Spark源码剖析:stage划分原理与源码剖析
Posted 小丑进场
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark源码剖析:stage划分原理与源码剖析相关的知识,希望对你有一定的参考价值。
引言
对于Spark开发人员来说,了解stage的划分算法可以让你知道自己编写的spark application被划分为几个job,每个job被划分为几个stage,每个stage包括了你的哪些代码,只有知道了这些之后,碰到某个stage执行特别慢或者报错,你才能快速定位到对应的代码,对其进行性能优化和排错。
stage划分原理与源码
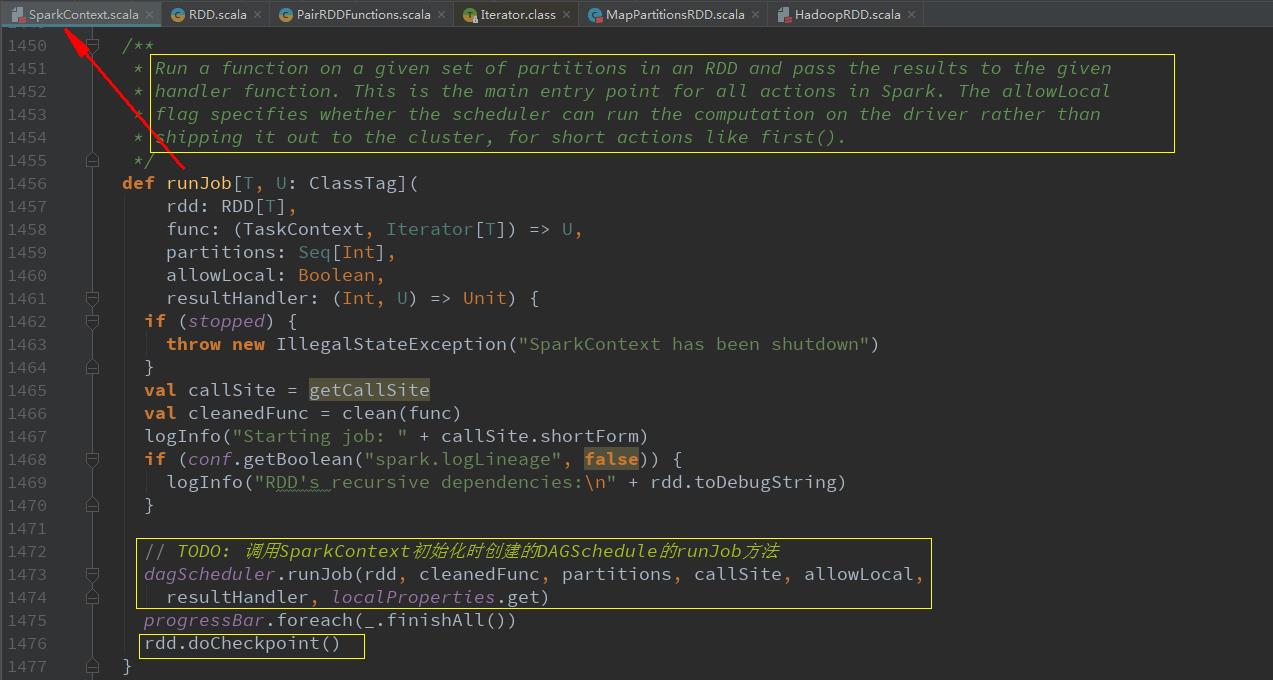
接着上期内核源码(五)的最后,每个action操作最终会调用SparkContext初始化时创建的DAGSchedule的runJob方法创建一个job:
那么这一篇就我们来探究一下每个job中stage到底是如何划分的
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, allowLocal, resultHandler, localProperties.get)
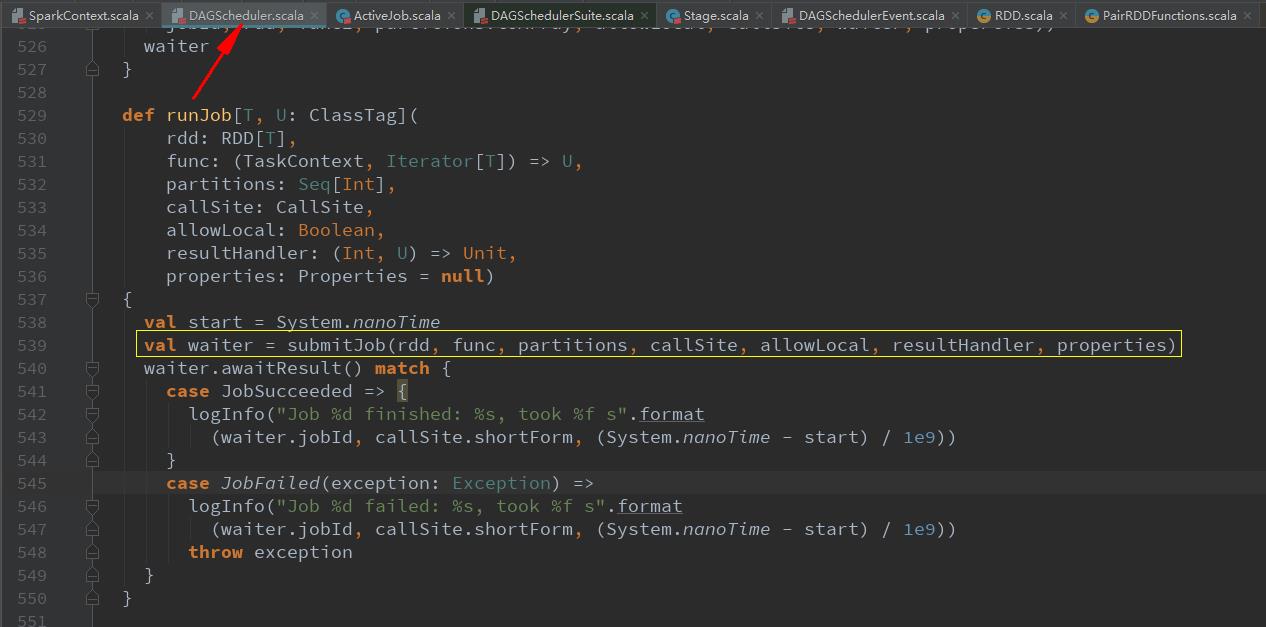
