AirFlow介绍
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AirFlow介绍相关的知识,希望对你有一定的参考价值。
AirFlow介绍
一、AirFlow是什么
airflow 是一个编排、调度和监控workflow的平台,由Airbnb开源,现在在Apache Software Foundation 孵化。airflow 将workflow编排为由tasks组成的DAGs(有向无环图),调度器在一组workers上按照指定的依赖关系执行tasks。同时,airflow 提供了丰富的命令行工具和简单易用的用户界面以便用户查看和操作,并且airflow提供了监控和报警系统。
Airflow的调度依赖于crontab命令,与crontab相比airflow可以直观的看到任务执行情况、任务之间的逻辑依赖关系、可以设定任务出错时邮件提醒、可以查看任务执行日志。而crontab命令管理的方式存在以下几方面的弊端:
1、在多任务调度执行的情况下,难以理清任务之间的依赖关系;
2、不便于查看当前执行到哪一个任务;
3、任务执行失败时不便于查看执行日志,也即不方便定位报错的任务和错误原因;
4、不便于查看调度流下每个任务执行的起止消耗时间,这对于优化task作业是非常重要的;
5、不便于记录历史调度任务的执行情况,而这对于优化作业和错误排查是很重要的;
1、优劣势分析
| 未使用airflow | 使用airflow |
|---|---|
| 需要自己添加调度代码、调试复杂、功能单一、缺乏整体调度能力 | 框架调度,简单易用,更稳定,功能全面,可以整体调度 |
| 缺乏图形化能力,给任务的新增、排查等操作带来很多困难。特别是当任务较多,结构复杂的时候 | 内置树状图和流程图,清晰明了的展现任务拓扑结构 |
| 需要自己添加任务实时监测代码 | 任务实时状态返回网页界面,方便管理和查看 |
| 任务的各种操作大多需要编码或命令行完成,不够高效 | 常见操作方式转化为图形化界面,高效清晰 |
| 需要手动分离调度和业务代码 | 调度和业务代码分离,减少耦合性,方便运维和迭代 |
除了以上的优点,工程实践中有一个不足就是分布式部署有点麻烦,容易出错。
二、AirFlow中的作业和任务
1、DAG
概要:DAG(Directed Acyclic Graph)是有向无环图,也称为有向无循环图。在Airflow中,一个DAG定义了一个完整的作业。同一个DAG中的所有Task拥有相同的调度时间。
参数:
- dag_id: 唯一识别DAG,方便日后管理
- default_args: 默认参数,如果当前DAG实例的作业没有配置相应参数,则采用DAG实例的default_args中的相应参数
- schedule_interval: 配置DAG的执行周期,可采用crontab语法
2、Task
概要:Task为DAG中具体的作业任务,依赖于DAG,也就是必须存在于某个DAG中。Task在DAG中可以配置依赖关系(当然也可以配置跨DAG依赖,但是并不推荐。跨DAG依赖会导致DAG图的直观性降低,并给依赖管理带来麻烦)。
参数:
- dag: 传递一个DAG实例,以使当前作业属于相应DAG
