Kubernetes-Service资源详解
Posted yangtian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes-Service资源详解相关的知识,希望对你有一定的参考价值。
service的三种工作模式:(userstats(效率低)、iptables、ipvs)
service可以自动实现负载均衡。service自动实现了负载均衡,service通过selector标签选择器匹配了后面多个pod!后端多个pod提供底层服务。
Service版本介绍
userspace: 1.1之前版本
iptabls: 1.10之前版本
ipvs: 1.11之后版本
service依赖core-dns
四种service类型:
ExternalName(把外部集群服务引入到集群内部使用)、ClusterIP(默认这个。仅仅用于集群内部通信)、NodePort(和集群外部通信)、LoadBalance(把k8s部署在云环境上面,云环境支持LBAS(负载均衡即服务一键调用),创建软负载均衡器使用。自动外部触发创建一个负载均衡,例如阿里LB-service)。
资源记录
SVC_NAME.NS_NAME.DOMAIN.LTD. #提供service服务域名格式
svc.clusqter.local #集群的默认名字域名
redis.default.svc.clustel.local. #每一个服务生产的域名格式,默认格式
Service用标签selector和后端pod建立关系,所以pod要先跑起来。
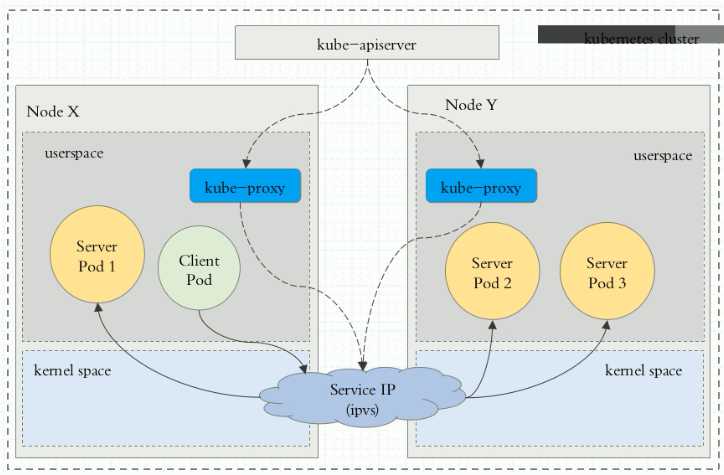
0、kube-proxy时刻watch监控着api-server,只要service发生变化,转换为当前节点实现调度的资源规则(有可能是iptables或者ipvs,取决于service的实现方式(userspace、iptables、ipvs))
1、service依赖dns服务,较新版本默认用的coredns,1.11之前版本用的kube-dns。service的名称解析强依赖于dns附件。所有dns必须部署。
2、k8s向客户提供网络功能,依赖第三方方案,可以用cni容器网络插件标准接口,另外还有flanael、calico插件也支持。
3、k8s有三类ip地址,节点ip网络、pod网络、集群地址cluster network(virtual ip虚拟ip)。
service工作。每个节点至少,node节点工作有一个组件kube-proxy,通过master上的api-server始终监视着有关service的变动信息。这种行为方式成为watch,一旦有service变化,kube-proxy转换为当前节点之上,能够实现service资源调度的规则,这种规则有可能是iptables,或者ipVS。规则取决于service的实现方式。
service三种工作代理模式(userstats(效率低)、iptables、ipvs)
第一种方式userstats:下面是用户空间模型解析。内部客户端用户请求clientPod,请求某个服务时,到达当前节点的内核空间iptables规则(其实就是service的规则)。service的工作方式是请求到达service以后,由service转换为本地监听在某个套接字的用户空间的kuber-proxy,kube-proxy处理完成再转给serviceip。最终代理这个这个service相关联的各个pod。最终实现调度。这个效率很低下。
第二种方式 iptables:客户端ip直接请求service ip。这个请求报文在本地内核空间的service的规则所截取。进而直接调度,service相关联的pod。区别是:直接工作在内核空间。由iptables规则直接负责调度。而第一种是由工作在内核空间的kube-proxy负责调度,所有第一种叫userstats。第二种叫iptabls。
第三种方式 ipvs。 client的请求到达内核空间以后,直接由ipvs规则来调度,直接调度给pod网络访问的相关资源。
总结:所以设定service工作在什么模型,就运行在什么模式。1.1及之前用iptables。1.11默认用的ipvsq。ipvs没有被激活,自动降级为iptables。
实战(pod删除增加原理过程):#例子:假设Service的lable适配版本多了一个pod。这个pod立刻反馈到apiserver(因为pod的信息要保存在apiserver的etcd里面)。而后kuber-proxy检查watch到这种变化。将其转换为iptables规则。所以转换是动态的而且是实时的。删除也是同样的逻辑。
总结:pod变化会存储到apiserver的etcd里面。kube-proxy负责watch。watch信息会转为iptables规则
例子1-ClusterIP集群(使用yaml文件创建基于ClusterIP集群的service)
#查看当前service服务