val waiter = submitJob(rdd, func, partitions, callSite, allowLocal, resultHandler, properties)
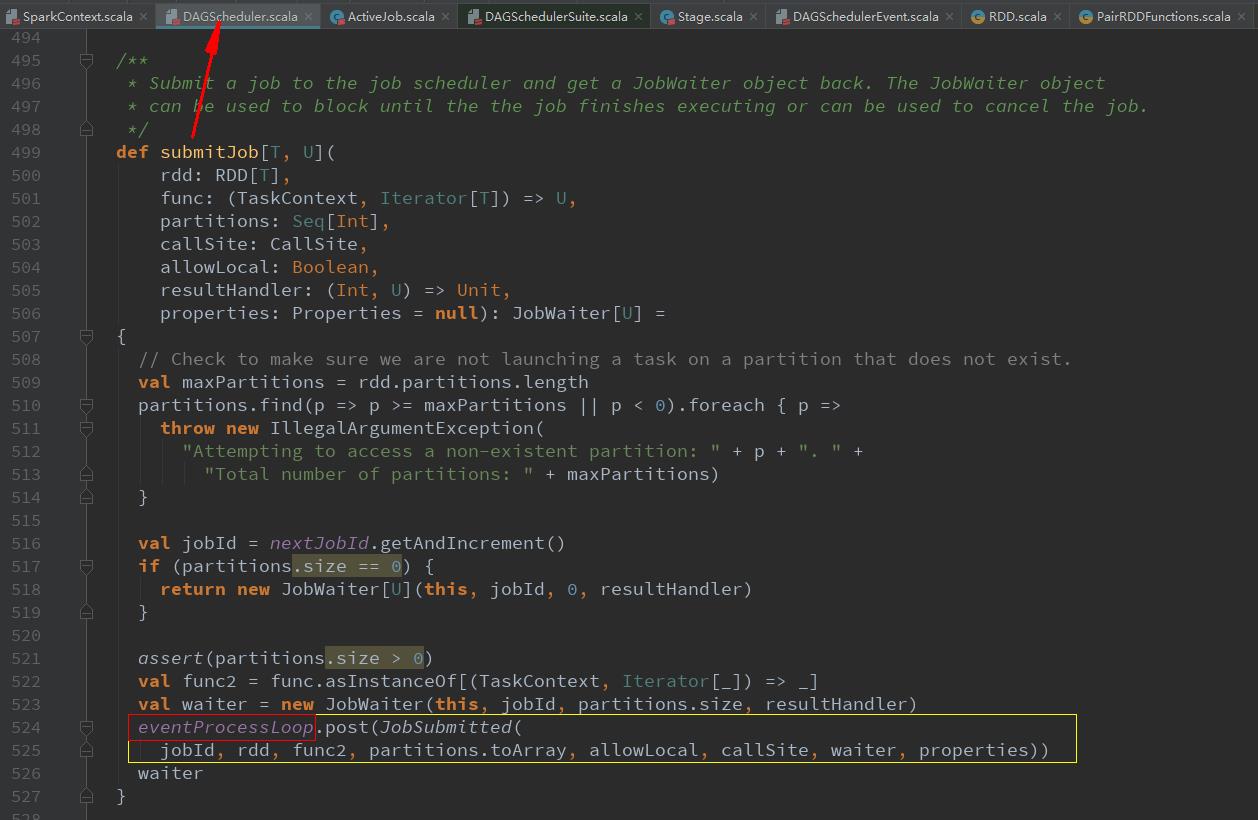
eventProcessLoop.post(JobSubmitted( jobId, rdd, func2, partitions.toArray, allowLocal, callSite, waiter, properties))

new DAGSchedulerEventProcessLoop(this)