- task_id: 给任务一个标识符(名字),方便日后管理
- owner: 任务的拥有者,方便日后管理
- start_date: 任务的开始时间,即任务将在这个时间点之后开始调度
三、AirFlow的调度时间
1、start_date
在配置中,它是作业开始调度时间。而在谈论执行状况时,它是调度开始时间。
2、schedule_interval
调度执行周期。
3、execution_date
执行时间。在Airflow中称为执行时间,但其实它并不是真实的执行时间。
[敲黑板,划重点]
所以,第一次调度时间:在作业中配置的start_date,且满足schedule_interval的时间点。记录的execution_date为作业中配置的start_date的第一个满足schedule_interval的时间。[举个例子]
假设我们配置了一个作业的start_date为2019年6月2日,配置的schedule_interval为 00 12 ,那么第一次执行的时间将是2019年6月3日 12点。因此execution_date并不是如期字面说的表示执行时间,真正的执行时间是execution_date所显示的时间的下一个满足schedule_interval的时间点。
四、AirFlow的核心概念
DAGs: 即有向无环图(Directed Acyclic Graph),将所有需要运行的tasks按照依赖关系组织起来,描述的是所有tasks执行的顺序。
Operators: airflow内置了很多operators,如BashOperator 执行一个bash 命令,PythonOperator 调用任意的Python 函数,EmailOperator 用于发送邮件,HTTPOperator 用于发送HTTP请求, SqlOperator 用于执行SQL命令...同时,用户可以自定义Operator,这给用户提供了极大的便利性。可以理解为用户需要的一个操作,是Airflow提供的类
Tasks: Task 是 Operator的一个实例
Task Instance: 由于Task会被重复调度,每次task的运行就是不同的task instance了。Task instance 有自己的状态,包括"running", "success", "failed", "skipped", "up for retry"等。
Task Relationships: DAGs中的不同Tasks之间可以有依赖关系
五、AirFlow 各组件介绍
1、webserver
提供web端服务,以及会定时生成子进程去扫描对应的目录下的dags,并更新数据库
webserver 提供以下功能:
- 中止、恢复、触发任务。
- 监控正在运行的任务,断点续跑任务。
- 执行 ad-hoc 命令或 SQL 语句来查询任务的状态,日志等详细信息。
- 配置连接,包括不限于数据库、ssh 的连接等。
webserver 守护进程使用 gunicorn 服务器(相当于 java 中的 tomcat )处理并发请求,可通过修改{AIRFLOW_HOME}/airflow.cfg文件中 workers 的值来控制处理并发请求的进程数。
例如:workers = 4 #表示开启4个gunicorn worker(进程)处理web请求
