RNN中的梯度消失爆炸原因
Posted elaine-dwl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RNN中的梯度消失爆炸原因相关的知识,希望对你有一定的参考价值。
RNN中的梯度消失/爆炸原因
梯度消失/梯度爆炸是深度学习中老生常谈的话题,这篇博客主要是对RNN中的梯度消失/梯度爆炸原因进行公式层面上的直观理解。
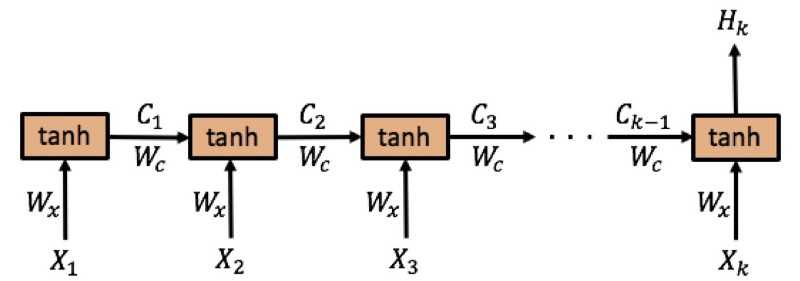
首先,上图是RNN的网络结构图,\\((x_1, x_2, x_3, …, )\\)是输入的序列,\\(X_t\\)表示时间步为\\(t\\)时的输入向量。假设我们总共有\\(k\\)个时间步,用第\\(k\\)个时间步的输出\\(H_k\\)作为输出(实际上每个时间步都有输出,这里仅考虑\\(H_k\\)),用\\(E_k\\)表示损失。
其中,\\(C_t=\\tanh \\left(W_c C_t-1+W_x X_t\\right)\\)
从上式可以看出 \\(W_x\\)和\\(W_c\\)其实是差不多的,记\\(W=[W_c, W_x]\\),那么求偏导可以得到:
\\(\\beginaligned \\frac\\partial E_k\\partial W=& \\frac\\partial E_k\\partial H_k \\frac\\partial H_k\\partial C_k \\frac\\partial C_k\\partial C_k-1 \\ldots \\frac\\partial C_2\\partial C_1 \\frac\\partial C_1\\partial W=\\\\ & \\frac\\partial E_k\\partial H_k \\frac\\partial H_k\\partial C_k\\left(\\prod_t=2^k \\frac\\partial C_t\\partial C_t-1\\right) \\frac\\partial C_1\\partial W \\endaligned\\)
其中的累乘部分为:
\\(\\beginaligned \\frac\\partial C_t\\partial c_t-1=& \\tanh ^\\prime\\left(W_c C_t-1+W_x X_t\\right) \\cdot \\fracdd C_t-1\\left[W_c C_t-1+W_x X_t\\right]=\\\\ & \\tanh ^\\prime\\left(W_c C_t-1+W_x X_t\\right) \\cdot W_c \\endaligned\\)
将该式代入上式有:
\\(\\frac\\partial E_k\\partial W=\\frac\\partial E_k\\partial H_k \\frac\\partial H_k\\partial C_k\\left(\\prod_t=2^k \\tanh ^\\prime\\left(W_c C_t-1+W_x X_t\\right) \\cdot W_c\\right) \\frac\\partial c_1\\partial W\\)
观察这个式子,和上篇文章中一样,因为链式法则,出现了累乘项,因为tanh的导数 <= 1,所以,当k很大的时候,上式的值是趋向于0的。(<1的数多次相乘),也就是:
\\(\\Pi_t=2^k \\tanh ^\\prime\\left(W_c C_t-1+w_x X_t\\right) \\cdot W_c \\rightarrow 0,\\) so \\(\\frac\\partial E_k\\partial W \\rightarrow 0\\)
此时,权重更新公式:
\\(W \\leftarrow W-\\alpha \\frac\\partial E_k\\partial W \\approx W\\)
也就是说,RNN很容易出现梯度消失现象,使得参数更新缓慢,甚至是停止更新。
以上是关于RNN中的梯度消失爆炸原因的主要内容,如果未能解决你的问题,请参考以下文章