在idea上运行spark的wordcount
Posted zbf-1998
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在idea上运行spark的wordcount相关的知识,希望对你有一定的参考价值。
1.环境hadoop-2.6.0 spak2.1.1 scala-sdk-2.11.12
2.maven项目创建
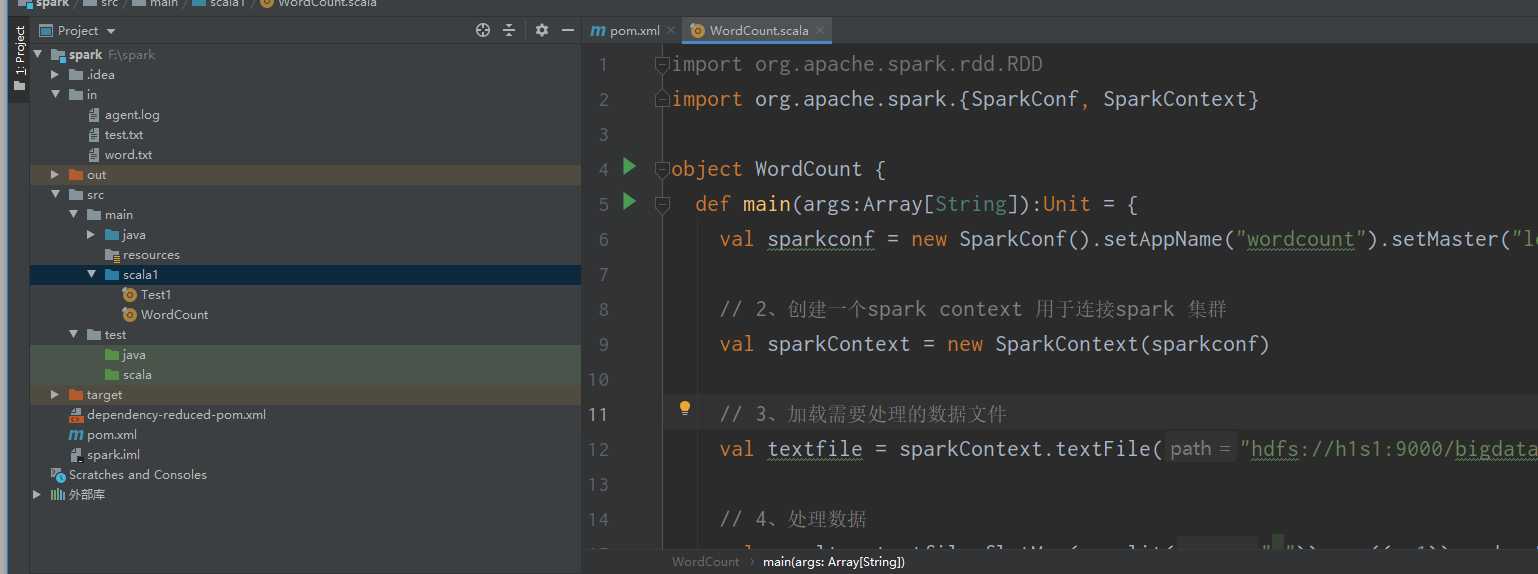
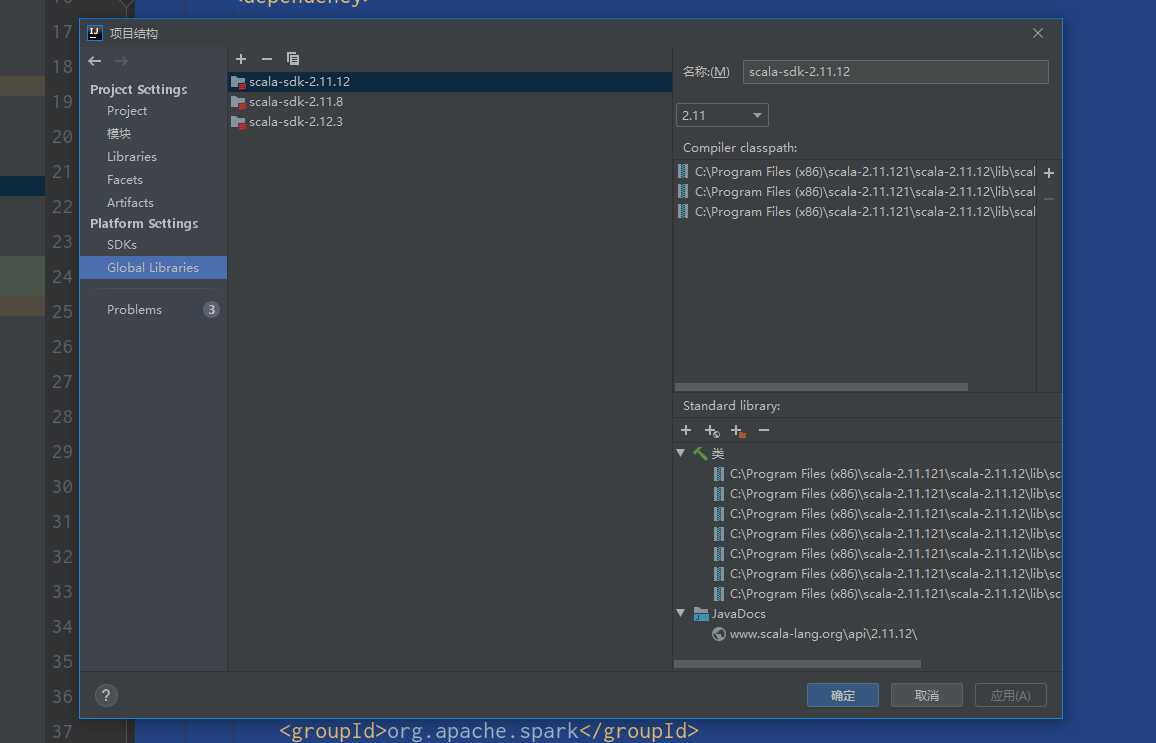
3.pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>spark</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.1.1</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build>
</project>
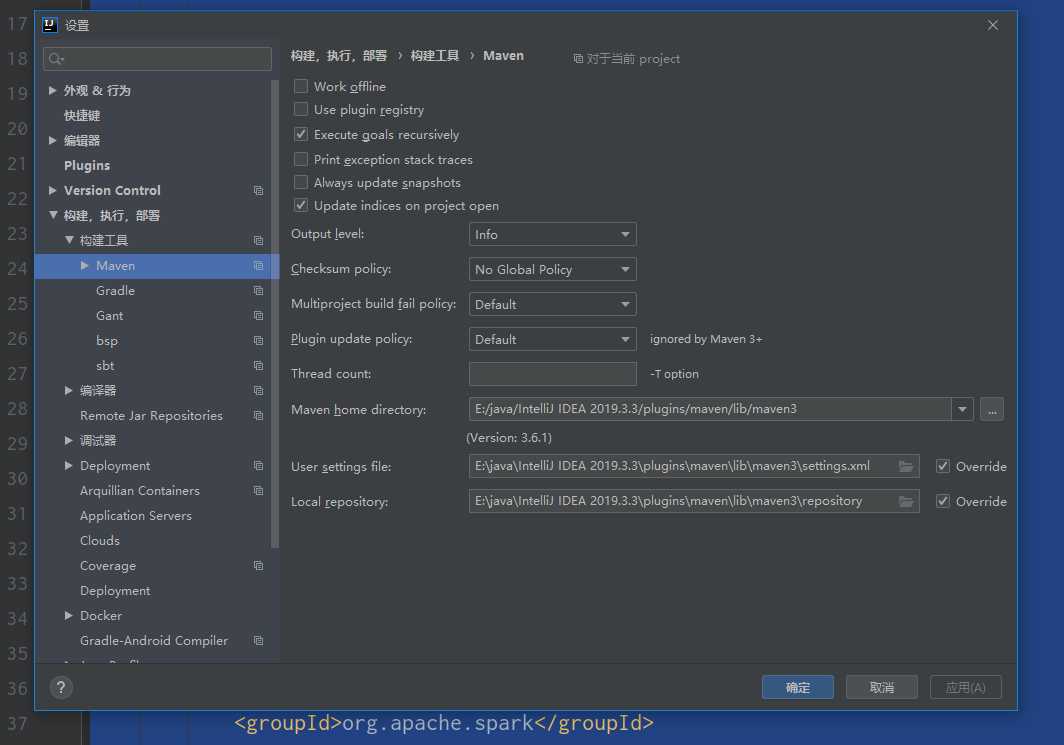
4.阿里云settings配置 (本地仓库要与settings和reposirty路径要如下)
<settings xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 https://maven.apache.org/xsd/settings-1.0.0.xsd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/SETTINGS/1.0.0"> <mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror> <mirror> <id>mirrorId</id> <mirrorOf>central</mirrorOf> <name>Human