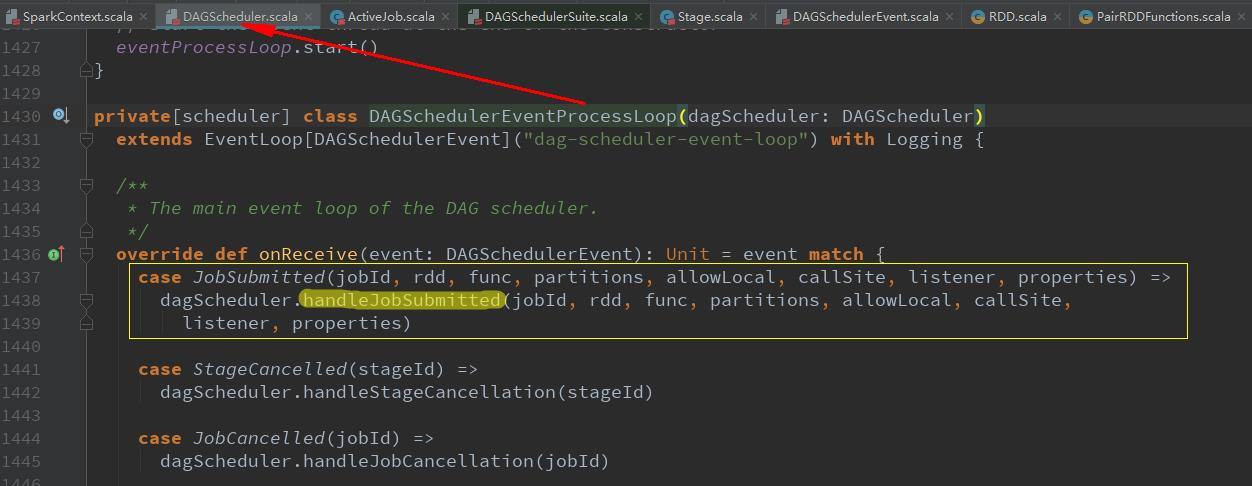
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, allowLocal, callSite, listener, properties)
跳转了这么多,我们终于找到了DAGScheduler的job调度核心入口handleJobSubmitted方法,该方法总共分为五步完成stage的划分和提交。
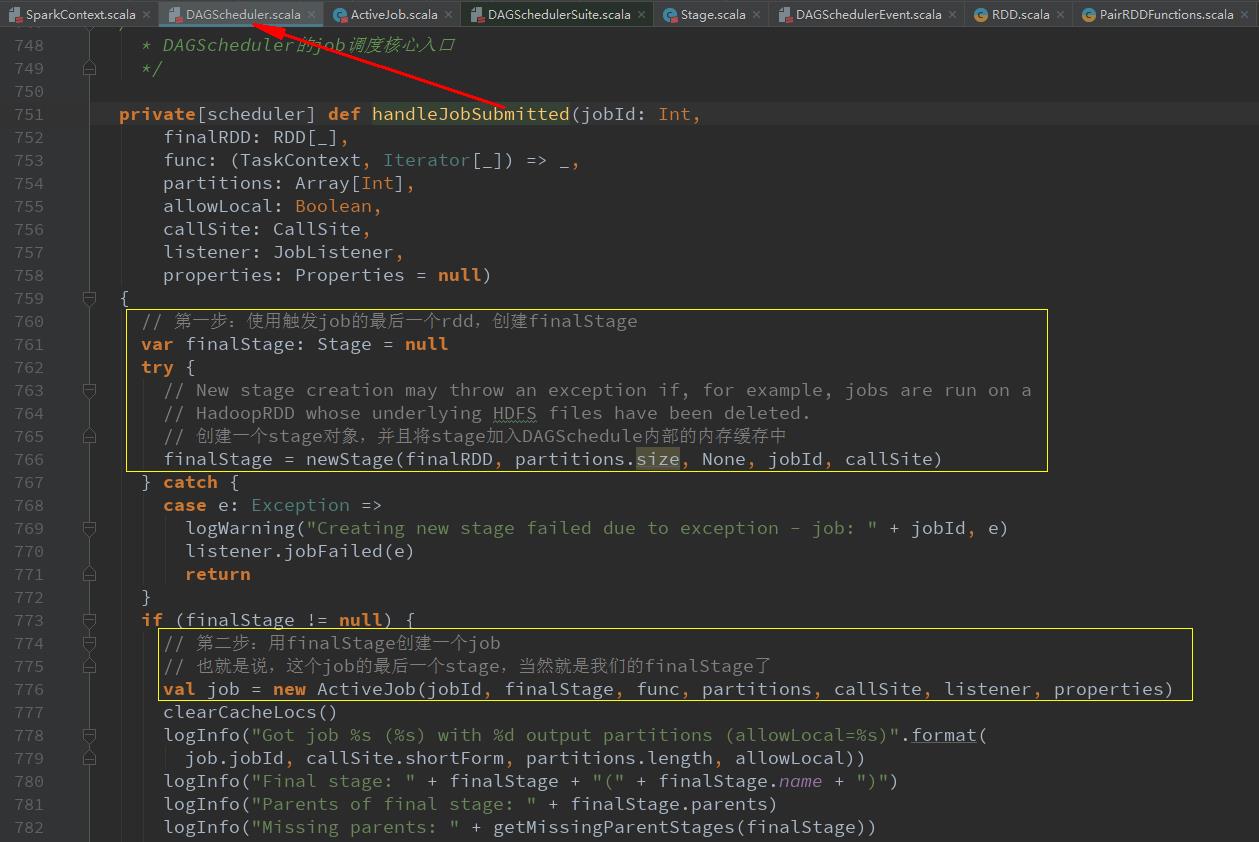
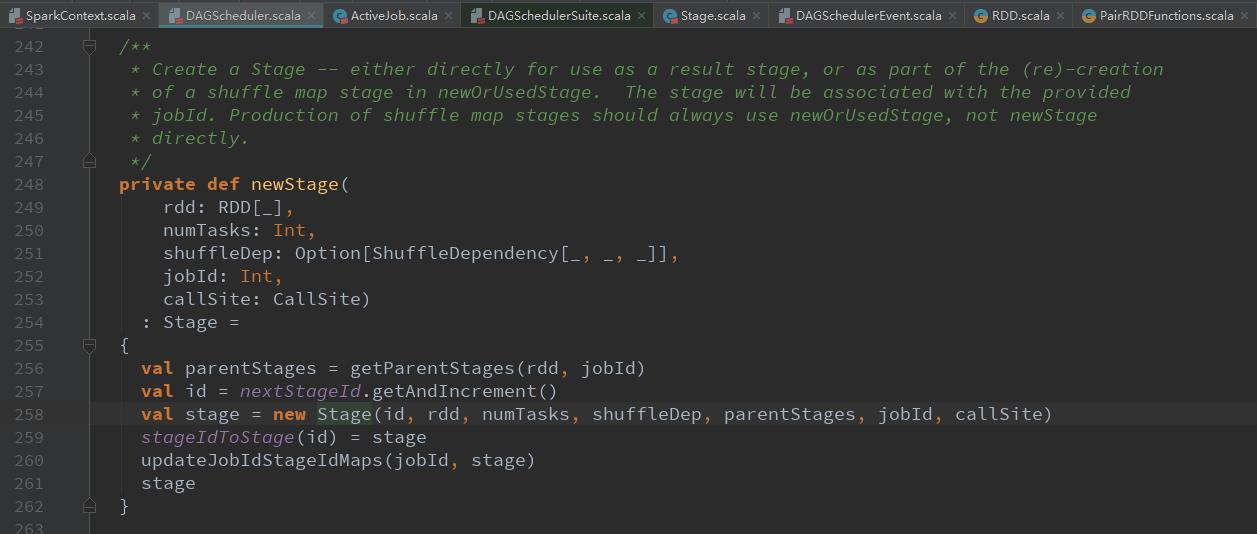
