09-01 面向对象编程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了09-01 面向对象编程相关的知识,希望对你有一定的参考价值。
[TOC]
一 对象的概念

”面向对象“的核心是“对象”二字,而对象的精髓在于“整合“,什么意思?
所有的程序都是由”数据”与“功能“组成,因而编写程序的本质就是定义出一系列的数据,然后定义出一系列的功能来对数据进行操作。在学习”对象“之前,程序中的数据与功能是分离开的,如下
# 数据:name、age、sex
name=‘lili‘
age=18
sex=‘female‘
# 功能:tell_info
def tell_info(name,age,sex):
print(‘<%s:%s:%s>‘ %(name,age,sex))
# 此时若想执行查看个人信息的功能,需要同时拿来两样东西,一类是功能tell_info,另外一类则是多个数据name、age、sex,然后才能执行,非常麻烦
tell_info(name,age,sex)在学习了“对象”之后,我们就有了一个容器,该容器可以盛放数据与功能,所以我们可以说:对象是把数据与功能整合到一起的产物,或者说”对象“就是一个盛放数据与功能的容器/箱子/盒子。
如果把”数据“比喻为”睫毛膏“、”眼影“、”唇彩“等化妆所需要的原材料;把”功能“比喻为眼线笔、眉笔等化妆所需要的工具,那么”对象“就是一个彩妆盒,彩妆盒可以把”原材料“与”工具“都装到一起
插图:对象与盒子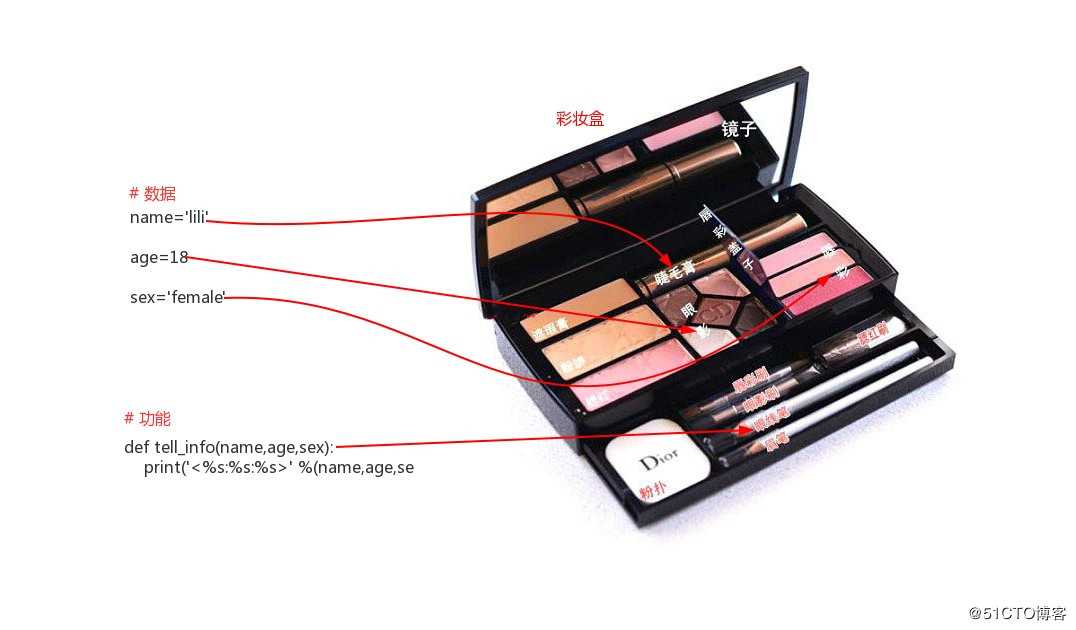
如果我们把”化妆“比喻为要执行的业务逻辑,此时只需要拿来一样东西即可,那就是彩妆盒,因为彩妆盒里整合了化妆所需的所有原材料与功能,这比起你分别拿来原材料与功能才能执行,要方便的多。
插图:恶搞图14
? 在了解了对象的基本概念之后,理解面向对象的编程方式就相对简单很多了,面向对象编程就是要造出一个个的对象,把原本分散开的相关数据与功能整合到一个个的对象里,这么做既方便使用,也可以提高程序的解耦合程度,进而提升了程序的可扩展性(需要强调的是,软件质量属性包含很多方面,面向对象解决的仅仅只是扩展性问题)
插图:软件质量属性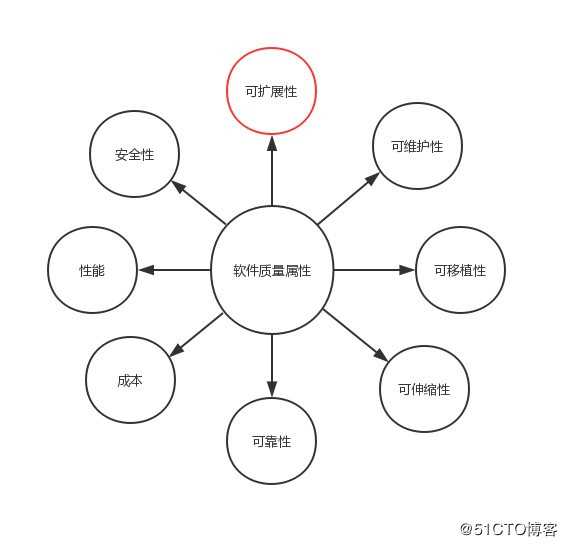
二 类与对象
