转载--编写高质量代码:改善Java程序的151个建议(第3章:类对象及方法___建议47~51)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了转载--编写高质量代码:改善Java程序的151个建议(第3章:类对象及方法___建议47~51)相关的知识,希望对你有一定的参考价值。
建议47:在equals中使用getClass进行类型判断
本节我们继续讨论覆写equals的问题,这次我们编写一个员工Employee类继承Person类,这很正常,员工也是人嘛,而且在JavaBean中继承也很多见,代码如下:

1 public class Employee extends Person {
2 private int id;
3
4 public Employee(String _name, int _id) {
5 super(_name);
6 id = _id;
7 }
8
9 public int getId() {
10 return id;
11 }
12
13 public void setId(int id) {
14 this.id = id;
15 }
16
17 @Override
18 public boolean equals(Object obj) {
19 if (obj instanceof Employee) {
20 Employee e = (Employee) obj;
21 return super.equals(obj) && e.getId() == id;
22 }
23 return false;
24 }
25
26 }
27
28 class Person {
29 private String name;
30
31 public Person(String _name) {
32 name = _name;
33 }
34
35 public String getName() {
36 return name;
37 }
38
39 public void setName(String name) {
40 this.name = name;
41 }
42
43 @Override
44 public boolean equals(Object obj) {
45 if (obj instanceof Person) {
46 Person p = (Person) obj;
47 if (null == p.getName() || null == name) {
48 return false;
49 } else {
50 return name.equalsIgnoreCase(p.getName());
51 }
52 }
53 return false;
54 }
55 }
员工类增加了工号ID属性,同时也覆写了equals方法,只有在姓名和ID都相同的情况下才表示同一个员工,这是为了避免一个公司中出现同名同姓员工的情况。看看上面的代码,这里的条件已经相当完善了,应该不会出错了,那我们测试一下,代码如下:
1 public static void main(String[] args) {
2 Employee e1 = new Employee("张三", 100);
3 Employee e2 = new Employee("张三", 1000);
4 Person p1 = new Person("张三");
5 System.out.println(p1.equals(e1));
6 System.out.println(p1.equals(e2));
7 System.out.println(e1.equals(e2));
8 }
上面定义了两个员工和一个社会闲杂人员,虽然他们同名同姓,但肯定不是同一个,输出都应该是false,但运行之后结果为: true true false
很不给力呀,p1竟然等于e1,也等于e2,为什么不是同一个类的两个实例竟然也会相等呢?这很简单,因为p1.equals(e1)是调用父类Person的equals方法进行判断的,它使用的是instanceof关键字检查e1是否是Person的实例,由于两者村子继承关系,那结果当然是true了,相等也就没有任何问题了,但是反过来就不成立了,e1和e2是不可能等于p1,这也是违反对称性原则的一个典型案例。
更玄的是p1与e1、e2相等,但e1和e2却不相等,似乎一个简单的符号传递都不能实现,这才是我们分析的重点:e1.equals(e2)调用的是子类Employee的equals方法,不仅仅要判断姓名相同,还要判断Id相同,两者工号是不同的,不相等也是自然的了。等式不传递是因为违反了equals的传递性原则,传递性原则指的是对于实例对象x、y、z来说,如果x.equals(y)返回true,y.equals(z)返回true,那么x.equals(z)也应该返回true。
这种情况发生的关键是父类引用了instanceof关键字,它是用来判断一个类的实例对象的,这很容易让子类钻空子。想要解决也很简单,使用getClass来代替instanceof进行类型判断,Person的equals方法修改后如下所示:
@Override
public boolean equals(Object obj) {
if (null != obj && obj.getClass() == this.getClass()) {
Person p = (Person) obj;
if (null == p.getName() || null == name) {
return false;
} else {
return name.equalsIgnoreCase(p.getName());
}
}
return false;
}
当然,考虑到Employee也有可能被继承,也需要把它的instanceof修改为getClass。总之,在覆写equals时建议使用getClass进行类型判断,而不要使用instanceof。
建议48:覆写equals方法必须覆写hashCode方法
覆写equals方法必须覆写hasCode方法,这条规则基本上每个Javaer都知道,这也是JDK的API上反复说明的,不过为什么要则这么做呢?这两个方法之间什么关系呢?本建议就来解释该问题,我们先看看代码:
public class Client48 {
public static void main(String[] args) {
// Person类的实例作为map的key
Map<Person, Object> map = new HashMap<Person, Object>() {
{
put(new Person("张三"), new Object());
}
};
// Person类的实例作为List的元素
List<Person> list = new ArrayList<Person>() {
{
add(new Person("张三"));
}
};
boolean b1 = list.contains(new Person("张三"));
boolean b2 = map.containsKey(new Person("张三"));
System.out.println(b1);
System.out.println(b2);
}
}
代码中的Person类与上一建议的Person相同,equals方法完美无缺。在这段代码中,我们在声明时直接调用方法赋值,这其实也是一个内部匿名类,现在的问题是b1和b2值是否都为true?
