如何实现报表数据的动态层次钻取
Posted shiguangshiyi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何实现报表数据的动态层次钻取相关的知识,希望对你有一定的参考价值。
上一篇《如何实现报表数据的动态层次钻取(一)》介绍了利用复杂 sql 实现动态层次结构的方法,但该方法依赖 Oracle 的递归语法,在其他类型的数据库中难以实现。要想通用地实现此类报表,可以使用下面介绍的“集算脚本 + 本地文件”的方法。
《各级部门 KPI 报表》的格式和具体要求参见上一篇文章。有所不同的是,报表数据源从数据库表变为本地文件:tree.b(树形结构维表)和 kpi.b(指标事实表),数据示例如下图:
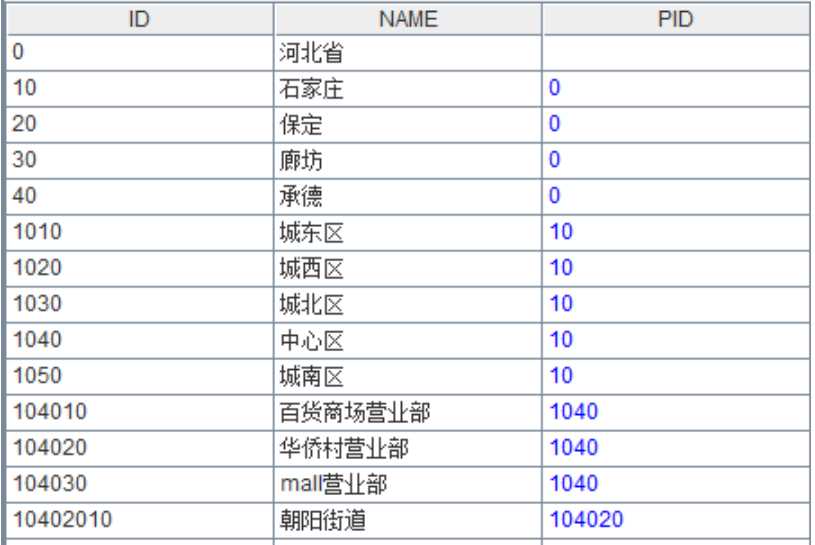
Tree 文件数据
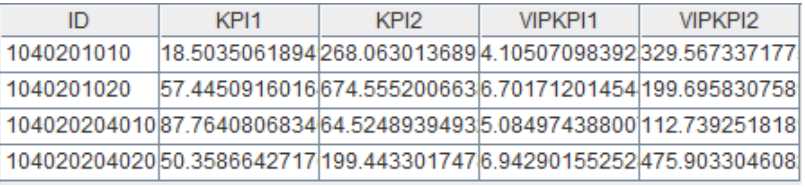
Kpi 文件数据
说明:Tree 的叶子节点,通过 id 字段与 kpi 表关联。KPI 文件每个 ID 每天都会新增 kpi 记录,总数据量较大。
具体实现步骤如下:
第一步 编写集算脚本 tree.dfx,完成源数据计算,输入参数为当前节点号 id。
集算脚本如下:

代码说明:
A1:新建一个序列,内容是各层节点的 title:“省、地市、区县、营业部、架构 4、架构 5、架构 6. . . 架构 13”。
B1:读入 tree.b 的数据。
C1:新建一个文件游标,连接 kpi.b 文件。使用游标分段读取数据,适用于 kpi.b 较大,无法一次装入内存的情况。
A2:将 B1 的 PID 字段切换成 B1 自己的引用,条件是 PID=ID。
B2:在 B1 中取出指定 id 对应的记录。
C2:使用 prior 函数,查找 C2 自己和所有祖先节点,顺序反转。
A3:用 C2 生成新序表,字段是 ID、NAME 和 A1 中对应的组织结构。
B3:定义变量 xtitle 赋值为指定 id 对应下一层节点的 title。
C3:在 B1 中找出 B2 的直接子节点。
A4:如果 C3 没有成员,说明当前节点是叶子,用 B1 的结构新建一个序表(只有一条空记录)。否则,直接将 C3 赋值给 A4。
B4:用 B1 生成新序表,字段是 ID、GID(分组 id)。GID 是用 prior 函数找到当前每条记录到祖先 B2 的路径。之后去掉 GID 为空的记录,也就是非 B2 子孙的记录。
C4:循环将 B4 的 GID 赋值为所有祖先中的倒数第二个,也就是当前 id 的子节点。
A5:将 C1 的 ID 字段切换成 C4 对应记录,去掉找不到 ID 对应值的记录,也就是非 B2 子孙的叶子。
B5:对 A5 按照 ID.GID 分组,汇总 kpi。
C5:将 B5 与 A4 对齐。
A6:用 C5 生成新序表。如果 id 是叶子的话,id、name 为空,方便报表隐藏列,避免叶子显示两次。
B6:向报表返回两个结果集。
接下来的第二到四步可以参见《 如何实现报表数据的动态层次钻取(一) 》,这里不再赘述,完成后即可实现相应的效果。
通过上述集算器代码,可以使用的数据源不仅限于本地文件,也可适用于一般数据库,这样就可以在那些不支持递归查询的数据库上通用地实现此类报表了。
以上是关于如何实现报表数据的动态层次钻取的主要内容,如果未能解决你的问题,请参考以下文章