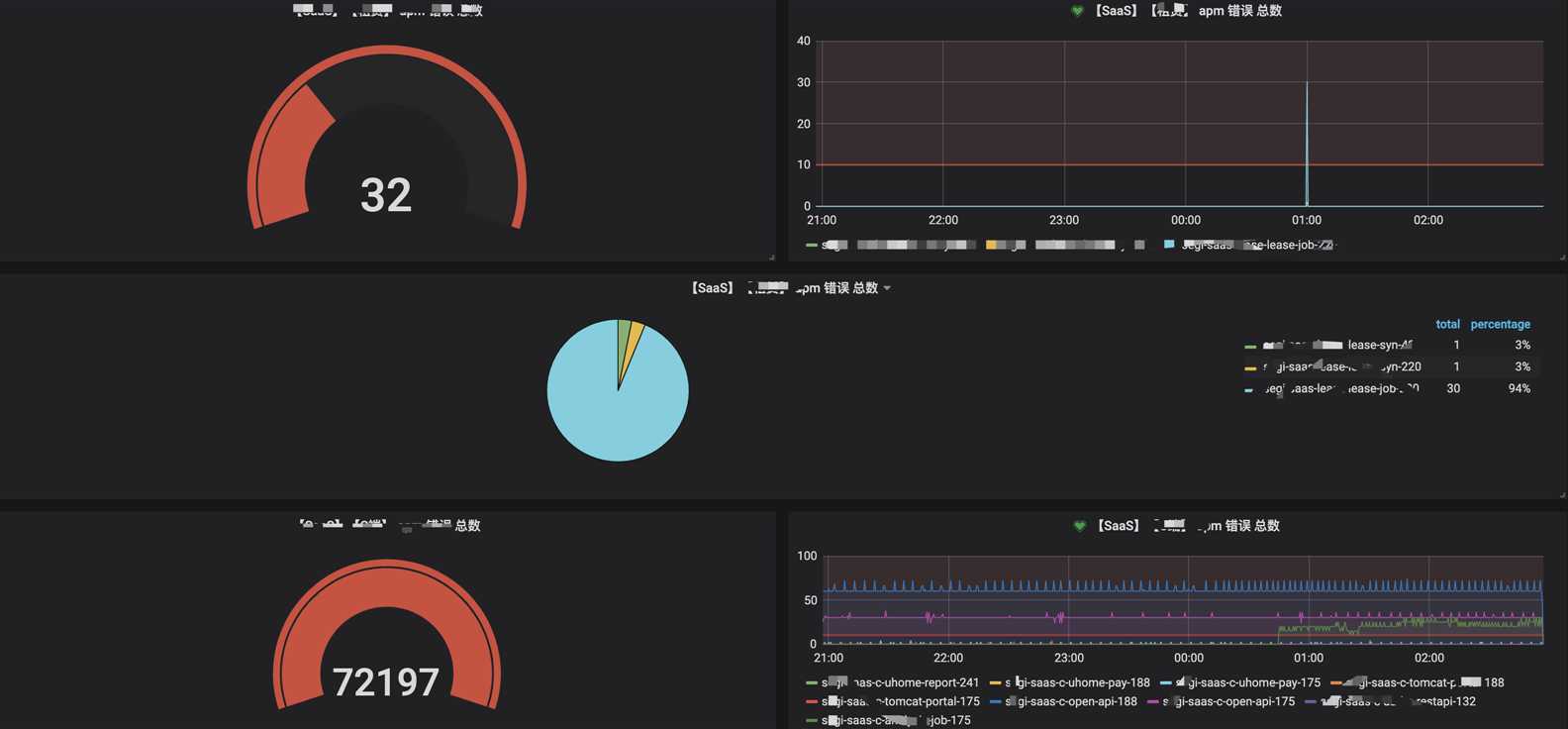
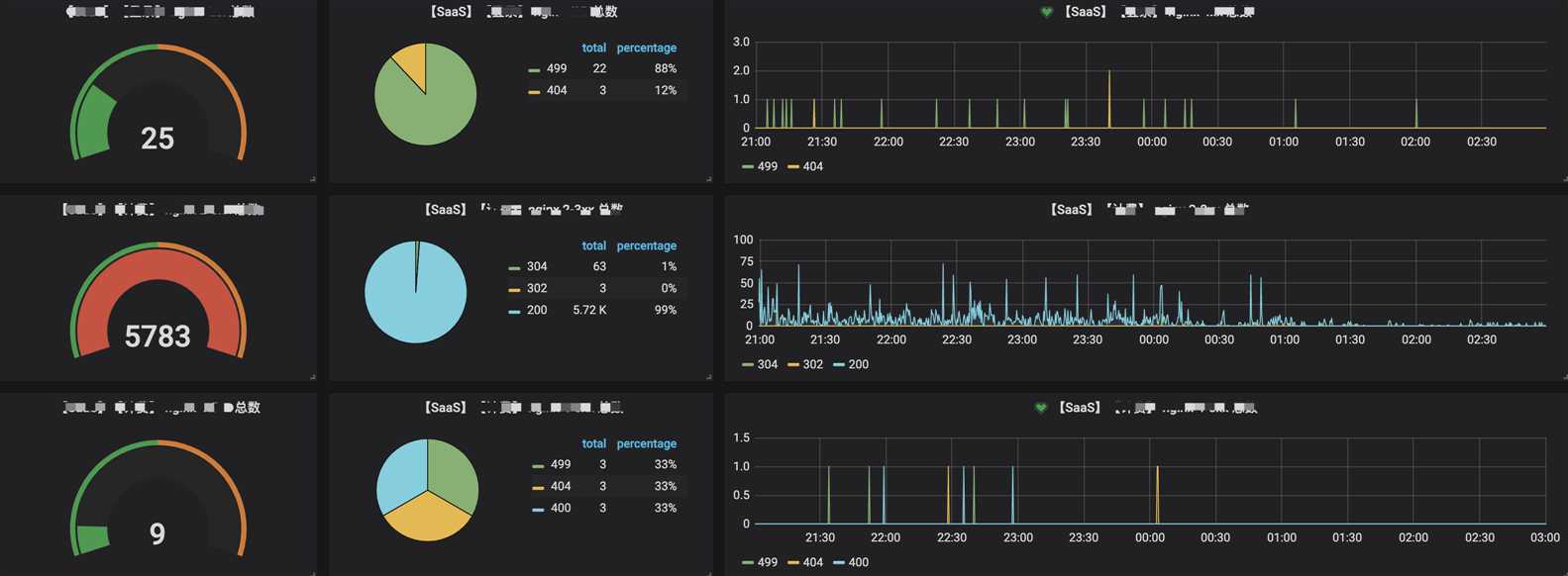
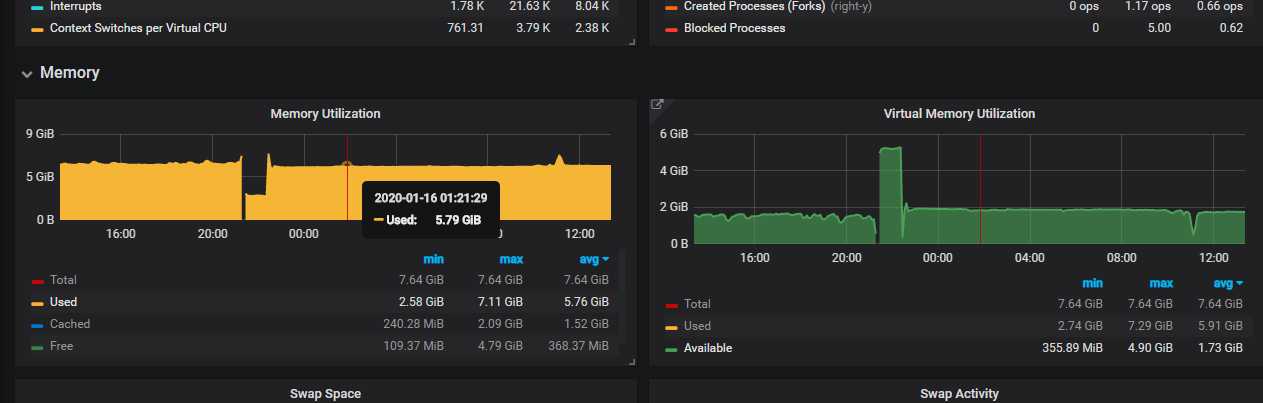
7. 可视化界面我们主要使用grafana,它支持的众多数据源中,其中就有普罗米修斯和elasticsearch,与普罗米修斯可谓是无缝对接。而kibana我们主要用于apm的可视分析
日志可视化
出于安全考虑,公司线上可视化数据不便于使用,以下只是简单的上几张开发环境的效果图
权限认证


分析可视化
声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文链接,否则保留追究法律责任的权利
以上是关于微服务海量日志监控平台的主要内容,如果未能解决你的问题,请参考以下文章
日存储量超10TB,海量数据挑战下腾讯全链路日志监控平台实践