出现梯度消失和梯度爆炸的原因及解决方案
Posted zhibei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了出现梯度消失和梯度爆炸的原因及解决方案相关的知识,希望对你有一定的参考价值。
梯度消失和梯度爆炸其实是一种情况:均是在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。
梯度消失产生的原因:
(1)隐藏层的层数过多;
(2)采用了不合适的激活函数(更容易产生梯度消失,但是也有可能产生梯度爆炸)
梯度爆炸产生的原因:
(1)隐藏层的层数太多;
(2)权重初始化值过大。
1、为什么说隐藏层数过多会造成梯度消失或梯度爆炸?
从深层网络角度来讲,不同的层学习的速度差异很大,表现为网路中靠近输出的层学习的情况很好,靠近输入的层学习的很慢,有时甚至训练了很久,前基层的权值和刚开始随机初始化的值差不多。因此,梯度消失、爆炸,其根本原因在于反向传播训练法则,属于先天不足。
2、为什么激活函数会影响?
我们以下图的反向传播为例,假设每一层只有一个神经元且对于每一层都可以用公式1表示,其中δ为sigmoid函数,C表示的是代价函数,前一层的输出和后一层的输入关系如公式1所示。我们可以推导出公式2:

其导数图像如下图所示:
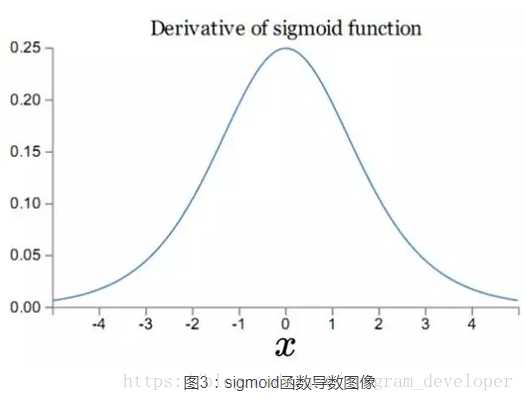
可见,sigmoid导数的最大值为1/4,而我们一般会使用标准方法来初始化网络权重,即使用一个均值为0,标准差为1的高斯分布。因此,初始化的网络权值通常都小于1,对于2的链式求导,层数越多,求导结果越小,最终导致梯度消失的情况出现。所以说,sigmoid函数一般不适合用于神经网络中。
3、初始化权重的值过大
也就是w比较大的情况下,根据2式的链式相乘可得(反向传播),则前面的网络层比后面的网络层梯度变化更快,引起了梯度爆炸的问题。所以,在一般的神经网络中,权重的初始化一般都利用高斯分布随机产生权重值。
梯度消失与梯度爆炸的解决方案:
(1)预训练加微调
(2)梯度剪切、正则
(3)ReLU、LeakyReLU、ELU等激活函数
(4)BatchNormalization
(5)参差结构
(6)LSTM
参考:https://www.cnblogs.com/XDU-Lakers/p/10553239.html
以上是关于出现梯度消失和梯度爆炸的原因及解决方案的主要内容,如果未能解决你的问题,请参考以下文章