finalStage = newStage(finalRDD, partitions.size, None, jobId, callSite)使用触发job的最后一个rdd创建finalStage
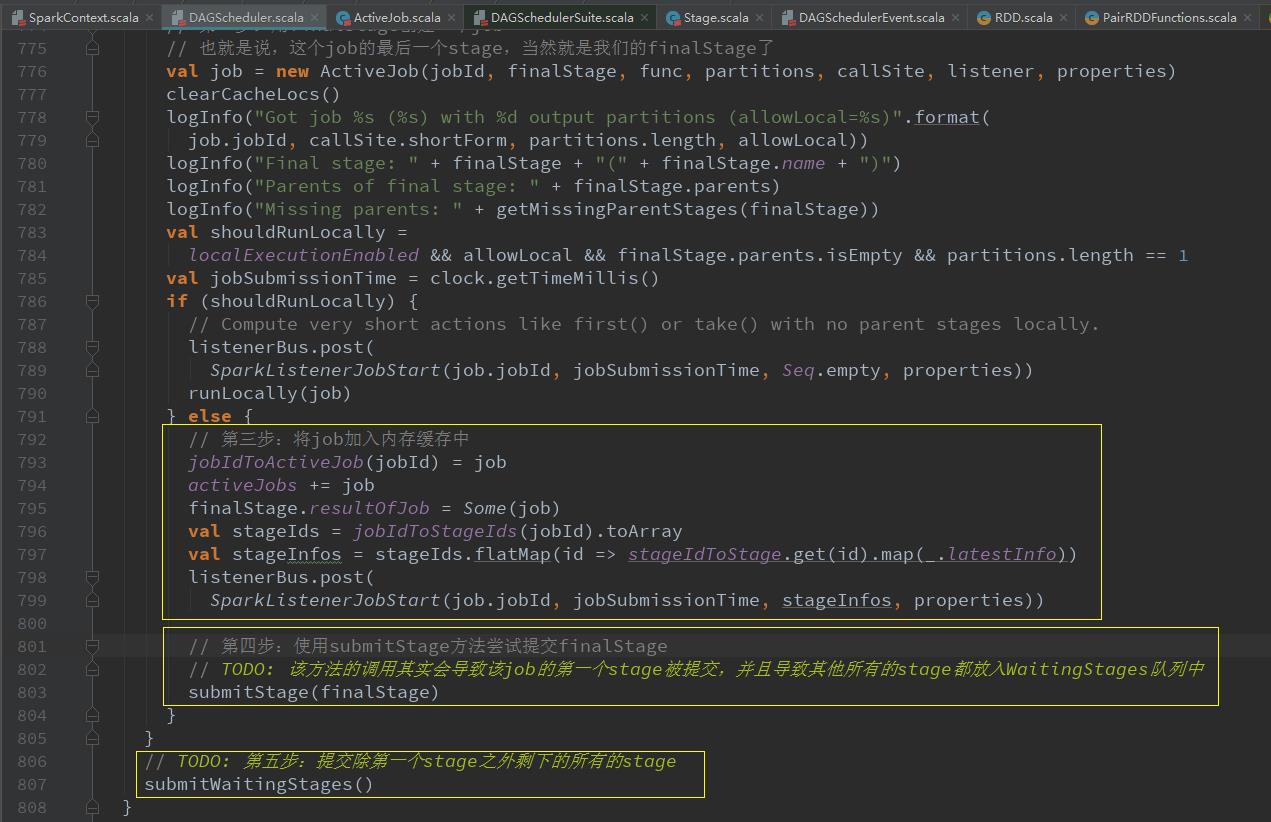
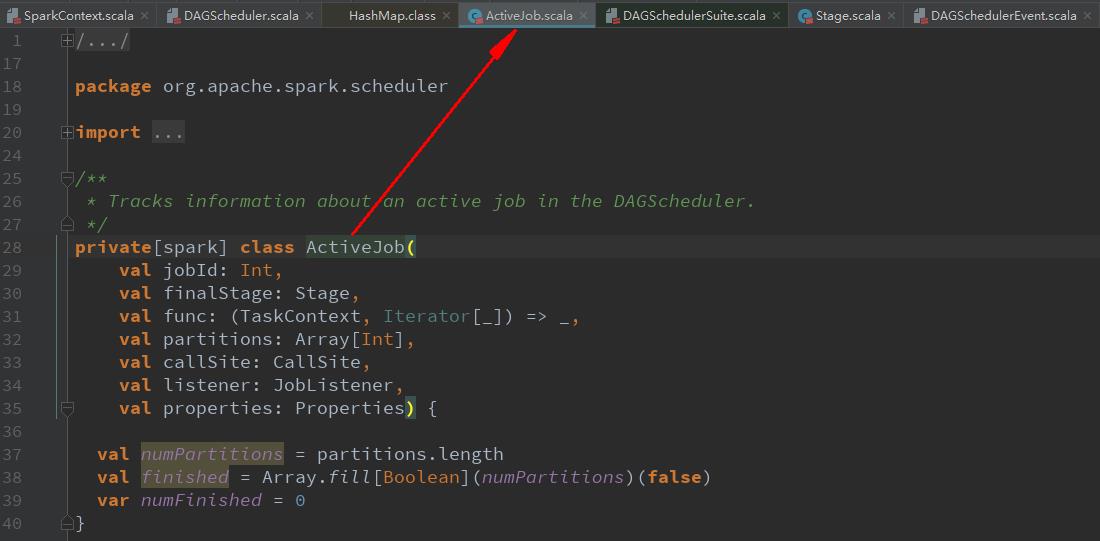
val job = new ActiveJob(jobId, finalStage, func, partitions, callSite, listener, properties)用finalStage创建一个job
submitStage(finalStage) stage划分算法重点!递归寻找父Stage!
