Spark内核源码继续五:Master原理解析和源码解析
Posted xiaofeiyang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark内核源码继续五:Master原理解析和源码解析相关的知识,希望对你有一定的参考价值。
上篇已经降到AppClient找Master进行注册,本章主要解析Master的原理和源码解析
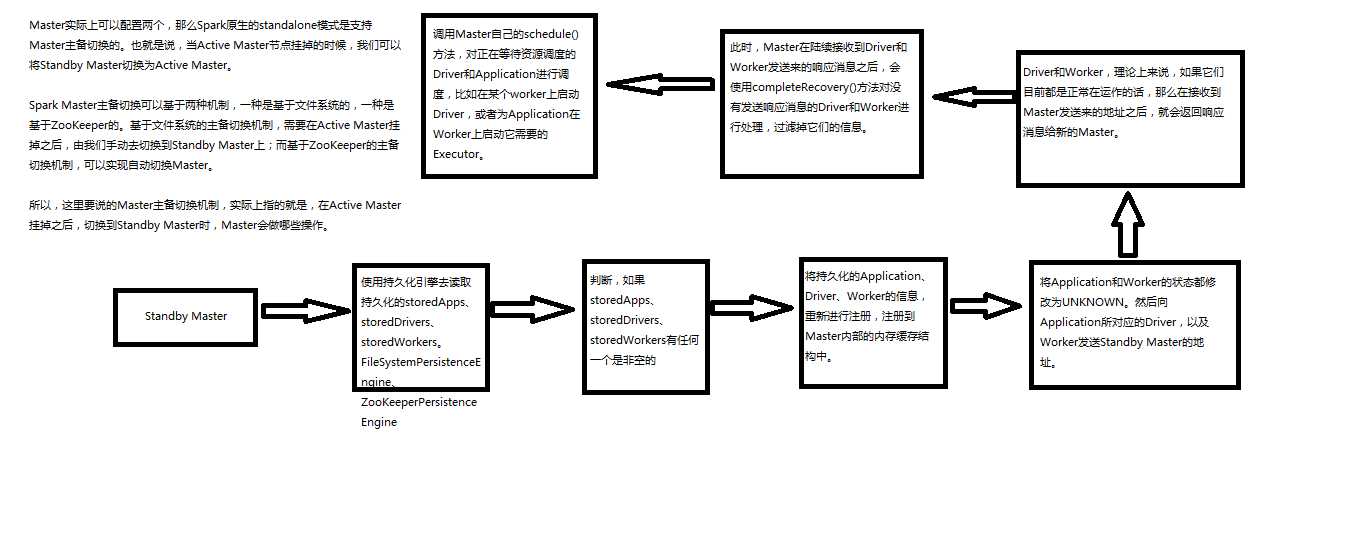
1、Master的主备切换原理
package org.apache.spark.deploy.master
completeRecovery,过滤没有响应的worker,app,drivers,从内存缓存中移除,从组件缓存中移除,从持久化机制中移除。
workers.filter(_.state == WorkerState.UNKNOWN).foreach(removeWorker),过滤掉没有响应的Worker,并且移除没有响应的
apps.filter(_.state == ApplicationState.UNKNOWN).foreach(finishApplication
// Reschedule drivers which were not claimed by any workers
drivers.filter(_.worker.isEmpty).foreach { d => }
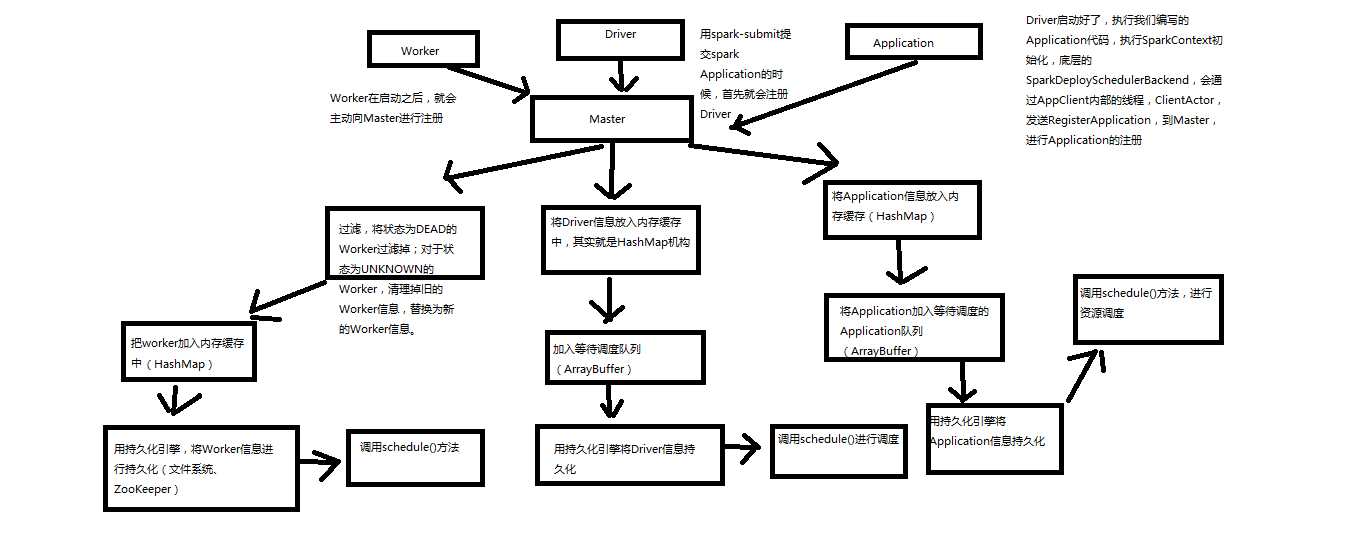
2、注册机制原理和源码分析
1、worker会向master注册,过滤将状态为Dead过滤掉,对于UNKNOW的状态的设置为Dead,清理掉旧的Worker信息,替换成新的。将Worker信息加入内存缓存中,用持久化引擎将Worker信息进行持久化(文件系统或者zookeeper),最后调用schedule方法。
2、Driver会向master注册,将Driver信息放入内存缓存中,hashmap中,加入等待调度执行队列ArrayBuffer,调用持久化引擎将Driver信息进行持久化,最后调用schedule方法
3、用Spark-submit提交的Spark Application首先就是注册Driver,Driver启动好了,执行我们编写的Application代码,执行SparkContext初始化,底层的SparkDeploySchedulebackend,会通过AppClient内部的线程,ClientActor发送RegisterApplication,到Master进行Application的注册。将Application放入缓存,hashMap,将Application加入等待调度的Application队列ArrayBuffer,用持久化引擎将Application持久化。然后调用schedule方法。
case RegisterApplication(description)
CreateApplication,创建一个Application对象,然后采用这个对象进行注册
registerApplication
//加入内存
waitingApps //加入等待调度队列,这是一个ArrayBuffer对象
persistenceEngine.addApplication(app),调用持久化引擎持久化application
sender ! RegisteredApplication(app.id, masterUrl),反向向SparkDeploySchedulerBackend的Appclient的ClientActor,发送消息也就是RedisterdApplication
3、状态改变原理和源码分析
def removeDriver(driverId: String, finalState: DriverState, exception: Option[Exception]) { // 找到对应的Driver drivers.find(d => d.id == driverId) match { // 找到后 case Some(driver) => logInfo(s"Removing driver: $driverId") // 将Driver从内存移除 drivers -= driver if (completedDrivers.size >= RETAINED_DRIVERS) { val toRemove = math.max(RETAINED_DRIVERS / 10, 1) completedDrivers.trimStart(toRemove) } // 向CompleteDrivers中加入Driver completedDrivers += driver // 使用持久化引擎移除Driver persistenceEngine.removeDriver(driver) // 设置Driver的状态和异常 driver.state = finalState driver.exception = exception // 将driver所在的worker,移除Driver driver.worker.foreach(w => w.removeDriver(driver)) // 调用schedule方法 schedule() case None => logWarning(s"Asked to remove unknown driver: $driverId") } }
