AlexNet详解2
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AlexNet详解2相关的知识,希望对你有一定的参考价值。
此处以caffe官方提供的AlexNet为例.
目录:
1.背景
2.框架介绍
3.步骤详细说明
5.参考文献
背景:
AlexNet是在2012年被发表的一个金典之作,并在当年取得了ImageNet最好成绩,也是在那年之后,更多的更深的神经网路被提出,比如优秀的vgg,GoogleLeNet.
其官方提供的数据模型,准确率达到57.1%,top 1-5 达到80.2%. 这项对于传统的机器学习分类算法而言,已经相当的出色。
框架介绍:
AlexNet的结构模型如下:
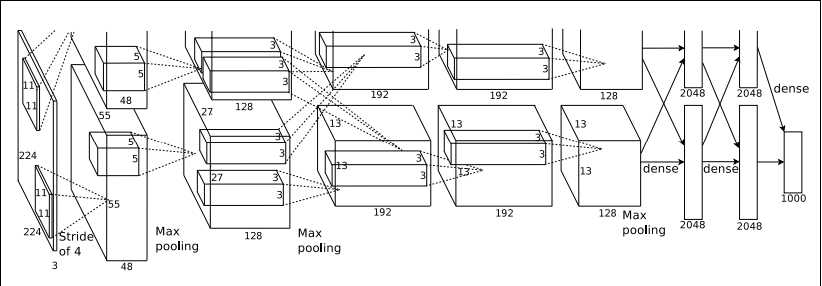
如上图所示,上图采用是两台GPU服务器,所有会看到两个流程图,我们这里以一台CPU服务器为例做描述.该模型一共分为八层,5个卷基层,,以及3个全连接层,在每一个卷积层中包含了激励函数RELU以及局部响应归一化(LRN)处理,然后在经过降采样(pool处理),下面我们来逐一的对每一层进行分析下吧.
3. 详细介绍:
1. 对于conv1层,如下

layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
}
}
该过程,
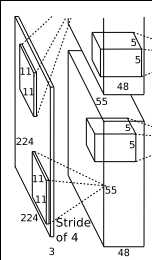
1.输入Input的图像规格: 224*224*3(RGB图像),实际上会经过预处理变为227*227*3
2.使用的96个大小规格为11*11的过滤器filter,或者称为卷积核,进行特征提取,(ps:图上之所以看起来是48个是由于采用了2个GPU服务器处理,每一个服务器上承担了48个).
需要特别提一下的是,原始图片为RBG图像,也就是三个通道的,我们这96个过滤器也是三通道的,也就是我们使用的实际大小规格为11*11*3,也就是原始图像是彩色的,我们提取到的特征也是彩色的,在卷积的时候,我们会依据这个公式来提取特征图: 【img_size - filter_size】/stride +1 = new_feture_size,所以这里我们得到的特征图大小为:
([227-11] / 4 + 1 )= 55 注意【】表示向下取整. 我们得到的新的特征图规格为55*55,注意这里提取到的特征图是彩色的.这样得到了96个55*55大小的特征图了,并且是RGB通道的.
需要特别说明的一点是,我们在使用过滤器filter和数据进行卷积时(ps: 卷积就是[1,2,3]*[1,1,1] = 1*1+2*1+3*1=6,也就是对应相乘并求和),而且我们使用的卷积核尺寸是11*11,也就是采用的是局部链接,每次连接11*11大小区域,然后得到一个新的特征,再次基础上再卷积,再得到新的特征,也就是将传统上采用的全链接的浅层次神经网络,通过加深神经网路层次也就是增加隐藏层,然后下一个隐藏层中的某一个神经元是由上一个网络层中的多个神经元乘以权重加上偏置之后得到的,也就是所偶为的权值共享,通过这来逐步扩大局部视野,(形状像金字塔),最后达到全链接的效果. 这样做的好处是节约内存,一般而言,节约空间的同时,消耗时间就会相应的增加,但是近几年的计算机计算速度的提升,如GPU.已经很好的解决了这个时间的限制的问题.
3. 使用RELU激励函数,来确保特征图的值范围在合理范围之内,比如{0,1},{0,255}
最后还有一个LRN处理,但是由于我一直都是没用这玩意,所以,哈哈哈哈哈哈,没有深切的体会,就没有发言权.