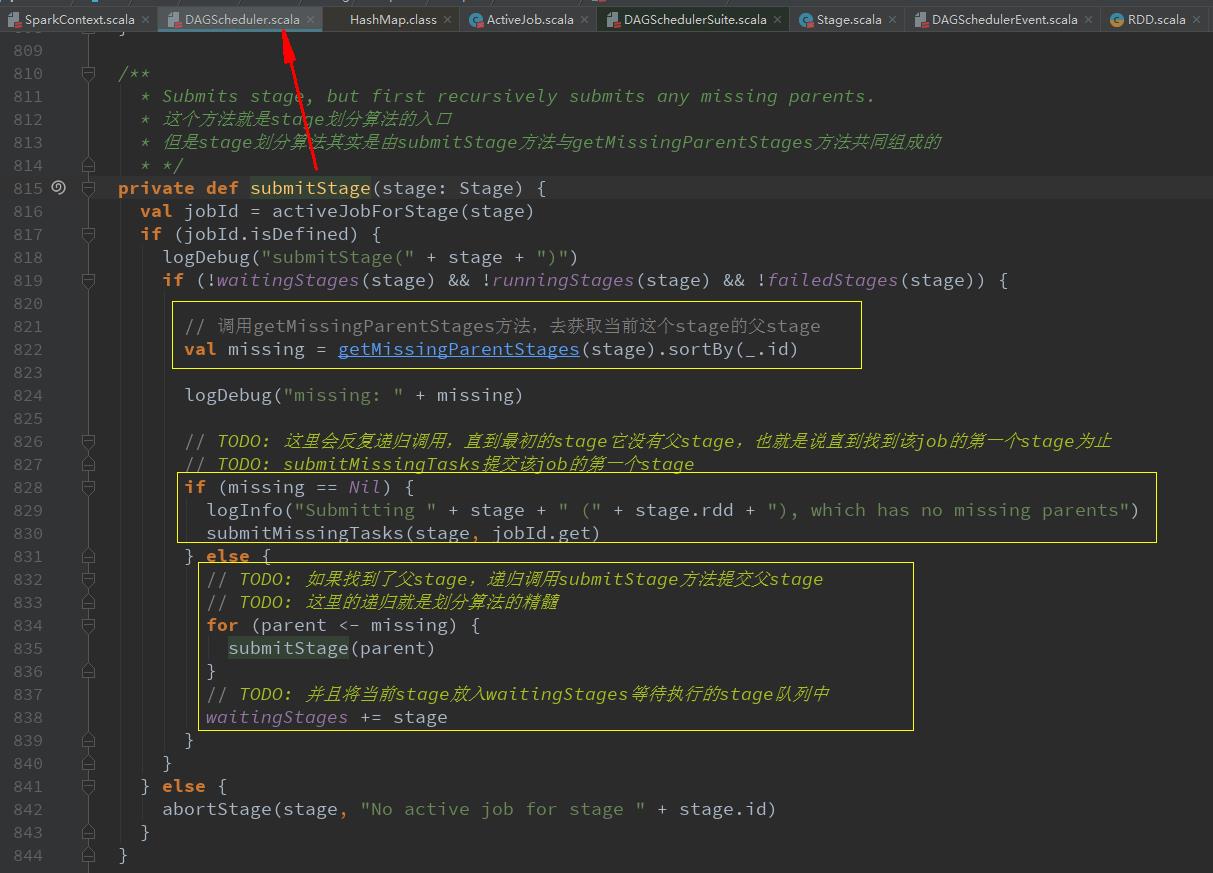
val missing = getMissingParentStages(stage).sortBy(_.id)获取当前stage的父stage
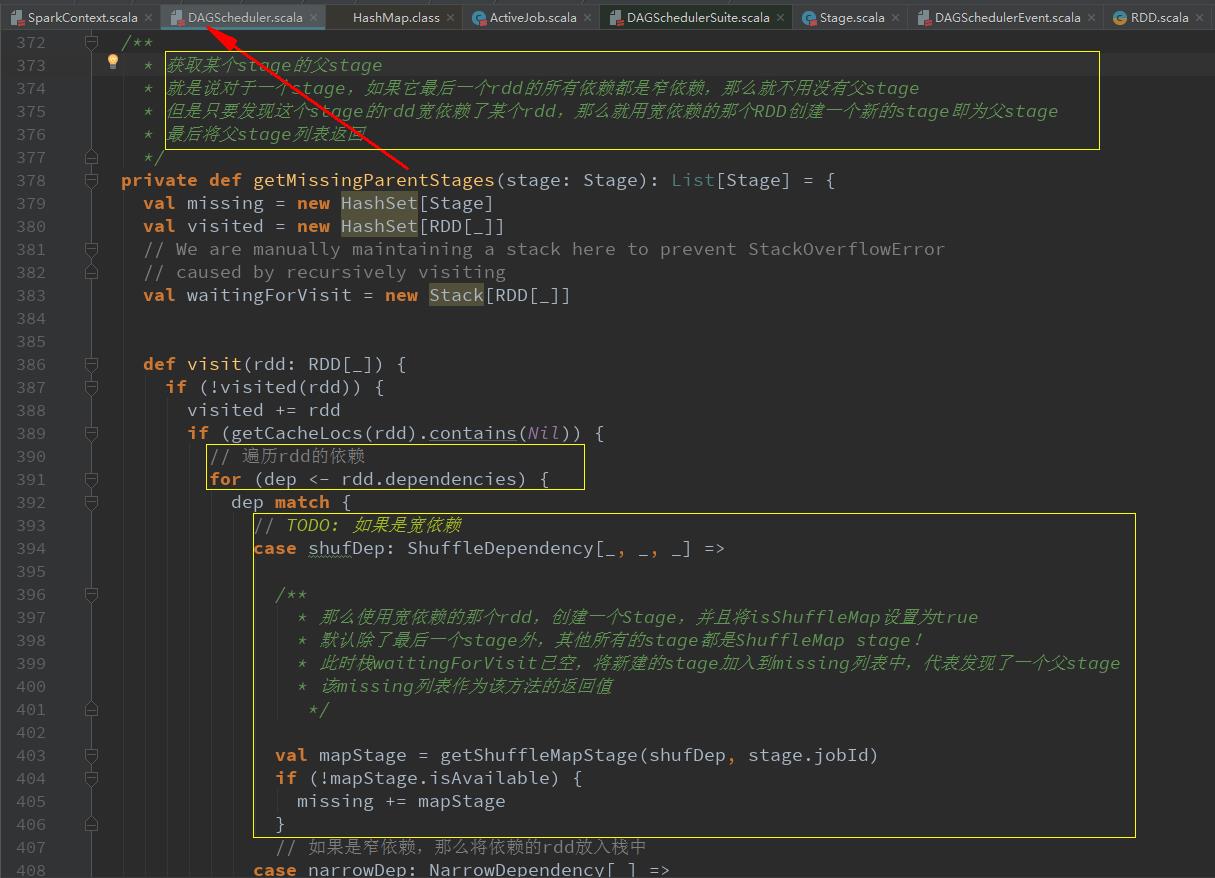
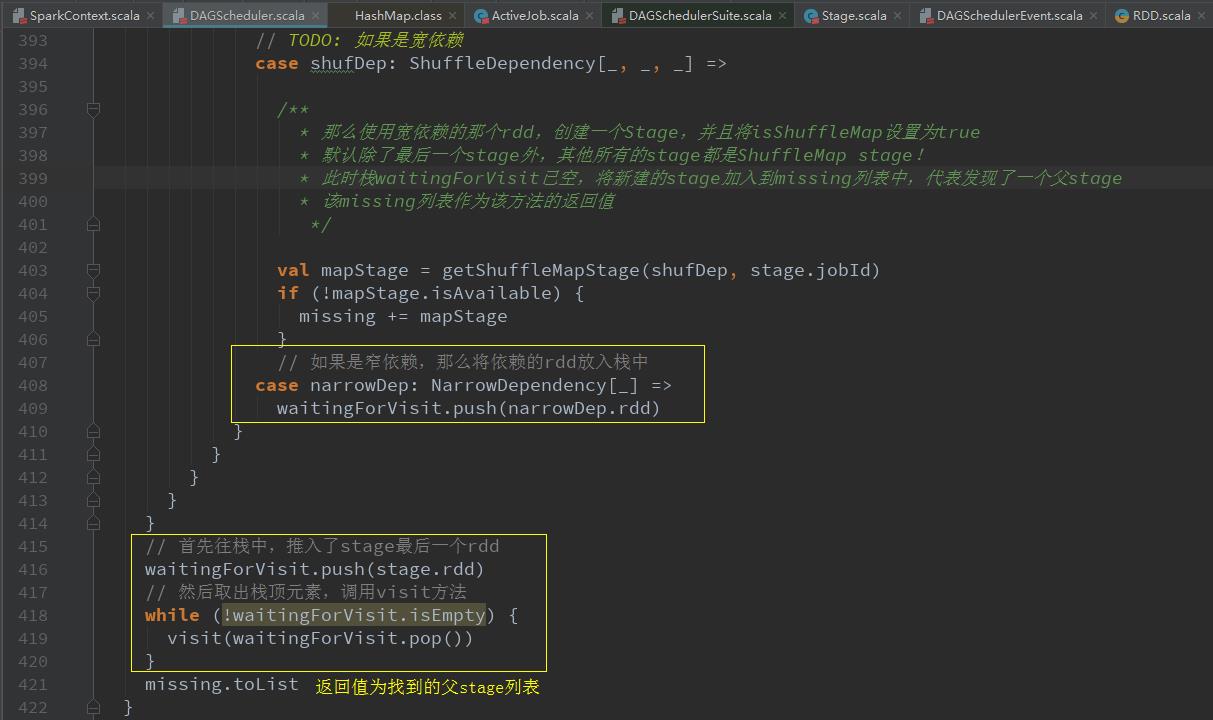
submitMissingTasks(stage, jobId.get)提交某一个stage
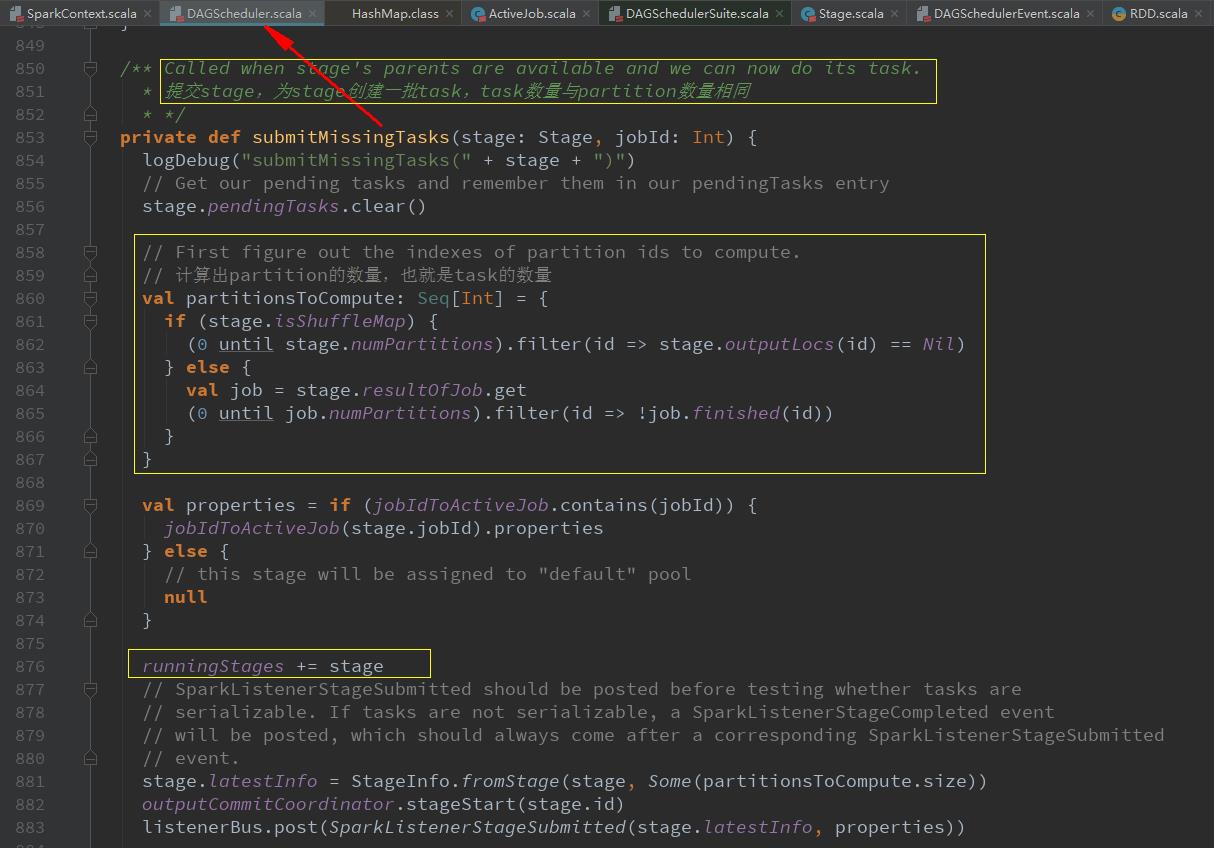