case ExecutorStateChanged(appId, execId, state, message, exitStatus) => { val execOption = idToApp.get(appId).flatMap(app => app.executors.get(execId)) execOption match { // 如果有值 case Some(exec) => { val appInfo = idToApp(appId) exec.state = state if (state == ExecutorState.RUNNING) { appInfo.resetRetryCount() } // 向Driver发送ExecutorUpdated消息 exec.application.driver ! ExecutorUpdated(execId, state, message, exitStatus) if (ExecutorState.isFinished(state)) { // Remove this executor from the worker and app logInfo(s"Removing executor ${exec.fullId} because it is $state") // 从app中移除缓存worker appInfo.removeExecutor(exec) // 从运行的executor的worker中移除executor exec.worker.removeExecutor(exec) // 判断executor退出状态 val normalExit = exitStatus == Some(0) // Only retry certain number of times so we don‘t go into an infinite loop. if (!normalExit) { // 判断重试次数,如果没有达到最大次数就重新调度 if (appInfo.incrementRetryCount() < ApplicationState.MAX_NUM_RETRY) { schedule() } else { // 否则就移除application val execs = appInfo.executors.values if (!execs.exists(_.state == ExecutorState.RUNNING)) { logError(s"Application ${appInfo.desc.name} with ID ${appInfo.id} failed " + s"${appInfo.retryCount} times; removing it") removeApplication(appInfo, ApplicationState.FAILED) } } } } } case None => logWarning(s"Got status update for unknown executor $appId/$execId") } }
4、资源调度原理和源码分析
也就是schedule方法
driver的调度机制
private def schedule() { // 判断master状态不是ALIVE的话直接返回 if (state != RecoveryState.ALIVE) { return } // First schedule drivers, they take strict precedence over applications // Randomization helps balance drivers // 将传入的集合元素随机打乱,取出所有注册的Worker。将所有alive的worker随机打乱 val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE)) // 拿到数量 val numWorkersAlive = shuffledAliveWorkers.size var curPos = 0 // 首先调度driver,什么情况下会注册driver,并且会导致driver调度 // 只有yarn-cluster,才会注册driver,standalone和yarn-client模式下,都会在本地直接创建启动driver,而不会注册driver // 更不可能调度driver。