2、scheduler
任务调度服务,周期性地轮询任务的调度计划,以确定是否触发任务执行,根据dags生成任务,并提交到消息中间件队列中 (redis或rabbitMq)
3、celery worker
分布在不同的机器上,作为任务真正的的执行节点。通过监听消息中间件: redis或rabbitMq 领取任务
当设置 airflow 的 executors 设置为 CeleryExecutor 时才需要开启 worker 守护进程。推荐你在生产环境使用 CeleryExecutor :executor = CeleryExecutor
4、flower
监控worker进程的存活性,启动或关闭worker进程,查看运行的task
默认的端口为 5555,您可以在浏览器地址栏中输入 “http://hostip:5555” 来访问 flower ,对 celery 消息队列进行监控。
六、AirFlow的 ETL概念(数据仓库技术)
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
Airflow设计时,只是为了很好的处理ETL任务而已,但是其精良的设计,正好可以用来解决任务的各种依赖问题。
1、什么是任务依赖
通常,在一个运维系统,数据分析系统,或测试系统等大型系统中,我们会有各种各样的依赖需求。
- 比如:
- 时间依赖:任务需要等待某一个时间点触发
- 外部系统依赖:任务依赖mysql中的数据,HDFS中的数据等等,这些不同的外部系统需要调用接口去访问
- 机器依赖:任务的执行只能在特定的某一台机器的环境中,可能这台机器内存比较大,也可能只有那台机器上有特殊的库文件
- 任务间依赖:任务A需要在任务B完成后启动,两个任务互相间会产生影响
- 资源依赖:任务消耗资源非常多,使用同一个资源的任务需要被限制,比如跑个数据转换任务要10个G,机器一共就30个G,最多只能跑两个,我希望类似的任务排个队
- 权限依赖:某种任务只能由某个权限的用户启动
也许大家会觉得这些是在任务程序中的逻辑需要处理的部分,但是我认为,这些逻辑可以抽象为任务控制逻辑的部分,和实际任务执行逻辑解耦合。
2、如何理解Crontab
现在让我们来看下最常用的依赖管理系统,Crontab
在各种系统中,总有些定时任务需要处理,每当在这个时候,我们第一个想到的总是crontab。确实,crontab可以很好的处理定时执行任务的需求,但是对于crontab来说,执行任务,只是调用一个程序如此简单,而程序中的各种逻辑都不属于crontab的管辖范围(很好的遵循了KISS)
所以我们可以抽象的认为:
crontab是一种依赖管理系统,而且只管理时间上的依赖。
3、Airflow处理依赖的方式
Airflow的核心概念,是DAG(有向无环图),DAG由一个或多个TASK组成,而这个DAG正是解决了上文所说的任务间依赖。Task A 执行完成后才能执行 Task B,多个Task之间的依赖关系可以很好的用DAG表示完善
Airflow完整的支持crontab表达式,也支持直接使用python的datatime表述时间,还可以用datatime的delta表述时间差。这样可以解决任务的时间依赖问题。