我们先来看b1,Person类的equals覆写了,不再判断两个地址相等,而是根据人员的姓名来判断两个对象是否相等,所以不管我们的new Person("张三")产生了多少个对象,它们都是相等的。把张三放入List中,再检查List中是否包含,那结果肯定是true了。
接下来看b2,我们把张三这个对象作为了Map的键(Key),放进去的是张三,检查的对象还是张三,那应该和List的结果相同了,但是很遗憾,结果为false。原因何在呢?
原因就是HashMap的底层处理机制是以数组的方式保存Map条目的(Map Entry)的,这其中的关键是这个数组的下标处理机制:依据传入元素hashCode方法的返回值决定其数组的下标,如果该数组位置上已经有Map条目,并且与传入的值相等则不处理,若不相等则覆盖;如果数组位置没有条目,则插入,并加入到Map条目的链表中。同理,检查键是否存在也是根据哈希码确定位置,然后遍历查找键值的。
接着深入探讨,那对象元素的hashCode方法返回的是什么值呢?它是一个对象的哈希码,是由Object类的本地方法生成的,确保每个对象有一个哈希码(也是哈希算法的基本要求:任意输入k,通过一定算法f(k),将其转换为非可逆的输出,对于两个输入k1和k2,要求若k1=k2,则必须f(k1)=f(k2),但也允许k1 != k2 , f(k1)=f(k2)的情况存在)。
那回到我们的例子上,由于我们没有覆写hashCode方法,两个张三对象的hashCode方法返回值(也就是哈希码)肯定是不相同的了,在HashMap的数组中也找不到对应的Map条目了,于是就返回了false。
问题清楚了,修改也很简单,在Person类中重写一下hashCode方法即可,代码如下:
class Person{
@Override
public int hashCode() {
return new HashCodeBuilder().append(name).toHashCode();
}
}
其中HashCodeBuilder是org.apache.commons.lang.builder包下的一个哈希码生成工具,使用起来非常方便,大家可以直接项目中集成(为何不直接写hashCode方法?因为哈希码的生成有很多种算法,自己写麻烦,事儿又多,所以必要的时候才取"拿来主义",不重复造轮子是最好的办法。)
建议49:推荐覆写toString方法
为什么要覆写toString方法,这个问题很简单,因为Java提供的默认toString方法不友好,打印出来看不懂,不覆写不行,看这样一段代码:
public class Client49 {
public static void main(String[] args) {
System.out.println(new Person("张三"));
}
}
class Person {
private String name;
public Person(String _name) {
name = _name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
输出结果是:[email protected]如果机器不同,@后面的内容也会不同,但格式都是相同的:类名[email protected]+hashCode,这玩意是给机器看的,人哪能看懂呀!这就是因为我们没有覆写Object类的toString方法的缘故,修改一下,代码如下:
@Override
public String toString() {
return String.format("%s.name=%s", this.getClass(),name);
}
如此即就可以在需要的时候输出调试信息了,而且非常友好,特别是在bean流行的项目中(一般的Web项目就是这样),有了这样的输出才能更好地debug,否则查找错误就有点麻烦!当然,当bean的属性较多时,自己实现就不可取了,不过可以直接使用apache的commons工具包中的ToStringBuilder类,简洁,实用又方便。可能有人会说,为什么通过println方法打印一个对象会调用toString方法?那是源于println的打印机制:如果是一个原始类型就直接打印,如果是一个类类型,则打印出其toString方法的返回值,如此而已。同时现在IDE也很先进,大家debug时也可查看对象的变量,但还是建议大家覆写toString方法,这样调试会更方便哦。
建议50:使用package-info类为包服务
Java中有一个特殊的类:package-info类,它是专门为本包服务的,为什么说它特殊,主要体现在三个方面:
- 它不能随便创建:在一般的IDE中,Eclipse、package-info等文件是不能随便被创建的,会报"Type name is notvalid"错误,类名无效。在Java中变量定义规范中规定如下字符是允许的:字母、数字、下划线,以及那个不怎么写的$符号,不过中划线可不在之列,那么怎么创建这个文件呢?很简单,用记事本创建一个,然后拷贝进去再改一下就成了,更直接的办法就是从别的项目中拷贝过来。
- 它服务的对象很特殊:一个类是一类或一组事物的描述,比如Dog这个类,就是描述"阿黄"的,那package-info这个类描述的是什么呢?它总是要有一个被描述或陈述的对象吧,它是描述和记录本包信息的。
- package-info类不能有实现代码:package-info类再怎么特殊也是 一个类,也会被编译成 package-info.class,但是在package-info.java文件不能声明package-info类。
package-info类还有几个特殊的地方,比如不可以继承,没有接口,没有类间关系(关联、组合、聚合等)等,Java中既然有这么特殊的一个类,那肯定有其特殊的作用了,我们来看看它的特殊作用,主要表现在以下三个方面:
- 声明友好类和包内访问常量:这个比较简单,而且很实用,比如一个包中有很多内部访问的类或常量,就可以统一放到package-info类中,这样很方便,便于集中管理,可以减少友好类到处游走的情况,代码如下:
class PkgClazz {
public void test() {
}
}
class PkgConstant {
static final String PACKAGE_CONST = "ABC";
}
注意以上代码是放在package-info.java中的,虽然它没有编写package-info的实现,但是package-info.class类文件还是会生成。通过这样的定义,我们把一个包需要的常量和类都放置在本包下,在语义上和习惯上都能让程序员更适应。
- 为在包上提供注解提供便利:比如我们要写一个注解(Annotation),查看一下包下的对象,只要把注解标注到package-info文件中即可,而且在很多开源项目中也采用了此方法,比如struts2的@namespace、hibernate的@FilterDef等.
