从谷歌 GFS 架构设计聊开去
Posted socoool
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从谷歌 GFS 架构设计聊开去相关的知识,希望对你有一定的参考价值。
伟人说:“人多力量大。”
尼古拉斯赵四说:“没有什么事,是一顿饭解决不了的!!!如果有,那就两顿。”
研发说:“需求太多,人手不够。”
专家说:“人手不够,那就协调资源,攒人头。”
释义:一人拾柴火不旺,众人拾柴火焰高。一人难挑千斤担,众人能移万座山。
运维说:“一台机器不够;一个服务扛不住压力。”
专家说:“一台机器不够,那就多申请几台;一个服务扛不住压力,那就多部署几个。”
释义:一箭易断,十箭难折。一根线容易断,万根线能拉船。
从事互联网开发时间久了,参加大大小小的会议,时不时总会讨论或争执类似“人手不够、机器不够、服务扛不住”等一类的资源问题,但是到最后解决方案,貌似都是进行资源协调。如果人手不够,就协调资源攒人头;如果机器不够,就协调资源加几台;如果一个服务扛不住压力,那就协调资源多部署几个。
所有的一切都离不开:攒、加 ... ... ,总之就是考虑如何从 1 到 N 。
拜读 GFS 的论文,熟读 N 篇系列文章,静下来想想 GFS 架构设计,多少都透了着一丝“众人拾柴火焰高、人多就是力量大”的想法,接下来就一起对 GFS 认识认识。
认识
到底是个啥?GFS 是一个把大量廉价的普通机器,聚在一起,充分让每台廉价的机器发挥光和热,具有高可用、高性能、高可靠、可扩展的分布式文件系统。
解剖
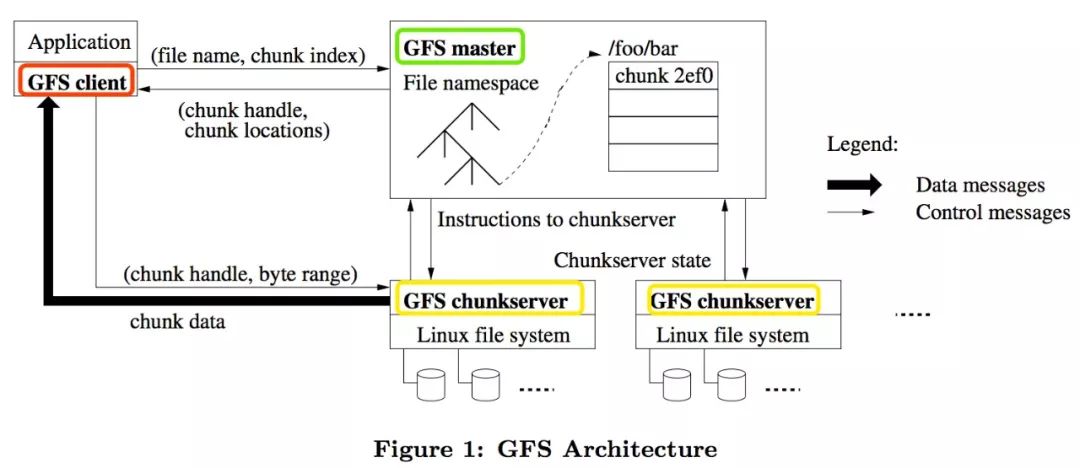
善于发现美。如上图所示,GFS 架构的参与角色,主要分为 GFS master(主服务器)、GFS chunkserver(块存储服务器)、GFS client(客户端)。
我们姑且认为 GFS master 是古代的皇上,统筹全局,运筹帷幄。主要负责掌控管理所有的文件系统的元数据,包括文件和块的命名空间,从文件到块的映射,每个块所在的节点位置(说白了,要维护哪个文件存在哪些文件服务器上的元数据信息);并且定期通过心跳机制与每一个 GFS chunkserver 通信,向其发送指令并收集其状态。
我们姑且认为 GFS chunkserver 是宰相,因为宰相肚子里面能撑船,主要提供 chunks 数据块的存储服务,以文件的形式存储于 chunkserver 上,能够海纳百川,有容乃大。
我们姑且认为 GFS client 是使者,对外提供一套类似传统文件系统的 API 接口,对内主要与皇帝通信来获取元数据;然后直接和宰相交互来进行所有的数据操作。
好奇
背后如何运转?懵懂 GFS 架构设计的参与角色主要有皇上、诸多宰相、诸多使者构成,但是他们之间是如何协作运转的呢?