类即类别/种类,是面向对象分析和设计的基石,如果多个对象有相似的数据与功能,那么该多个对象就属于同一种类。有了类的好处是:我们可以把同一类对象相同的数据与功能存放到类里,而无需每个对象都重复存一份,这样每个对象里只需存自己独有的数据即可,极大地节省了空间。所以,如果说对象是用来存放数据与功能的容器,那么类则是用来存放多个对象相同的数据与功能的容器。
插图:类与对象关系图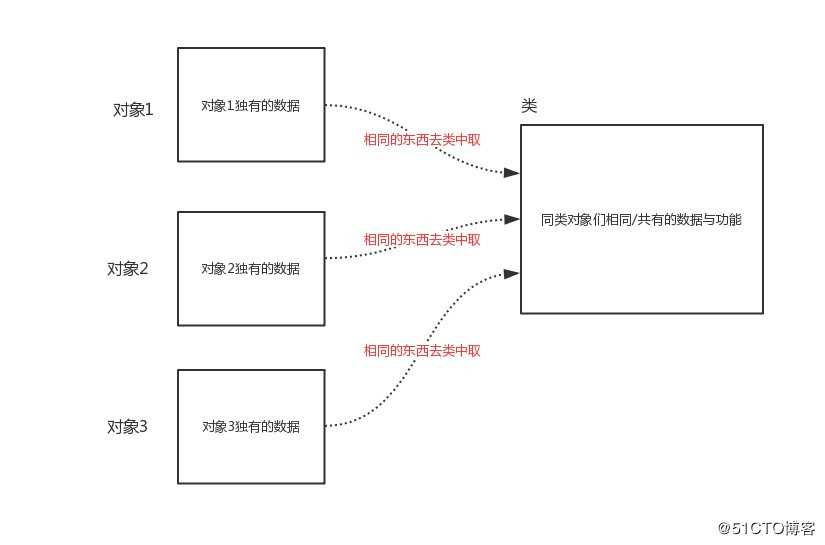
? 综上所述,虽然我们是先介绍对象后介绍类,但是需要强调的是:在程序中,必须要事先定义类,然后再调用类产生对象(调用类拿到的返回值就是对象)。产生对象的类与对象之间存在关联,这种关联指的是:对象可以访问到类中共有的数据与功能,所以类中的内容仍然是属于对象的,类只不过是一种节省空间、减少代码冗余的机制,面向对象编程最终的核心仍然是去使用对象。
? 在了解了类与对象这两大核心概念之后,我们就可以来介绍一下面向对象编程啦。
插图:恶搞图02

三 面向对象编程
3.1 类的定义与实例化
我们以开发一个清华大学的选课系统为例,来简单介绍基于面向对象的思想如何编写程序
插图:恶搞图03
面向对象的基本思路就是把程序中要用到的、相关联的数据与功能整合到对象里,然后再去使用,但程序中要用到的数据以及功能那么多,如何找到相关连的呢?我需要先提取选课系统里的角色:学生、老师、课程等,然后显而易见的是:学生有学生相关的数据于功能,老师有老师相关的数据与功能,我们单以学生为例,
# 学生的数据有
学校
名字
年龄
性别
# 学生的功能有
选课详细的
# 学生1:
数据:
学校=清华大学
姓名=李建刚
性别=男
年龄=28
功能:
选课
# 学生2:
数据:
学校=清华大学
姓名=王大力
性别=女
年龄=18
功能:
选课
# 学生3:
数据:
学校=清华大学
姓名=牛嗷嗷
性别=男
年龄=38
功能:
选课我们可以总结出一个学生类,用来存放学生们相同的数据与功能
# 学生类
相同的特征:
学校=清华大学
相同的功能:
选课插图:恶搞图04
基于上述分析的结果,我们接下来需要做的就是在程序中定义出类,然后调用类产生对象
class Student: # 类的命名应该使用“驼峰体”
school=‘清华大学‘ # 数据
def choose(self): # 功能
print(‘%s is choosing a course‘ %self.name)类体最常见的是变量的定义和函数的定义,但其实类体可以包含任意Python代码,类体的代码在类定义阶段就会执行,因而会产生新的名称空间用来存放类中定义的名字,可以打印Student.__dict__来查看类这个容器内盛放的东西