- 提供包的整体注释说明:如果是分包开发,也就是说一个包实现了一个业务逻辑或功能点或模块或组件,则该包需要一个很好的说明文档,说明这个包是做什么用的,版本变迁历史,与其他包的逻辑关系等,package-info文件的作用在此就发挥出来了,这些都可以直接定义到此文件中,通过javadoc生成文档时,会吧这些说明作为包文档的首页,让读者更容易对该包有一个整体的认识。当然在这点上它与package.html的作用是相同的,不过package-info可以在代码中维护文档的完整性,并且可以实现代码与文档的同步更新。
创建package-info,也可以利用IDE工具如下图:
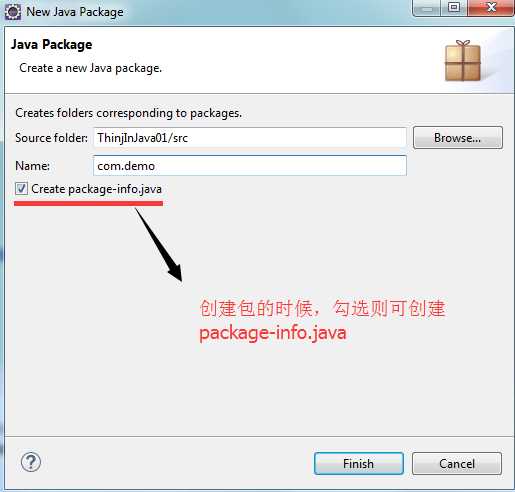
解释了这么多,总结成一句话:在需要用到包的地方,就可以考虑一下package-info这个特殊类,也许能起到事半功倍的作用。
建议51:不要主动进行垃圾回收
很久很久以前,在java1.1的年代里,我们经常会看到System.gc这样的调用---主动对垃圾进行回收,不过,在Java知识深入人心后,这样的代码就逐渐销声匿迹了---这是好现象,因为主动进行垃圾回收是一个非常危险的动作。
之所以危险,是因为System.gc要停止所有的响应,才能检查内存中是否存在可以回收的对象,这对一个应用系统来说风险极大,如果是一个Web应用,所有的请求都会暂停,等待垃圾回收器执行完毕,若此时堆内存(heap)中的对象少的话还可以接受,一但对象较多(现在的web项目是越做越大,框架、工具也越来越多,加载到内存中的对象当然也就更多了),这个过程非常耗时,可能是0.01秒,也可能是1秒,甚至20秒,这就严重影响到业务的运行了。
例如:我们写这样一段代码:new String("abc"),该对象没有任何引用,对JVM来说就是个垃圾对象。JVM的垃圾回收器线程第一次扫描(扫描时间不确定,在系统不繁忙的时候执行)时给它贴上一个标签,说"你是可以回收的",第二次扫描时才真正的回收该对象,并释放内存空间,如果我们直接调用System.gc,则是说“嗨,你,那个垃圾回收器过来检查一下有没有垃圾对象,回收一下”。瞧瞧看,程序主动找来垃圾回收器,这意味着正在运行的系统要让出资源,以供垃圾回收器执行,想想看吧,它会把所有的对象都检查一遍,然后处理掉那些垃圾对象。注意哦,是检查每个对象。
不要调用System.gc,即使经常出现内存溢出也不要调用,内存溢出是可分析的,是可以查找原因的,GC可不是一个好招数。
以上是关于转载--编写高质量代码:改善Java程序的151个建议(第3章:类对象及方法___建议47~51)的主要内容,如果未能解决你的问题,请参考以下文章
转载---编写高质量代码:改善Java程序的151个建议(第2章:基本类型___建议26~30)
转载--编写高质量代码:改善Java程序的151个建议(第3章:类对象及方法___建议31~35)
转载--编写高质量代码:改善Java程序的151个建议(第5章:数组和集合___建议60~64)
转载--编写高质量代码:改善Java程序的151个建议(第3章:类对象及方法___建议47~51)