1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| const puppeteer = require("puppeteer");
const fs = require("fs");
const path = require("path");
const urlList = [
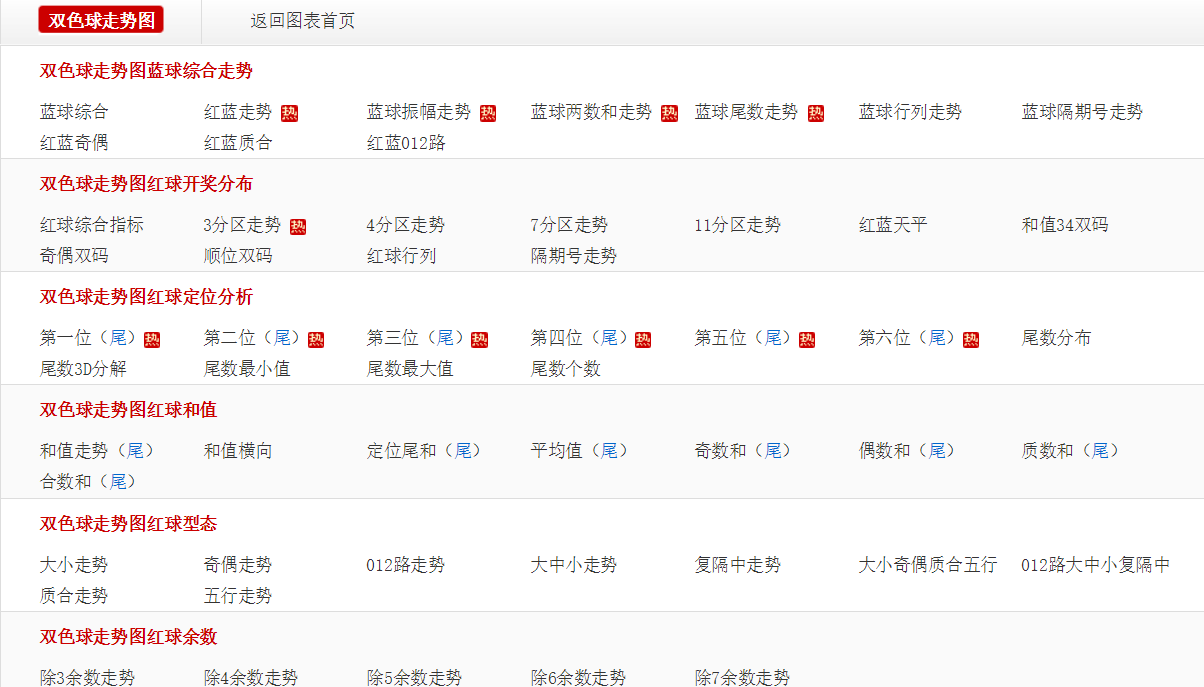
{ name: "双色球", url: "http://cjzst.36886.net/cjwssq/" },
{ name: "七乐彩", url: "http://cjzst.36886.net/cjwqlc/" },
{ name: "福彩3D", url: "http://cjzst.36886.net/cjw3d/" },
{ name: "大乐透", url: "http://cjzst.36886.net/cjwdlt/" },
{ name: "七星彩", url: "http://cjzst.36886.net/cjw7xc/" },
{ name: "排列三", url: "http 大专栏 用puppeteer爬取网页数据初体验://cjzst.36886.net/cjwpl3/" }
];
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
async function (url, fileName) {
await page.goto(url);
let result = await page.evaluate(() => {
const items = [...document.querySelectorAll(".zst_list_con>ul")];
return items.map(item => {
let titleLink = item.querySelector(".zst_list_name>a");
let contentLink = [...item.querySelectorAll("li")];
let list = contentLink.map(item => {
let a_list = [...item.querySelectorAll("a")];
return a_list.map(a => {
return { title: a.innerText, href: a.href };
});
});
return { title: titleLink.innerText, href: titleLink.href, list: list };
});
});
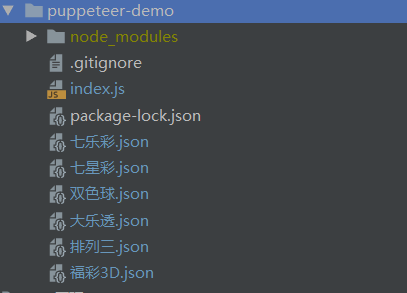
fs.writeFile(`./${fileName}.json`, JSON.stringify(result), "utf8", function(
error
) {
if (error) {
console.log(error);
return false;
}
console.log(fileName + "数据写入成功!");
});
}
async function openUrlList() {
for (let i = 0; i < urlList.length; i++) {
await getLinkList(urlList[i].url, urlList[i].name);
}
}
await openUrlList();
await browser.close();
});
|