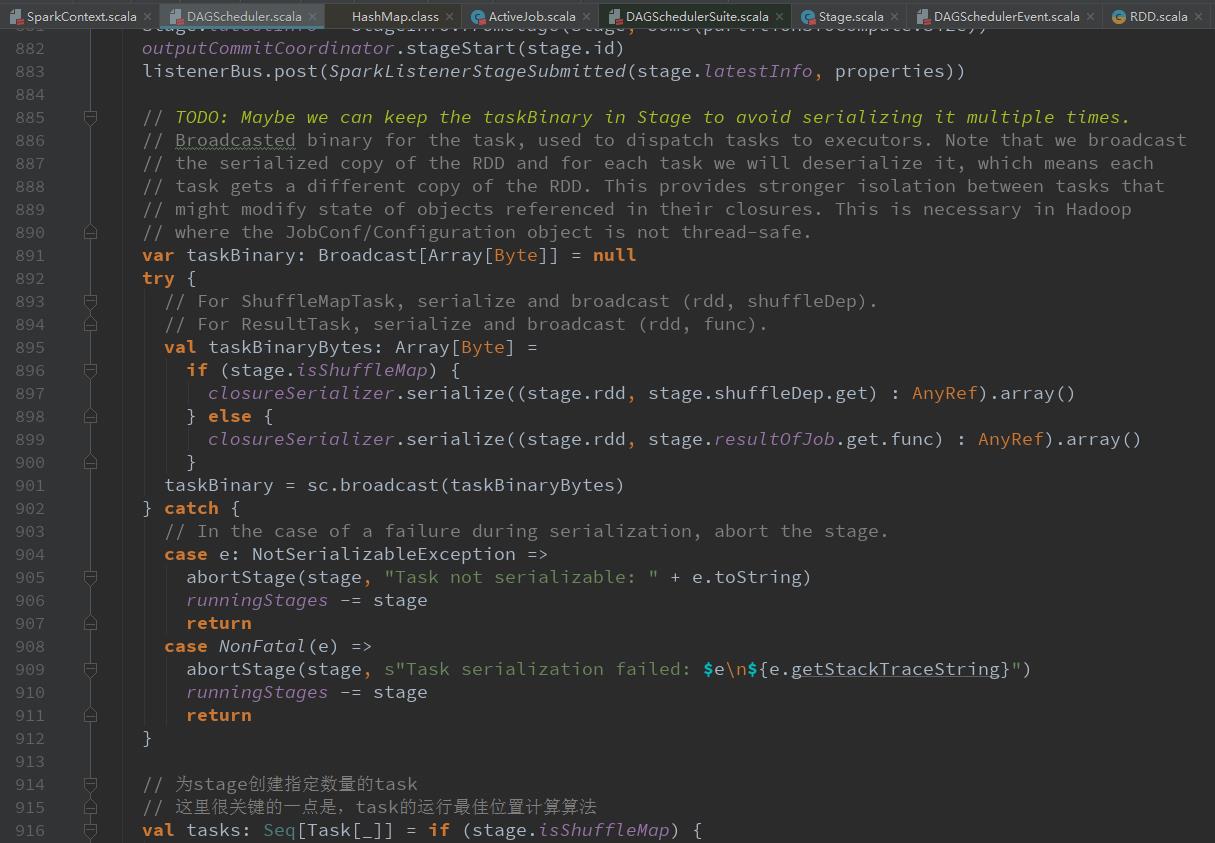
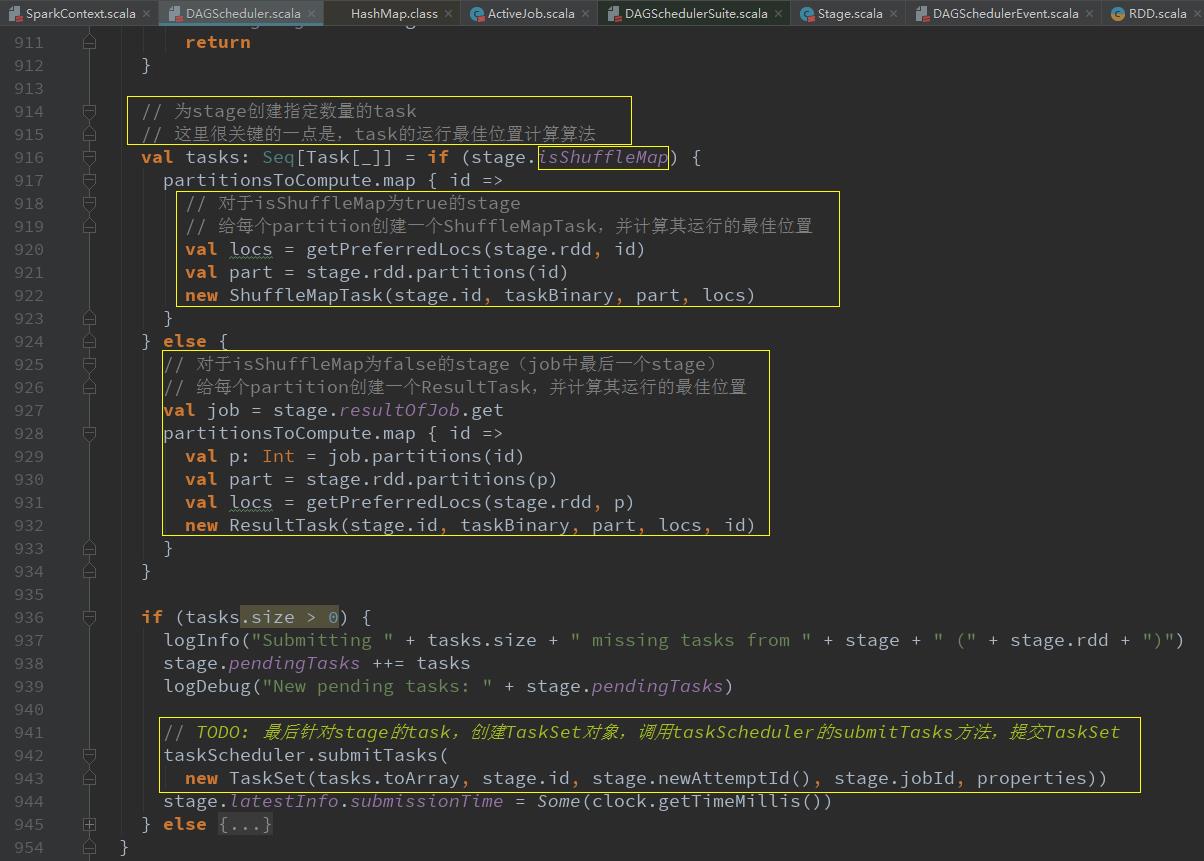
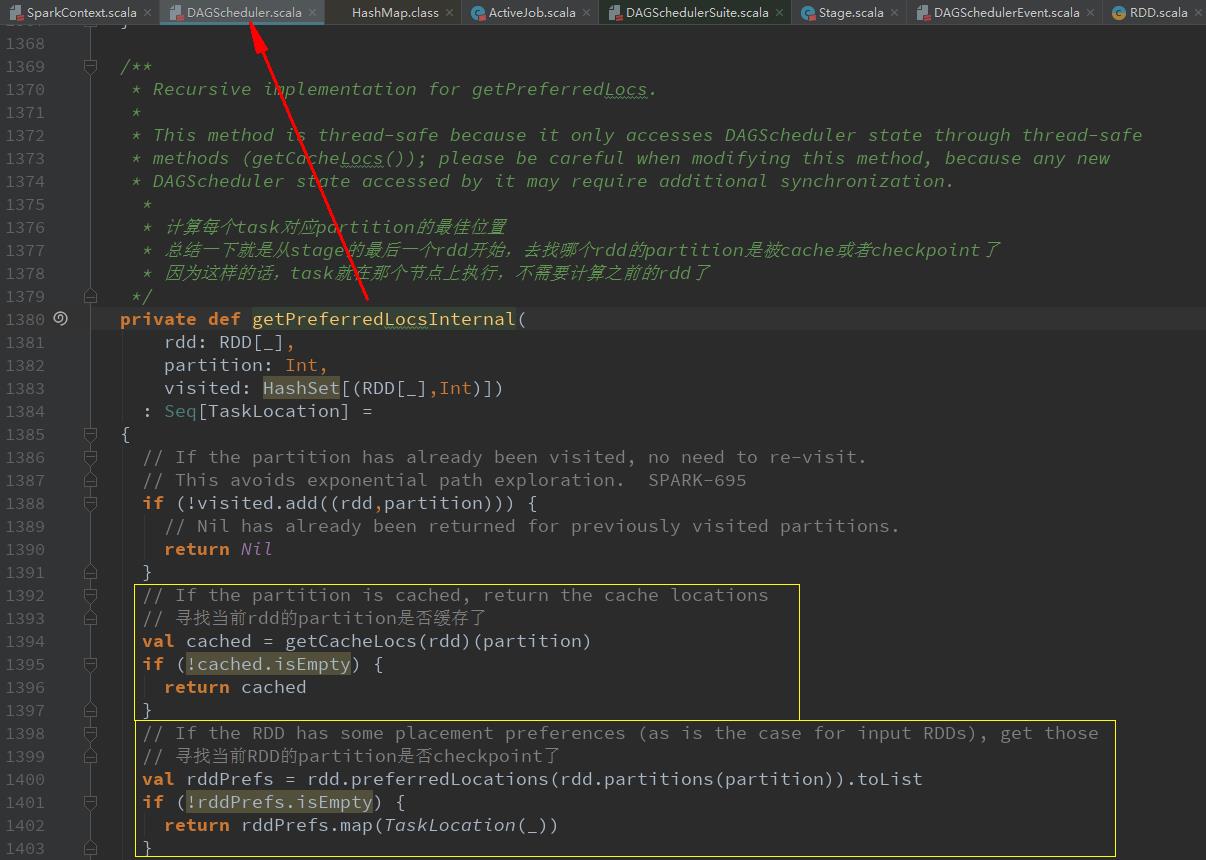
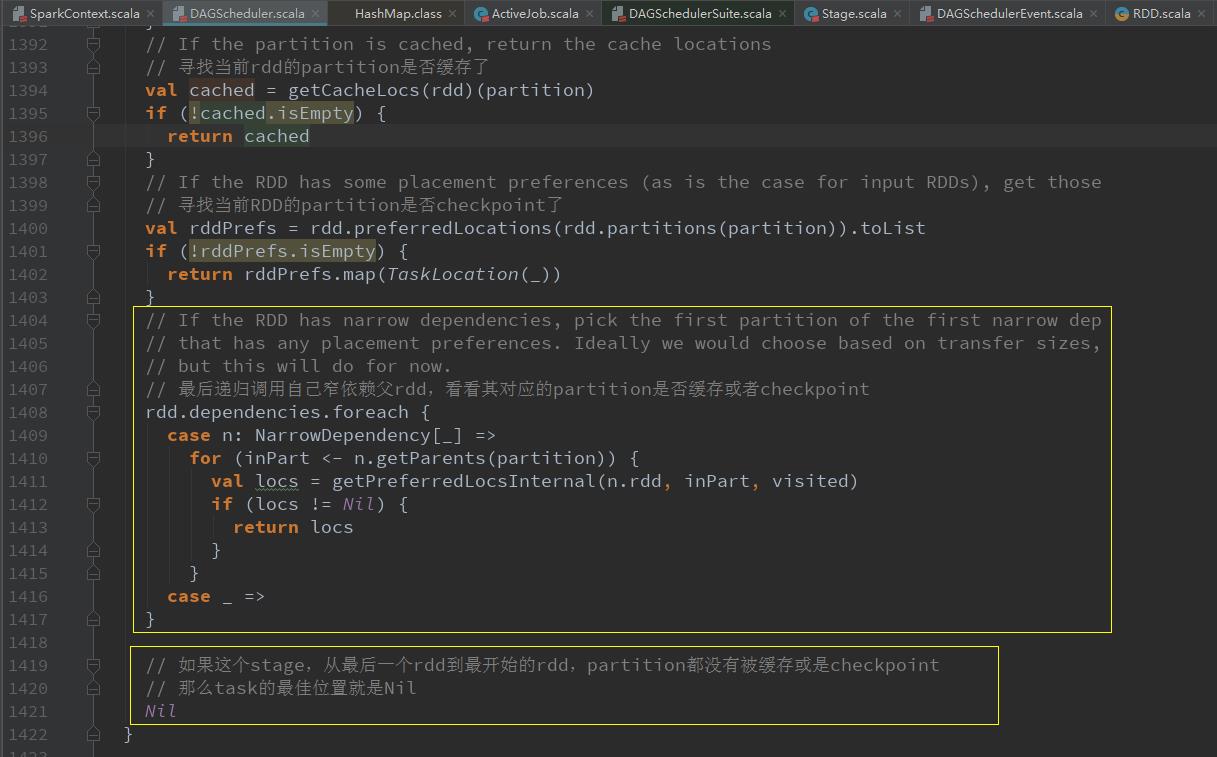
val locs = getPreferredLocs(stage.rdd, id)给每个partition创建一个ShuffleMapTask或ResultTask(最后一个stage),并计算其运行的最佳位置
stage划分算法总结
1. 从finalStage倒推
