TB级微服务海量日志监控平台
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TB级微服务海量日志监控平台相关的知识,希望对你有一定的参考价值。
来源:cnblogs.com/dengbangpang/
p/12961593.html

本文主要介绍怎么使用 ELK Stack 帮助我们打造一个支撑起日产 TB 级的日志监控系统。在企业级的微服务环境中,跑着成百上千个服务都算是比较小的规模了。在生产环境上,日志扮演着很重要的角色,排查异常需要日志,性能优化需要日志,业务排查需要业务等等。
然而在生产上跑着成百上千个服务,每个服务都只会简单的本地化存储,当需要日志协助排查问题时,很难找到日志所在的节点。也很难挖掘业务日志的数据价值。
那么将日志统一输出到一个地方集中管理,然后将日志处理化,把结果输出成运维、研发可用的数据是解决日志管理、协助运维的可行方案,也是企业迫切解决日志的需求。
我们的解决方案
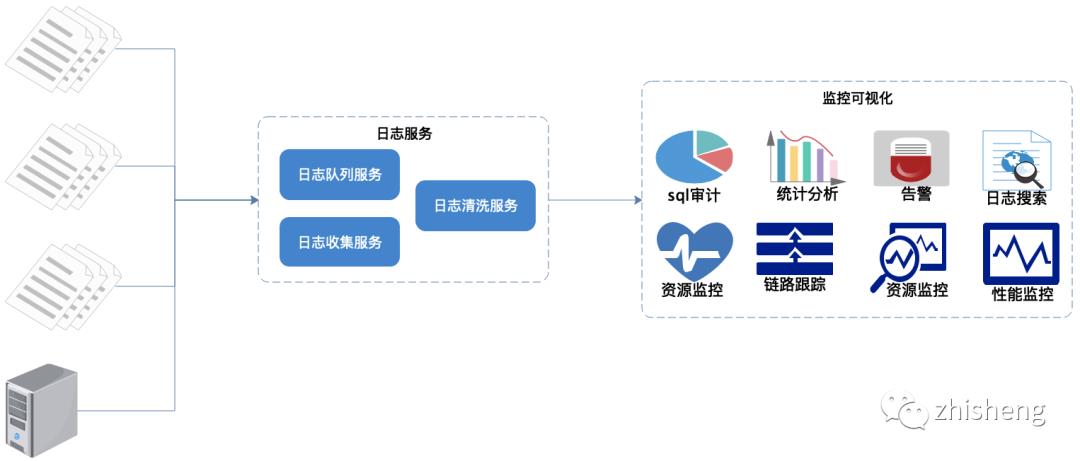
通过上面的需求我们推出了日志监控系统,如上图 :
日志统一收集、过滤清洗。
生成可视化界面、监控,告警,日志搜索。