4. 降采样处理(pool层也称为池化),如下图:
layer {
name: "pool1"
type: "Pooling"
bottom: "norm1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
5. 使用LRN,中文翻译为局部区域归一化,对降采样的特征图数据进行如果,其中LRN又存在两种模式:
5.1 源码默认的是ACROSS_CHANNELS ,跨通道归一化(这里我称之为弱化),local_size:5(默认值),表示局部弱化在相邻五个特征图间中求和并且每一个值除去这个和.
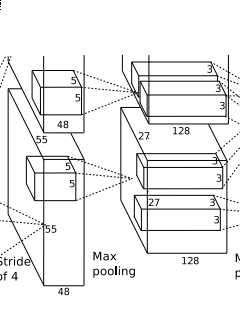
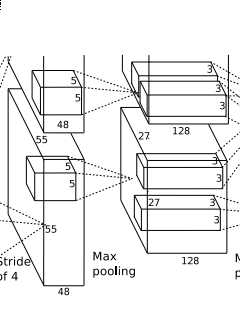
官方给的是内核是3*3大小,该过程就是3*3区域的数据进行处理(求均值,最大/小值,就是区域求均值,区域求最大值,区域求最小值),通过降采样处理,我们可以得到
( [55-3] / 2 + 1 ) = 27 ,也就是得到96个27*27的特征图,然后再以这些特征图,为输入数据,进行第二次卷积.
conv2层,如下图:
对应的caffe:
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
}
}
conv2和conv1不同,conv2中使用256个5*5大小的过滤器filter对96*27*27个特征图,进行进一步提取特征,但是处理的方式和conv1不同,过滤器是对96个特征图中的某几个特征图中相应的区域乘以相应的权重,然后加上偏置之后所得到区域进行卷积,比如过滤器中的一个点X11 ,如X11*new_X11,需要和96个特征图中的1,2,7特征图中的X11,new_X11 =1_X_11*1_W_11+2_X_11*2_W_11+7_X_11*7_W_11+Bias,经过这样卷积之后,然后在在加上宽度高度两边都填充2像素,会的到一个新的256个特征图.特征图的大小为:
(【27+2*2 - 5】/1 +1) = 27 ,也就是会有256个27*27大小的特征图.
然后进行ReLU操作.
再进行降采样【pool】处理,如下图,得到
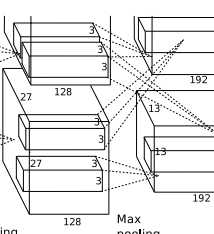
layer {
name: "pool2"
type: "Pooling"
bottom: "norm2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
得到: 【27-3】/2 +1 = 13 也就是得到256个13*13大小的特征图.
conv3层,如下图:
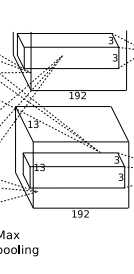
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
}
}
得到【13+2*1 -3】/1 +1 = 13 , 384个13*13的新特征图.
conv3没有使用降采样层.
conv4层:
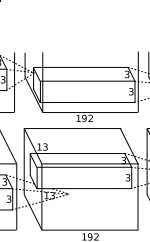
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
}
}
依旧
得到【13+2*1 -3】/1 +1 = 13 , 384个13*13的新特征图.
conv4没有使用降采样层.
conv5层,如下图:
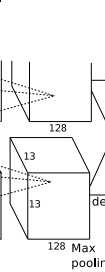
 View Code
View Code得到256个13*13个特征图.
降采样层pool,防止过拟合:
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
得到: 256个 (【13 - 3】/2 +1)=6 6*6大小的特征图.
fc6全链接图:
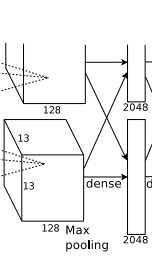
描述一下: 这里使用4096个神经元,对256个大小为6*6特征图,进行一个全链接,也就是将6*6大小的特征图,进行卷积变为一个特征点,然后对于4096个神经元中的一个点,是由256个特征图中某些个特征图卷积之后得到的特征点乘以相应的权重之后,再加上一个偏置得到.
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
以上是关于AlexNet详解2的主要内容,如果未能解决你的问题,请参考以下文章