driver的调度机制,遍历waitingDrivers ArrayBuffer for (driver <- waitingDrivers.toList) { // iterate over a copy of waitingDrivers // We assign workers to each waiting driver in a round-robin fashion. For each driver, we // start from the last worker that was assigned a driver, and continue onwards until we have // explored all alive workers. var launched = false var numWorkersVisited = 0 // 只要还有还活着的worker没有被遍历到,那么就继续遍历,当前还没有启动driver,就是launced为false while (numWorkersVisited < numWorkersAlive && !launched) { val worker = shuffledAliveWorkers(curPos) numWorkersVisited += 1 // 如果当前worker空闲内存和cpu满足driver的需求, if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) { // 启动driver,并且将driver从waitingDrivers队列中移除 launchDriver(worker, driver) waitingDrivers -= driver launched = true } // 将指针移到下一个worker curPos = (curPos + 1) % numWorkersAlive } }
// 在某个worker上启动driver def launchDriver(worker: WorkerInfo, driver: DriverInfo) { logInfo("Launching driver " + driver.id + " on worker " + worker.id) // driver加入内存的缓存结构,将worker内使用的内存和cpu数量加上driver所需要的数量 worker.addDriver(driver) // 同时也将worker加入driver的缓存结构中 driver.worker = Some(worker) // 然后调用worker的actor,给他发送LaunchDriver消息,让woker启动driver worker.actor ! LaunchDriver(driver.id, driver.desc) // 将driver的状态设置为running状态 driver.state = DriverState.RUNNING }
application调度机制
// Right now this is a very simple FIFO scheduler. We keep trying to fit in the first app // in the queue, then the second app, etc. // 首先呢Application的调度算法分两种,一种是spreadOutApps,另外一种是非spreadOtuApps算法 if (spreadOutApps) { // Try to spread out each app among all the nodes, until it has all its cores // 首先遍历waitingApps中的applicationInfo,过滤出要调度的applicationInfo for (app <- waitingApps if app.coresLeft > 0) { // 过滤出可以被application使用的worker,按照剩余内存倒序排列,也就是过滤出要能满足application的worker,并且没有启动过 // app 对应的executor val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE) .filter(canUse(app, _)).sortBy(_.coresFree).reverse val numUsable = usableWorkers.length // 创建一个空数组存储分配worker的cpu数量 val assigned = new Array[Int](numUsable) // Number of cores to give on each node // 获取到低要分配多少cpu,取app剩余要分配的cpu数量和work剩余cpu的最小值 var toAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum) var pos = 0 // 只要要分配的cpu还没有分配完就继续 // 通过这种算法,其实会将这个application,要启动的executor都平均分布到各个worker上去 // 比如有个20 cpu core要分配,实际会循环两遍worker,给每个worker分配一个1个core,最后每个worker分配2个core while (toAssign > 0) { // 每个worker如果空闲的cpu数量大于已经分配的cpu数量,worker还有可以分配的cpu if (usableWorkers(pos).coresFree - assigned(pos) > 0) { // 将总共要分配的cpu数量-1,因为这里已经决定在这个worker上分配一个cpu了 toAssign -= 1 // 给这个worker分配的数量加1 assigned(pos) += 1 } // 指针下移动一个 pos = (pos + 1) % numUsable } // Now that we‘ve decided how many cores to give on each node, let‘s actually give them // 给每个worker分配application要求的core后,遍历worker然后启动executor for (pos <- 0 until numUsable) { // 只要这个worker分配到core了 if (assigned(pos) > 0) { // 首先application内部缓存结构中,添加executor,并且创建executor对象,其中封装了给这个executor分配多少个cpu // spark-submit脚本里面可以指定要多少个executor,每个executor多少个cpu,多少内存,基于我们的机制,实际上最后executor的数量 // 以及executor的cpu的数量可以跟配置的不一样,因为我们是基于总的cpu数量来分配的,就是说要比如要3个executor,每个executor 3个cpu // 那么比如,有9给worker,每个有1个CPU,那么要分配9个core,每个worker分配一个core,每个worker启动一个executor, // 最后启动9个executor,每个executor有一个cpu core val exec = app.addExecutor(usableWorkers(pos), assigned(pos)) // 那么就在worker上启动executor launchExecutor(usableWorkers(pos), exec) // 将app状态设置为Running app.state = ApplicationState.RUNNING } } } } else { // Pack each app into as few nodes as possible until we‘ve assigned all its cores // 非spradout算法,将一个application尽可能少的分配到worker上去,遍历worker,并且需要分配的core的application。 // 总共有10个worker,每个10个core,app要分配20个core,只能分配到2个worker上每个worker10个core for (worker <- workers if worker.coresFree > 0 && worker.state == WorkerState.ALIVE) { // 遍历application,并且是还需要分配的application for (app <- waitingApps if app.coresLeft > 0) { // 判断worker是否可以被application使用 if (canUse(app, worker)) { // 取worker剩余和app所需core的最小值 val coresToUse = math.min(worker.coresFree, app.coresLeft) if (coresToUse > 0) { // 给app添加executor val exec = app.addExecutor(worker, coresToUse) launchExecutor(worker, exec) // 将app状态修改为running app.state = ApplicationState.RUNNING } } } } } }
以上是关于Spark内核源码继续五:Master原理解析和源码解析的主要内容,如果未能解决你的问题,请参考以下文章
Spark内核源码解析四:SparkContext原理解析和源码解析