>>> print(Student.__dict__)
{..., ‘school‘: ‘清华大学‘, ‘choose‘: <function Student.choose at 0x1018a2950>, ...}插图:恶搞图05
调用类的过程称为将类实例化,拿到的返回值就是程序中的对象,或称为一个实例
>>> stu1=Student() # 每实例化一次Student类就得到一个学生对象
>>> stu2=Student()
>>> stu3=Student()如此stu1、stu2、stu3全都一样了(只有类中共有的内容,而没有各自独有的数据),想在实例化的过程中就为三位学生定制各自独有的数据:姓名,性别,年龄,需要我们在类内部新增一个__init__方法,如下
class Student:
school=‘清华大学‘
#该方法会在对象产生之后自动执行,专门为对象进行初始化操作,可以有任意代码,但一定不能返回非None的值
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
def choose(self):
print(‘%s is choosing a course‘ %self.name)
然后我们重新实例出三位学生
>>> stu1=Student(‘李建刚‘,‘男‘,28)
>>> stu2=Student(‘王大力‘,‘女‘,18)
>>> stu3=Student(‘牛嗷嗷‘,‘男‘,38)单拿stu1的产生过程来分析,调用类会先产生一个空对象stu1,然后将stu1连同调用类时括号内的参数一起传给Student.__init__(stu1,’李建刚’,’男’,28)
def __init__(self, name, sex, age):
self.name = name # stu1.name = ‘李建刚‘
self.sex = sex # stu1.sex = ‘男‘
self.age = age # stu1.age = 28会产生对象的名称空间,同样可以用__dict__查看
>>> stu1.__dict__
{‘name‘: ‘李建刚‘, ‘sex‘: ‘男‘, ‘age‘: 28}插图:恶搞图06

至此,我们造出了三个对象与一个类,对象存放各自独有的数据,类中存放对象们共有的内容
插图:对象容器与类容器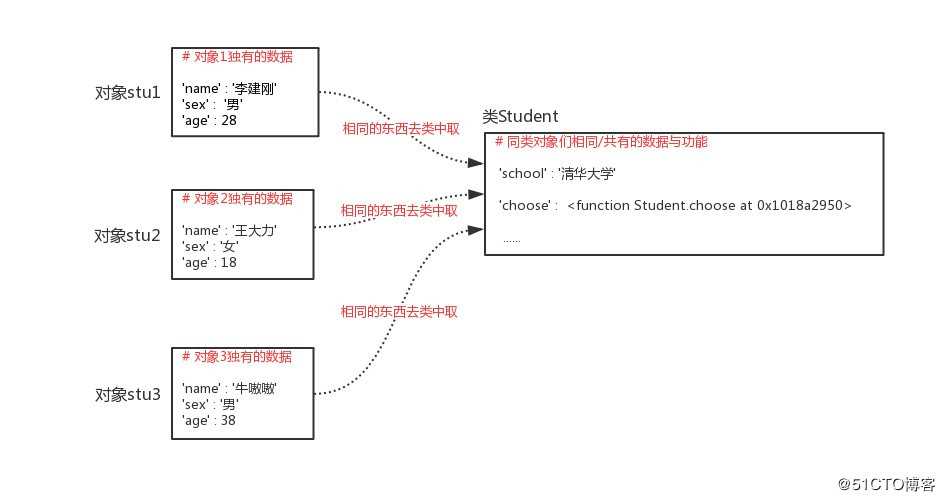
插图:恶搞图08
存的目的是为了用,那么如何访问对象或者类中存放的内容呢?