功能流程概览如上图 :
在每个服务节点上埋点,实时采集相关日志。
统一日志收集服务、过滤、清洗日志后生成可视化界面、告警功能。
我们的架构

① 日志文件采集端我们使用 FileBeat,运维通过我们的后台管理界面化配置,每个机器对应一个 FileBeat,每个 FileBeat日志对应的 Topic 可以是一对一、多对一,根据日常的日志量配置不同的策略。
除了采集业务服务日志外,我们还收集了 mysql 的慢查询日志和错误日志,还有别的第三方服务日志,如:nginx 等。
最后结合我们的自动化发布平台,自动发布并启动每一个 FileBeat 进程。
② 调用栈、链路、进程监控指标我们使用的代理方式:Elastic APM,这样对于业务侧的程序无需任何改动。
对于已经在运营中的业务系统来说,为了加入监控而需要改动代码,那是不可取的,也是无法接受的。
Elastic APM 可以帮我们收集 HTTP 接口的调用链路、内部方法调用栈、使用的SQL、进程的 CPU、内存使用指标等。
可能有人会有疑问,用了 Elastic APM,其它日志基本都可以不用采集了。还要用 FileBeat 干嘛?
是的,Elastic APM 采集的信息确实能帮我们定位 80% 以上的问题,但是它不是所有的语言都支持的比如:C。
其二、它无法帮你采集你想要的非 Error 日志和所谓的关键日志,比如:某个接口调用时出了错,你想看出错时间点的前后日志;还有打印业务相关方便做分析的日志。
其三、自定义的业务异常,该异常属于非系统异常,属于业务范畴,APM 会把这类异常当成系统异常上报。
如果你后面对系统异常做告警,那这些异常将会干扰告警的准确度,你也不能去过滤业务异常,因为自定义的业务异常种类也不少。
③ 同时我们对 Agent 进行了二开。采集更详细的 GC、堆栈、内存、线程信息。
④ 服务器采集我们采用普罗米修斯。
⑤ 由于我们是 Saas 服务化,服务 N 多,很多的服务日志做不到统一规范化,这也跟历史遗留问题有关,一个与业务系统无关的系统去间接或直接地去对接已有的业务系统,为了适配自己而让其更改代码,那是推不动的。
牛逼的设计是让自己去兼容别人,把对方当成攻击自己的对象。很多日志是没有意义的,比如:开发过程中为了方便排查跟踪问题,在 if else 里打印只是有标志性的日志,代表是走了 if 代码块还是 else 代码块。
甚至有些服务还打印着 Debug 级别的日志。在成本、资源的有限条件下,所有所有的日志是不现实的,即使资源允许,一年下来将是一比很大的开销。
所以我们采用了过滤、清洗、动态调整日志优先级采集等方案。首先把日志全量采集到 Kafka 集群中,设定一个很短的有效期。
我们目前设置的是一个小时,一个小时的数据量,我们的资源暂时还能接受。
⑥ Log Streams 是我们的日志过滤、清洗的流处理服务。为什么还要 ETL 过滤器呢?
因为我们的日志服务资源有限,但不对啊,原来的日志分散在各各服务的本地存储介质上也是需要资源的哈。
现在我们也只是汇集而已哈,收集上来后,原来在各服务上的资源就可以释放掉日志占用的部分资源了呀。
没错,这样算确实是把原来在各服务上的资源化分到了日志服务资源上来而已,并没有增加资源。
不过这只是理论上的,在线上的服务,资源扩大容易,收缩就没那么容易了,实施起来极其困难。
所以短时间内是不可能在各服务上使用的日志资源化分到日志服务上来的。这样的话,日志服务的资源就是当前所有服务日志使用资源的量。
随存储的时间越长,资源消耗越大。如果解决一个非业务或非解决不可的问题,在短时间内需要投入的成本大于解决当前问题所带来收益的话,我想,在资金有限的情况下,没有哪个领导、公司愿意采纳的方案。
所以从成本上考虑,我们在 Log Streams 服务引入了过滤器,过滤没有价值的日志数据,从而减少了日志服务使用的资源成本。
技术我们采用 Kafka Streams 作为 ETL 流处理。通过界面化配置实现动态过滤清洗的规则。
大概规则如下 :
界面化配置日志采集。默认 Error 级别的日志全量采集。
以错误时间点为中心,在流处理中开窗,辐射上下可配的 N 时间点采集非 Error 级别日志,默认只采 info 级别。
每个服务可配 100 个关键日志,默认关键日志全量采集。
在慢 SQL 的基础上,按业务分类配置不同的耗时再次过滤。
按业务需求实时统计业务 SQL,比如:高峰期阶段,统计一小时内同类业务 SQL 的查询频率。可为 DBA 提供优化数据库的依据,如按查询的 SQL 创建索引。
高峰时段按业务类型的权重指标、日志等级指标、每个服务在一个时段内日志最大限制量指标、时间段指标等动态清洗过滤日志。
根据不同的时间段动态收缩时间窗口。
日志索引生成规则:按服务生成的日志文件规则生成对应的 index,比如:某个服务日志分为:debug、info、error、xx_keyword,那么生成的索引也是 debug、info、error、xx_keyword 加日期作后缀。这样做的目的是为研发以原习惯性地去使用日志。
⑦可视化界面我们主要使用 Grafana,它支持的众多数据源中,其中就有普罗米修斯和 Elasticsearch,与普罗米修斯可谓是无缝对接。而 Kibana 我们主要用于 APM 的可视分析。
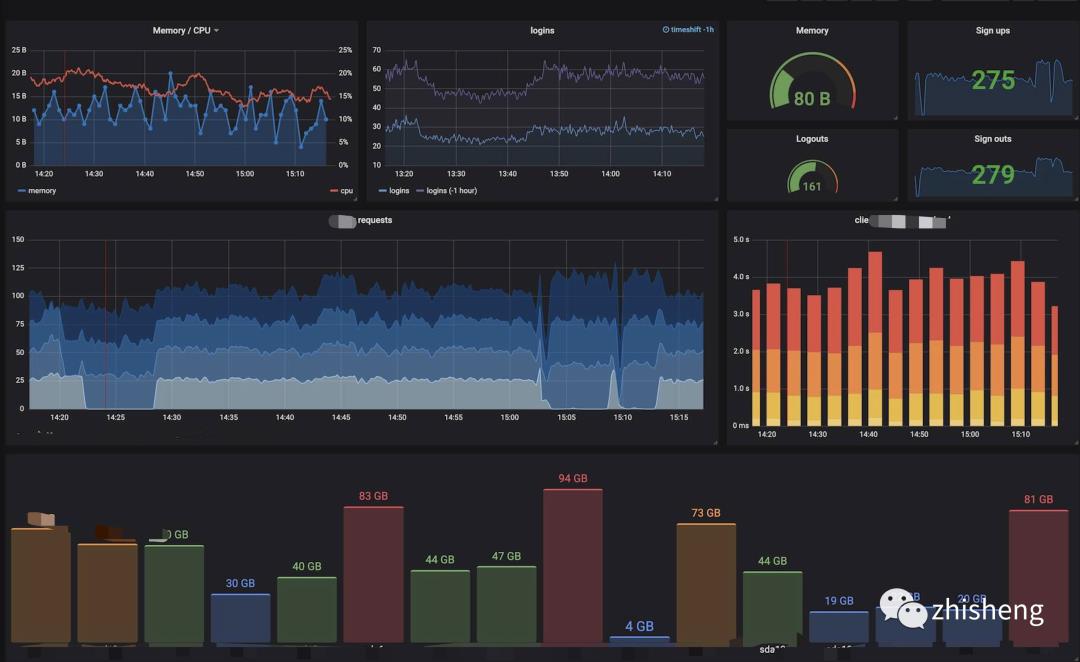
日志可视化
我们的日志可视化如下图 :





end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统
关于数据中台的深度思考与总结(干干货)
日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。点个赞+在看,少个 bug 👇以上是关于TB级微服务海量日志监控平台的主要内容,如果未能解决你的问题,请参考以下文章