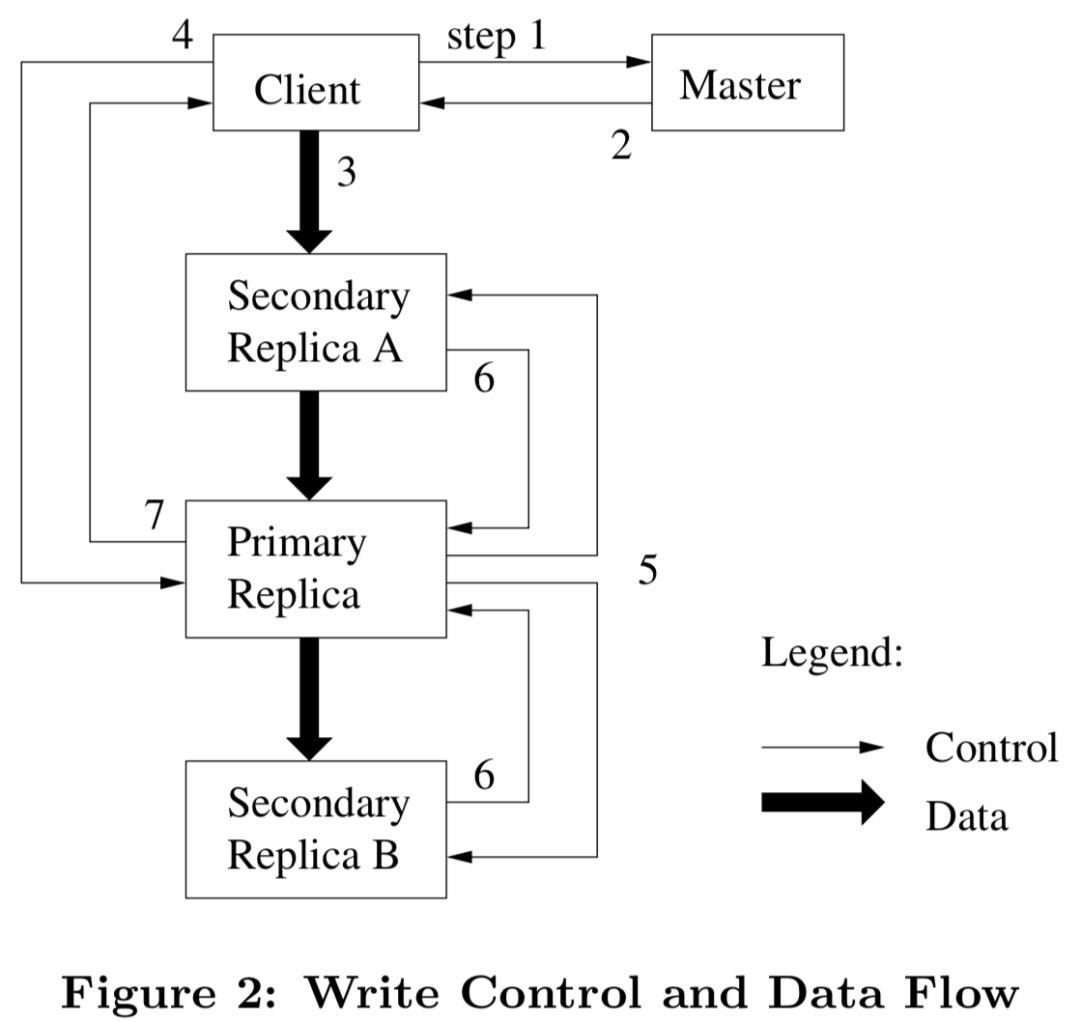
我要写入一个文件,GFS 架构背后流转是咋回事?如上图所示,主要分为 7 大步骤进行。
第一步:GFS client 向 GFS master 查询待写入的 chunk 的 GFS chunkserver(宰相)信息;
释义:使者请求皇上要发起写数据操作,皇上会告诉使者找哪几个宰相去办理。
第二步:GFS master 返回 GFS chunkserver 列表,其中返回的 chunkserver 分为 1 主 2 从;
释义:皇上告诉使者去找 Primary 主宰相 + AB 两个从宰相(主宰相有话语权,从宰相听从主宰相的命令)。
第三步:GFS client 将数据发送至 GFS chunkserver,chunkserver 会缓存这些数据,此时数据并不落盘;
释义:使者把数据发送给所有宰相,宰相先把数据缓存一下,并不塞到肚子里。
第四步:GFS client 向主 GFS chunkserver 发起同步写入请求;
释义:使者告诉 Primary 主宰相可以把数据吞到肚子里了;
第五步:主 GFS chunkserver 将数据写入本地磁盘并通知其他从 GFS chunkserver 将数据数据落盘;
释义:Primary 主宰相开始把数据吞到肚子里,并通知 AB 两个从宰相将数据吞到肚子里;
第六步:主 GFS chunkserver 等待所有从 GFS chunkserver 的数据处理响应;
释义:Primary 主宰相等待 AB 两个从宰相数据处理响应结果;
第七步:主 GFS chunkserver 给 GFS 客户端返回数据写入成功响应。
释义:Primary 主宰相告诉使者本次的数据写入成功了。
结论:想要谁存找皇上;数据存储找宰相;1主两从存三份。
我要读取一个文件,GFS 架构背后又是怎么流转的呢?懵懂了写文件的运转流程,那读文件的流转就相对简单了不少。
第一步:GFS client 从本地缓存,看文件存储在哪些 chunk-server 上;
使者从自己缓存中找找文件是由哪些宰相负责;
第二步:如果 GFS client 本地缓存没有找到,就向 GFS master 查询文件所在位置;
使者从自己缓存中找不到文件是由哪些宰相负责,就请求皇上查询有哪些宰相负责存储;
第三步:GFS master 返回 GFS chunkserver 列表给 GFS client;
皇上返回存储文件的宰相列表给使者;
第四步:从返回的 chunk-server 里读文件,返回给 GFS client。
使者找离自己最近的宰相发出读请求,然后宰相内容返回给使者。
结论:要最快查缓存;缓存没有找皇上;数据就找近宰相。
反思
架构这么设计为什么?是不是在耍流氓!
GFS master 为什么是单点?简单就是美!
GFS chunk 块大小为什么选择 64M 呢?
GFS 的高可用、高性能、高可靠是怎么保证的?
最后,再多说两句。谷哥“三驾马车”的出现,才真正把我们带入了大数据时代,而 GFS 作为其中一架宝车,能够把大量廉价的普通机器,聚在一起,充分让每台廉价的机器发挥光和热,不但降低了运营成本,而且经受了业界实际生产的考验,本次只是 GFS 管中窥豹,只见得其中一斑,GFS 背后还有很多值得我们学习的地方,慢慢去体会。
好了,如果感觉这篇文章有点意思,请多多分享转发吧。
以上是关于从谷歌 GFS 架构设计聊开去的主要内容,如果未能解决你的问题,请参考以下文章