Spark通过IDEA远程提交WordCount案例
Posted W杀猪了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark通过IDEA远程提交WordCount案例相关的知识,希望对你有一定的参考价值。
1.IDEA创建新项目
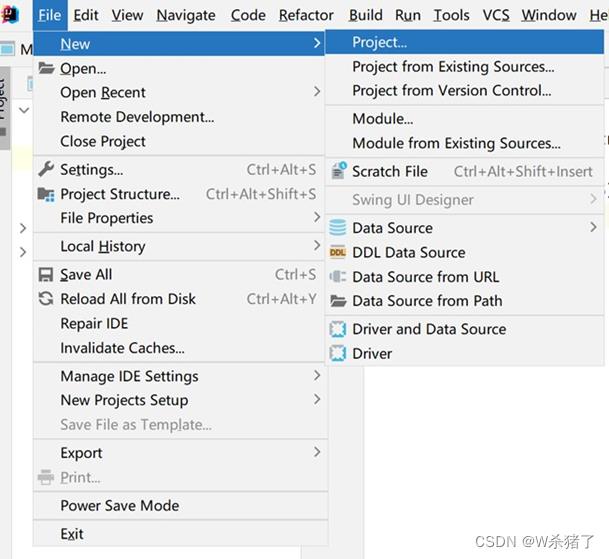
2.选择Maven
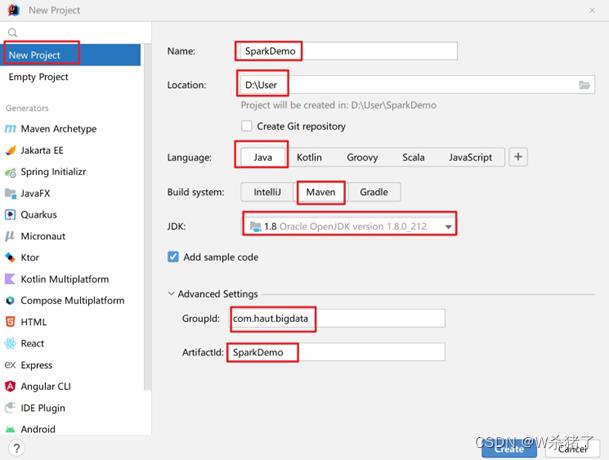
3.创建出新项目
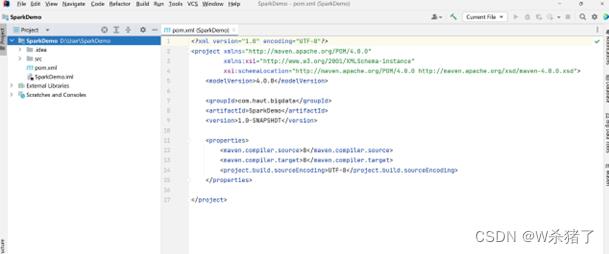
4.打开Project Structure
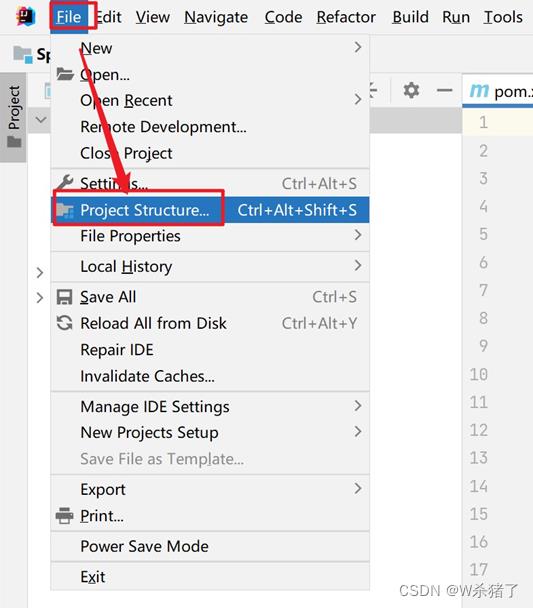
5.添加scala2.11.12
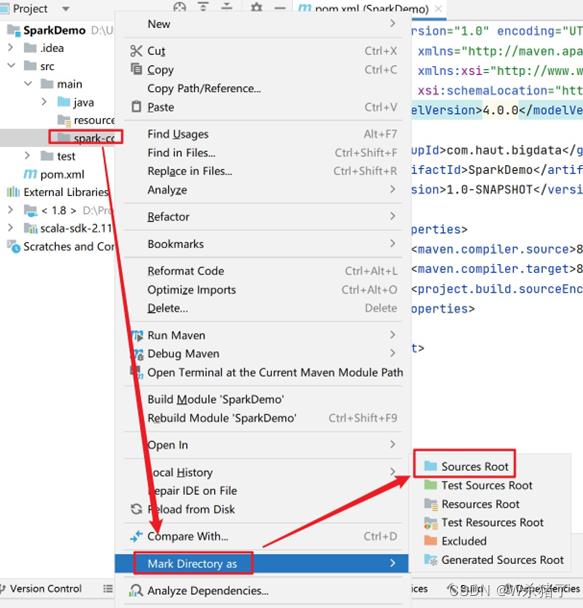
6.新建spark-core目录并设置Sources Root
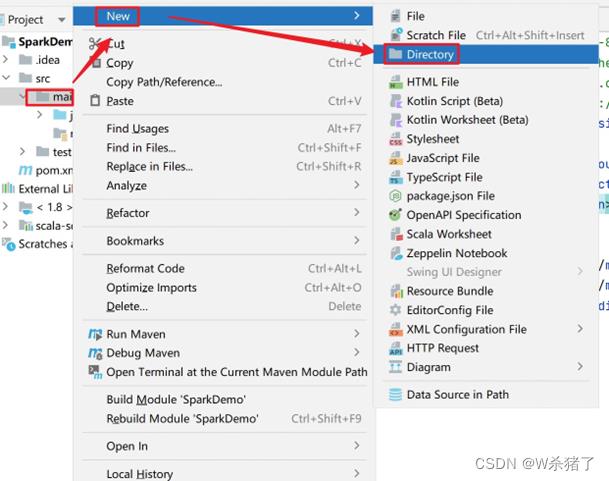
7.解压spark到本地,导入spark的jar包
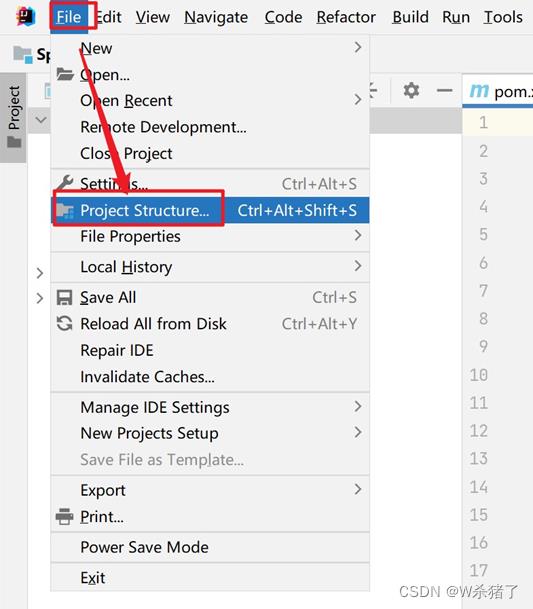
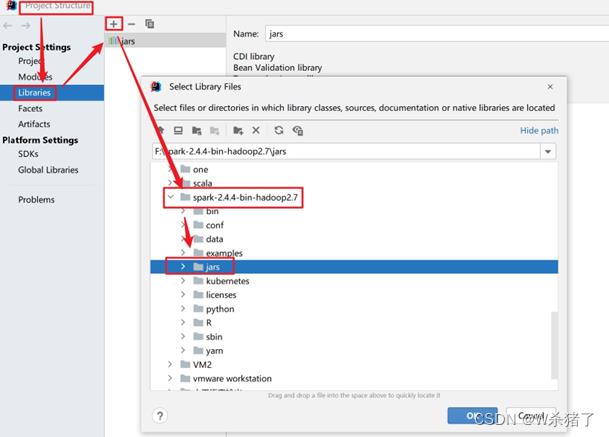
8.开启集群及Spark
start-all.sh启动集群,进入到Spark的sbin目录下,通过./start-master.sh及./start-slaves.sh启动Spark,输入jps查看是否正常
9.编写如下代码:
import org.apache.spark.SparkConf, SparkContext object test def main(args: Array[String]): Unit = //Application//Spark 框架 //TODO 建立和 Spark 框架的连接 //JDBC:Connction val Conf = new SparkConf().setAppName("test") .setMaster("spark://master:7077") .setIfMissing("spark.driver.host", "172.32.181.163")//IP为本机电脑IP val sc = new SparkContext(Conf) val rdd = sc.textFile("hdfs://master:9000/hadooptest/input/yarn-site.xml") println("行数:" + rdd.count()) //关闭连接 sc.stop()
10.运行程序即可!
以上就是本次的全部分享了!


Spark学习笔记——在远程机器中运行WordCount
1.通过realy机器登录relay-shell
2.登录了跳板机之后,连接可以用的机器
XXXX.bj