[root@node-001 manifests]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 18d
#10.96.0.1是apiserver的地址。千万不能删除。
#这个千万不能删除,集群所有的pod需要10.96.0.1和集群的apiserver联系,这个地址是集群内的。
#apiserver有两个地址。一个面向集群外部,一个内部。
myapp NodePort 10.111.150.166 <none> 80:32489/TCP 16d
#删除之前创建的redis服务
[root@node-001 manifests]# kubectl delete svc redis
service "redis" deleted
#查看service的帮助文档
[root@node-001 manifests]# kubectl explain svc.spec
ports #把哪个端口和后端容器建立关系
selector #关联哪些pod资源
clusterIP #动态分配属于192端,假设使用固定,需要这个字段。创建没法改变。
#创建service的yaml文件
[root@node-001 manifests]# vim redis-service.yaml
apiVersion: v1
kind: Service
metadata:
name: redis
namespace: default #注意service和pod最好同一名称空间!
spec:
selector: #关联到哪些后端pod资源上面,只要pod打标签了,就会自动关联!
app: redis
role: logstor #打的标签是role,角色定义是logstorsdad
clusterIP: 10.97.97.97 #可以动态分配,不指定。建议不自己定义。或者自己定义。只要在10.96.0.0/12网段就可以。
type: ClusterIP #service集群类型
ports
- port: 6379 #service提供服务暴露的端口、service端口。
targetPort: 6379 #service后端容器的端口 NodePort 外网访问端口、容器端口
#生成service服务
[root@node-001 manifests]# kubectl apply -f redis-service.yaml
service/redis created
[root@node-001 manifests]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 18d
myapp NodePort 10.111.150.166 <none> 80:32489/TCP 17d
redis ClusterIP 10.97.97.97 <none> 6379/TCP 8m18s
#6379就是service提供的端口
#service创建好了,会在的core-dns自动生成记录svc、a等记录
资源记录格式:
SVC_NAME.NS_NAME.DOMAIN.LTD. #提供service服务域名格式
svc.clusqter.local #集群的默认名字域名
redis.default.svc.clustel.local. #例如redis在dns的记录格式显示。
#查看redis的service服务详细信息。
[root@node-001 manifests]# kubectl describe service redis
Name: redis
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"redis","namespace":"default"},"spec":{"clusterIP":"10.97.97.97","...
Selector: app=redis,role=logstor #被selector匹配到的pod资源的地址。
Type: ClusterIP
IP: 10.97.97.97
Port: <unset> 6379/TCP
TargetPort: 6379/TCP
Endpoints: 10.244.1.73:6379 #service后端提供真正pods地址是这个。
小知识:为什么没有直接到显示pods?因为service到pod之间是有个中间层的。service不会直接到pod。先到Endpoints,再有Endpoints关联到pod。endpoints其实也可以手动创建,我们可以忽略这一层面。
Session Affinity: None
Events: <none>
小知识:服务添加完成,会自动动态在dns添加记录,不止一个,保护svc,A记录等,此时可以解析记录格式。
例子2-service---NodePort集群(使用yaml文件创建基于NodePort集群的service)
#通过访问集群端口NodePort集群来定义。nodeport类型的service。集群外部可以直接访问!!!
