详解 Python3 正则表达式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解 Python3 正则表达式相关的知识,希望对你有一定的参考价值。
本文翻译自:https://docs.python.org/3.4/howto/regex.html
博主对此做了一些批注和修改 ^_^

更多强大的功能
到目前为止,我们只是介绍了正则表达式的一部分功能。在这一篇中,我们学会到一些新的元字符,然后再教大家如何使用组来获得被匹配的部分文本。
更多元字符
还有一些元字符我们没有讲到,接下来博主一一为大家讲解。
有些元字符它们不匹配任何字符,只是简单地表示成功或失败,因此这些字符也称之为零宽断言。例如 \\b 表示当前位置位于一个单词的边界,但 \\b 并不能改变位置。因此,零宽断言不应该被重复使用,因为 \\b 并不会修改当前位置,所以 \\b\\b 跟 \\b 是没什么两样的。
批注:很多人可能不理解 “改变位置” 和 "零宽断言" 的意思?我尝试解释下,比如 abc 匹配完 a 之后,咱的当前位置就会移动,才能继续匹配 b,依次类推 ... 但是 \\babc 的话,\\b 表示当前位置在单词的边界(单词的第一个字母或者最后一个字母),这时候当前位置不会发生改变,接着将 a 与当前位置的字符进行匹配 ......
1. I
或操作符,对两个正则表达式进行操作。如果 A 和 B 是正则表达式,A | B 会匹配 A 或 B 中出现的任何字符。为了能够更加合理的式作,| 的优先级非常低。例如 Fa|n 应该匹配 Fa 或 n,而不是匹配 F,然后一个 ‘a‘ 或 ‘n‘。
同样,我们使用 \\| 来匹配 ‘|‘ 字符本身;或者包含在一个字符类中,像这样 [|] 。
2. ^
匹配字符串的起始位置。如果设置了 MULTILNE 标志,就会变成匹配每一行的起始位置。在 MULTILNE 中,每当遇到换行符就会立刻进行匹配。
举个例子,如果你只希望匹配位于字符串开头的单词 From,那么你的正则表达式可以写为 ^From:

3. $
匹配字符串的结束位置,每当遇到换行符也会离开进行匹配。
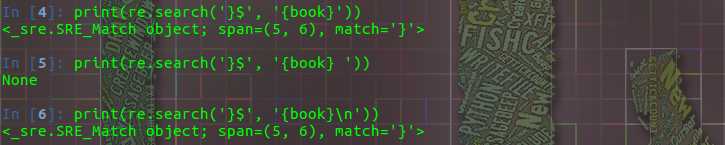
同样,我们使用 \\$ 来匹配 ‘$‘ 字符本身;或者包含在一个字符类中,像这样 [$] 。
4. \\A
只匹配字符串的起始位置,如果没有位置 MULTILINE 标志的时候,\\A 和 ^ 的功能是一样的;但如果设置了 MULTILNE 标志,则会有一些不同:\\A 还是匹配字符串的起始位置,但 ^ 会对字符串的每一行都进行匹配。
5. \\Z
只匹配字符串的结束位置。
6. \\b
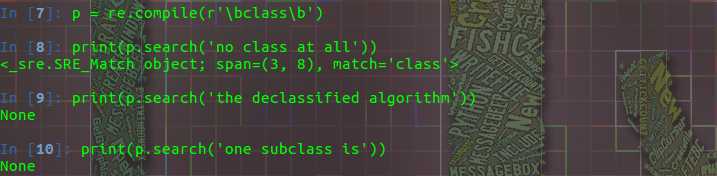
单词边界,这是一个只匹配单词的开始和结尾的零宽断言。“单词” 定义为一个字母数字的序列,所以单词的结束指的是空格或者非字母数字的字符。
下边例子中,class 只有在出现一个完整的单词 class 时才匹配;如果出现在别的单词中,并不会匹配。
在使用这些特殊的序列的时候,有两点是需要注意的:第一点需要注意的是,Python 的字符串跟正则表达式在有些字符上是有冲突的(回忆之前反斜杠的例子)。比如说在 Python 中,\\b 表示的是退格符(ASCII 码值是 8)。所以,你如果不使用原始字符串,Python 会将 \\b 转换成退格符处理,这样就肯定跟你预期不一样了。
下边例子中,我们故意不写表示原始字符串的 ‘r‘,结果确实大相庭径:

第二点需要注意的是,在字符类中不能使用这个断言。跟 Python 一样,在字符类中,\\b 只是用来表示退格符。
7. \\B
另一个零宽断言,与 \\b 的含义相反,\\B 表示非单词边界的位置。
分组
通常在实际的应用过程中,我们除了需要知道一个正则表达式是否匹配之外,还需要更多的信息。对于比较复杂的内容,正则表达式 通常使用分组的方式分别对不同内容进行匹配。
下边的例子,我们将 RFC-822 头用 “:” 号分成名字和值分别匹配:
From: [email protected] User-Agent: Thunderbird 1.5.0.9 (X11/20061227) MIME-Version: 1.0 To: [email protected]
像这种情况,我们就可以写一个正则表达式先来匹配一个整个 RFC-822 头,然后利用分组功能,使用一个组来匹配头的名字,另一个组匹配名字对应的值。
批注:RFC-822 是电子邮件的标准格式,当然到这里你还不知道分组要怎么分,不急,请接着往下看......
在正则表达式中,使用元字符 () 来划分组。() 元字符跟数学表达式中的小括号含义差不多;它们将包含在内部的表达式组合在一起,所以你可以对一个组的内容使用重复操作的元字符,例如 *,+,? 或者 {m,n} 。
例如,(ab)* 会匹配零个或者多个 ab:

使用 () 表示的子组我们还可以对它进行按层次索引,可以将索引值作为参数传递给这些方法:group(),start(),end() 和 span() 。序号 0 表示第一个分组(这个是默认分组,一直存在的,所以不传入参数相当于默认值 0):

批注:有几对小括号就是分成了几个子组,例如 (a)(b) 和 (a(b)) 都是由两个子组构成的。
子组的索引值是从左到右进行编号,子组也允许嵌套,因此我们可以通过从左往磾来统计左括号 ( 来确定子组的序号。

group() 方法可以一次传入多个子组的序号:

批注:start() 是获得参数子组的开始位置;end() 是获得对应子组的结束位置;span() 是获得对应子组的范围。
我们还特么通过 groups() 方法一次性返回所有的子组匹配的字符串:

还有一个反向引用的概念需要介绍,反向引用指的是你可以在后面的位置使用先前匹配过的内容,用法是反斜杠加上数字。例如 \\1 表示引用前边成功匹配的序号为 1 的子组。

如果只是搜索字符串,反向引用不会被用到,因为很少有文本格式会这样来重复字符。但是,你很快会发现,在字符串替换的时候,反向引用是非常有用的(深井水)!
批注:注意,在 Python 的字符串中会使用反斜杠加数字的方式来表示数字的值对应的 ASCII 字符,所以在使用反向索引的正则表达式中,我们依然强调要使用原始字符串。
(本文完)
下一篇:详解 Python3 正则表达式(五)
如果你喜欢这篇文章,请通过下方「评分」给我鼓励哦 ^_^
以上是关于详解 Python3 正则表达式的主要内容,如果未能解决你的问题,请参考以下文章