3.在本地的idea生成好程序的jar包(word-count_2.11-1.0.jar)之后,把jar包和需要put到远程机器的hdfs文件系统中的文件通过scp命令从开发机传到远程的机器中
scp 开发机用户名@开发机ip地址:/home/XXXXX/文件 . #最后一个.表示cd的根目录下
object WordCount {
def main(args: Array[String]) {
// val inputFile = "file:///home/mi/coding/coding/Scala/word-count/input/README.txt"
// val inputFile = "file://README.txt"
val inputFile = "/user/XXXX/lintong/README.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("yarn-client")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
// wordCount.foreach(println)
// wordCount.saveAsTextFile("file:///home/mi/coding/coding/Scala/word-count/output/READMEOUT.txt")
wordCount.saveAsTextFile("/user/XXXX/lintong/READMEOUT.txt")
}
}
4.通过put命令将远程机器中的txt文件,传到远程机器的hdfs文件系统
hadoop fs -put /homeXXX/文件名 ./lintong #.注意.的目录地址是用户的根目录
5.这时可以使用下面命令查看文件
hadoop fs -ls ./lintong
6.接下来写shell脚本,来运行spark-submit命令,shell脚本的目录和jar包的目录保持一致
spark-submit --cluster XXXXX --master yarn-client --num-executors 3 --class "包名.类名" --queue XXXXX word-count_2.11-1.0.jar
7.最后在hdfs文件系统中查看生成的文件,注意
wordCount.saveAsTextFile("/user/XXXX/lintong/READMEOUT.txt")
会是一个READMEOUT.txt目录,这个目录下面有part文件
hadoop fs -ls ./lintong/READMEOUT.txt
输出
lintong/READMEOUT.txt/_SUCCESS lintong/READMEOUT.txt/part-00000
以上是关于Spark通过IDEA远程提交WordCount案例的主要内容,如果未能解决你的问题,请参考以下文章