插图:恶搞图07
3.2 属性访问
3.2.1 类属性与对象属性
在类中定义的名字,都是类的属性,细说的话,类有两种属性:数据属性和函数属性,可以通过__dict__访问属性的值,比如Student.__dict__[‘school’],但Python提供了专门的属性访问语法
插图:恶搞图
>>> Student.school # 访问数据属性,等同于Student.__dict__[‘school‘]
‘清华大学‘
>>> Student.choose # 访问函数属性,等同于Student.__dict__[‘choose‘]
<function Student.choose at 0x1018a2950>
# 除了查看属性外,我们还可以使用Student.attrib=value(修改或新增属性),用del Student.attrib删除属性。操作对象的属性也是一样
>>> stu1.name # 查看,等同于obj1.__dict__[‘name‘]
‘李建刚‘
>>> stu1.course=’python’ # 新增,等同于obj1.__dict__[‘course‘]=‘python‘
>>> stu1.age=38 # 修改,等同于obj1.__dict__[‘age‘]=38
>>> del obj1.course # 删除,等同于del obj1.__dict__[‘course‘]插图:恶搞图08
3.2.2 属性查找顺序与绑定方法
对象的名称空间里只存放着对象独有的属性,而对象们相似的属性是存放于类中的。对象在访问属性时,会优先从对象本身的__dict__中查找,未找到,则去类的__dict__中查找
插图:恶搞图12
1、类中定义的变量是类的数据属性,是共享给所有对象用的,指向相同的内存地址
# id都一样
print(id(Student.school)) # 4301108704
print(id(stu1.school)) # 4301108704
print(id(stu2.school)) # 4301108704
print(id(stu3.school)) # 4301108704插图:恶搞图11、恶搞图13

2、类中定义的函数是类的函数属性,类可以使用,但必须遵循函数的参数规则,有几个参数需要传几个参数
Student.choose(stu1) # 李建刚 is choosing a course
Student.choose(stu2) # 王大力 is choosing a course
Student.choose(stu3) # 牛嗷嗷 is choosing a course但其实类中定义的函数主要是给对象使用的,而且是绑定给对象的,虽然所有对象指向的都是相同的功能,但是绑定到不同的对象就是不同的绑定方法,内存地址各不相同
print(id(Student.choose)) # 4335426280
print(id(stu1.choose)) # 4300433608
print(id(stu2.choose)) # 4300433608
print(id(stu3.choose)) # 4300433608绑定到对象的方法特殊之处在于,绑定给谁就应该由谁来调用,谁来调用,就会将’谁’本身当做第一个参数自动传入(方法__init__也是一样的道理)
stu1.choose() # 等同于Student.choose(stu1)
stu2.choose() # 等同于Student.choose(stu2)
stu3.choose() # 等同于Student.choose(stu3)绑定到不同对象的choose技能,虽然都是选课,但李建刚选的课,不会选给王大力,这正是”绑定“二字的精髓所在。
#注意:绑定到对象方法的这种自动传值的特征,决定了在类中定义的函数都要默认写一个参数self,self可以是任意名字,但命名为self是约定俗成的。插图:恶搞图10
Python中一切皆为对象,且Python3中类与类型是一个概念,因而绑定方法我们早就接触过
#类型list就是类
>>> list
<class ‘list‘>
#实例化的到3个对象l1,l2,l3
>>> l1=list([1,2,3])
>>> l2=list([‘a‘,‘b‘,‘c‘])
>>> l3=list([‘x‘,‘y‘])
#三个对象都有绑定方法append,是相同的功能,但内存地址不同
>>> l1.append
<built-in method append of list object at 0x10b482b48>
>>> l2.append
<built-in method append of list object at 0x10b482b88>
>>> l3.append
<built-in method append of list object at 0x10b482bc8>
#操作绑定方法l1.append(4),就是在往l1添加4,绝对不会将4添加到l2或l3
>>> l1.append(4) #等同于list.append(l1,4)
>>> l1
[1,2,3,4]
>>> l2
[‘a‘,‘b‘,‘c‘]
>>> l3
[‘x‘,‘y‘]插图:恶搞图11
3.3.3 小结
在上述介绍类与对象的使用过程中,我们更多的是站在底层原理的角度去介绍类与对象之间的关联关系,如果只是站在使用的角度,我们无需考虑语法“对象.属性"中”属性“到底源自于哪里,只需要知道是通过对象获取到的就可以了,所以说,对象是一个高度整合的产物,有了对象,我们只需要使用”对象.xxx“的语法就可以得到跟这个对象相关的所有数据与功能,十分方便且解耦合程度极高。
插图:恶搞图12、恶搞图15


以上是关于09-01 面向对象编程的主要内容,如果未能解决你的问题,请参考以下文章