Airflow在CeleryExecuter下可以使用不同的用户启动Worker,不同的Worker监听不同的Queue,这样可以解决用户权限依赖问题。Worker也可以启动在多个不同的机器上,解决机器依赖的问题。
Airflow可以为任意一个Task指定一个抽象的Pool,每个Pool可以指定一个Slot数。每当一个Task启动时,就占用一个Slot,当Slot数占满时,其余的任务就处于等待状态。这样就解决了资源依赖问题。
Airflow中有Hook机制(其实我觉得不应该叫Hook),作用时建立一个与外部数据系统之间的连接,比如Mysql,HDFS,本地文件系统(文件系统也被认为是外部系统)等,通过拓展Hook能够接入任意的外部系统的接口进行连接,这样就解决的外部系统依赖问题。
七、AirFlow 的调度方式
不同Executer 的架构图Airflow执行任务的方式有多种,包括SequentialExecutor、LocalExecutor以及CeleryExecutor,用的较多的是LocalExecutor和CeleryExecutor,这里分别介绍一下三种执行方式的架构:
1、基于CeleryExecutor方式的系统架构
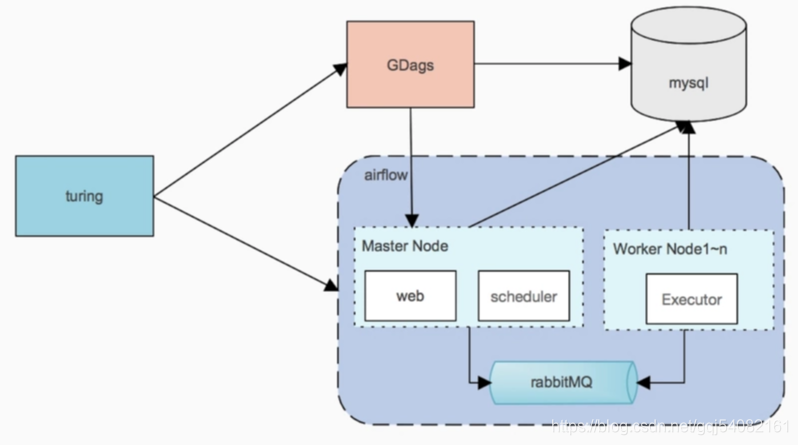
使用celery方式的系统架构图(官方推荐使用这种方式,同时支持mesos方式部署)。turing为外部系统,GDags服务帮助拼接成dag,可以忽略。
1. master节点webui管理dags、日志等信息。scheduler负责调度,只支持单节点,多节点启动scheduler可能会挂掉
2. worker负责执行具体dag中的task。这样不同的task可以在不同的环境中执行。
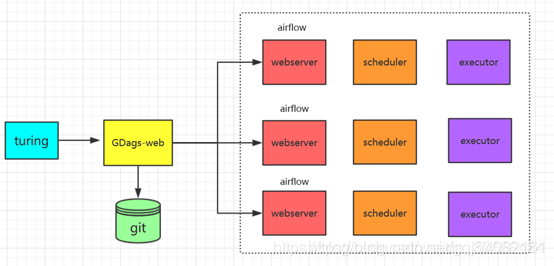
2、基于LocalExecutor方式的系统架构图
另一种启动方式的思考,一个dag分配到1台机器上执行。如果task不复杂同时task环境相同,可以采用这种方式,方便扩容、管理,同时没有master单点问题。
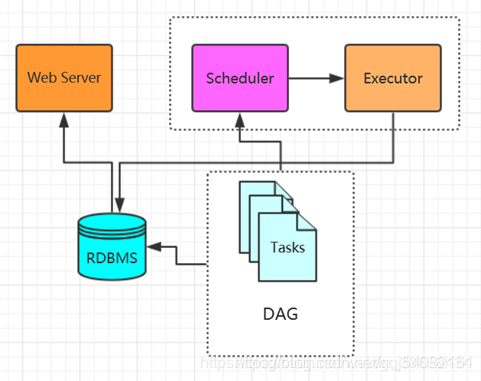
3、基于SequentialExecutor方式的系统架构图
SequentialExecutor表示单进程顺序执行,通常只用于测试。
但是有时候仅仅靠配置作业依赖和调度执行周期并不能满足一些复杂的需求
4、other任务调度方式
1)跳过非最新DAG Run(作业中出现故障,一段时间后恢复)
2)当存在正在执行的DAG Run时,跳过当前DAG Run(作业执行时间过长,长到下一次作业开始)
3)Sensor的替代方案(Airflow中有一类Operator被称为Sensor,Sensor可以感应预先设定的条件是否满足,当满足条件后Sensor作业变为Success使得下游的作业可以执行。弊端是,如果上游作业执行3个小时,那么会占用worker三个小时不释放,资源浪费。)
八、AirFlow的原始架构
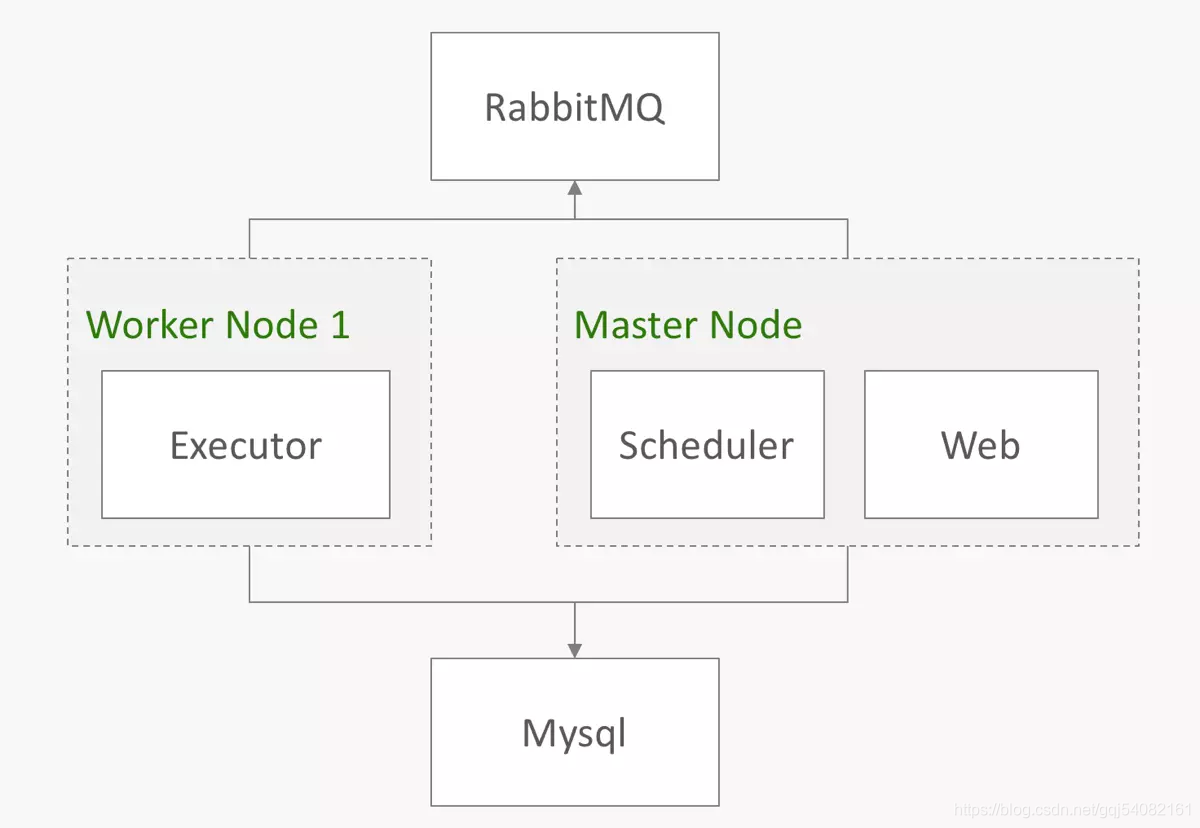
以上是关于AirFlow介绍的主要内容,如果未能解决你的问题,请参考以下文章
大数据调度平台Airflow:Airflow WebUI操作介绍