2. 通过宽依赖,来进行新stage的划分
3. 使用递归,优先提交父stage
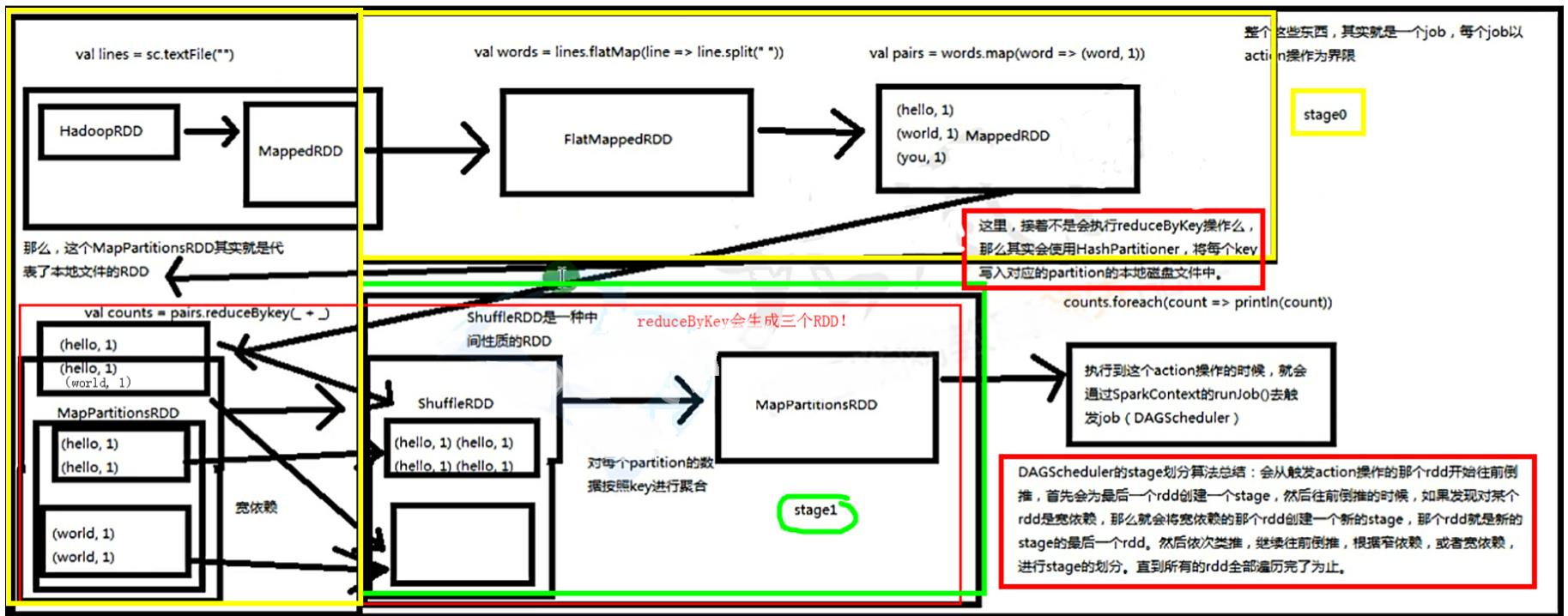
重要知识点
对于每一种有shuffle的操作,例如:groupByKey、reduceByKey、countByKey等,底层都对应了三个RDD:
- MapPartitionsRDD:对应父stage的最后一个RDD
- ShuffleRDD:对应子stage的第一个RDD
- MapPartitionsRDD:对应子stage的第二个RDD
以上是关于Spark源码剖析:stage划分原理与源码剖析的主要内容,如果未能解决你的问题,请参考以下文章