Readable Name </name> <url>http://repo1.maven.org/maven2/</url> </mirror>
<mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://central.maven.org/maven2</url> <mirrorOf>central</mirrorOf> </mirror>
<mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/repositories/central/</url> <mirrorOf>central</mirrorOf> </mirror>
<mirror> <id>junit</id> <name>junit Address/</name> <url>http://jcenter.bintray.com/</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors> </settings>
5.代码
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args:Array[String]):Unit = {
val sparkconf = new SparkConf().setAppName("wordcount").setMaster("local[*]")
// 2、创建一个spark context 用于连接spark 集群
val sparkContext = new SparkContext(sparkconf)
// 3、加载需要处理的数据文件
val textfile = sparkContext.textFile("hdfs://h1s1:9000/bigdata/5.txt")
// 4、处理数据
val result = textfile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
// 5、输出数据文件的结果
result.saveAsTextFile("hdfs://h1s1:9000/bigdata/out321")
//result.collect().foreach(println _)
// 6、关闭spark集群的连接
sparkContext.stop()
}
}
6报错误Permission denied: user=administrator, access=WRITE, inode="/":root:supergroup:drwxr-xr-x

更改你hdfs上文件权限
![]()
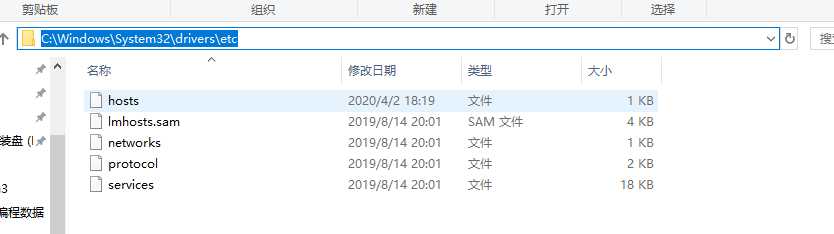
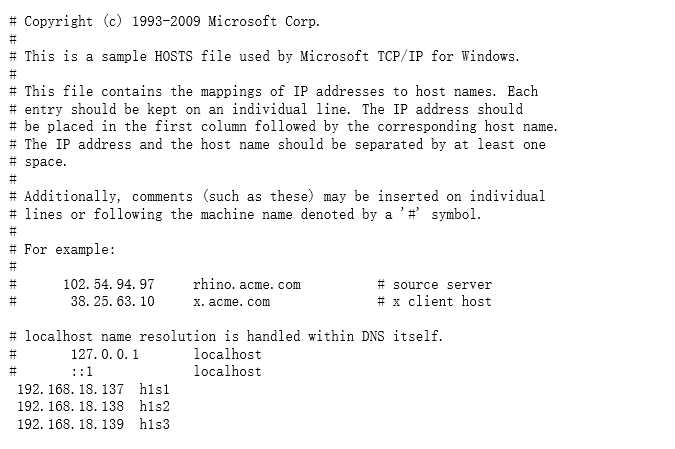
7.报错:HDFS的java操作异常Exception in thread "main" java.lang.IllegalArgumentException :找不到hdfs上主机
修改C:WindowsSystem32driversetchosts 加入IP地址和主机名
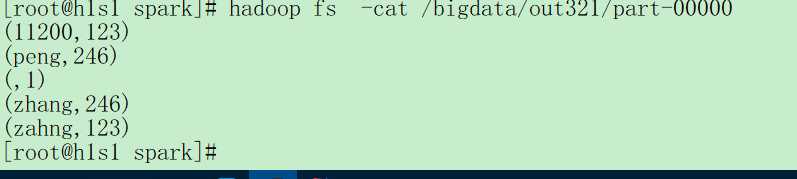
8.检查
以上是关于在idea上运行spark的wordcount的主要内容,如果未能解决你的问题,请参考以下文章