#先创建pods,打标签,然后创建service关联这个标签的后端pod。
#创建pods、打标签
[root@node-001 manifests]# cat rs-demo.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: myapp
release: canary
template:
metadata:
name: myapp-pod
labels:
app: myapp
release: canary
environment: qa
spec:
containers:
- name: myapp-container
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
[root@node-001 manifests]# kubectl apply -f rs-demo.yaml
[root@node-001 manifests]# kubectl get pods -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
myapp-bv2ff 1/1 Running 0 17s 10.244.1.90 node-002 <none> <none> app=myapp,environment=qa,release=canary
myapp-zf2c6 1/1 Running 0 17s 10.244.1.89 node-002 <none> <none> app=myapp,environment=qa,release=canary
#创建service、创建基于NodePort-service集群的yaml文件
[root@node-001 manifests]# vim myapp-nodeport-service.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
selector:
app: myapp
role: canary #打的标签是role,角色定义是logstorsdad
clusterIP: 10.99.99.99 #可以动态分配,不指定。建议不自己定义。或者自己定义。只要在10.96.0.0/12网段就可以。
type: NodePort #service类型为nodeport类型!!
ports:
- port: 80 #service端口
targetPort: 80 #pod端口 NodePort 外网访问端口
nodePort: 30080 #节点端口,这样外部直接访问宿主机ip:30080就可以访问了,注意这个30080在所有的node都会启动!端口在30000~32767范围内!不指定也可以,随机分配.
#每一个节点nodePort端口,不能被占用,不指定随机分配。!一旦被占用!!!错误设置会导致节点这个端口服务不能访问!!!因为相当于在iptables设置重定向。做成了dnat了。
#端口从30000 到32767之间随机分配。
#创建NortPort的service集群
[root@node-001 manifests]# kubectl create -f myapp-nodeport-service.yaml
service/myapp created
#查看service服务
[root@node-001 manifests]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19d
myapp NodePort 10.99.99.99 <none> 80:30080/TCP 3m59s
service名字是myapp 集群类型是nodeport service集群ip serviceip端口是80 映射为node主机的端口30080
[root@node-001 manifests]#
#查看service详细信息
[root@node-001 manifests]# kubectl describe service myapp
Name: myapp
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=myapp,role=canary
Type: NodePort
IP: 10.99.99.99
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 30080/TCP #这边好像有点问题,应该前面pod关停的原因导致的。
Endpoints: <none>
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
[root@node-001 manifests]#
#在每一个node宿主机查看端口
[root@node-001 manifests]# netstat -tunlp|grep 32489
tcp6 0 0 :::30080 :::* LISTEN 3313/kube-proxy
#每一个node节点都开启了30080端口
#从集群外机器访问myapp的service的nodeport集群的应用
[root@k8s-master mainfests]# while true;do curl http://192.168.100.181:30080/hostname.html;sleep 1;done
#自动实现负载均衡。因为service自动实现了负载均衡,爽快。因为selector后面匹配了多个pod!多个pod提供服务。
#原理:经过好几层转换,先访问nodeport先转为service port,再转换为pod port。
#此时前面可以再加个nginx,或者lvs hapoxcy做反向代理。
#下面做下回滚,或者更新(前面有做实验),利用命令set 或者 patch 打补丁方式!
例子3-LoadBalance集群(使用yaml文件创建基于LoadBalance集群的service)
#LoadBalance这边没法做,假设购买阿里云6台ecs主机,又购买LBAS服务。ecs虚拟机部署了k8s,k8s可以与共有云交互IAAS的api,纯软件方式。请求创建一个外部的负载均衡器(0:31:00)。但是需要两级调度,先调度代理给nodeport服务,再由nodeport代码内部的servcie‘,service代理到真正的pod port。
例子4-LoadBalance集群
#ExternalName(把外部集群服务引入到集群内部使用)
#核心知识点:用于实现假设访问的服务在集群外,我们希望集群内可以访问到集群外服务。从而让集群内部服务访问外部服务像访问内部服务一样简单。
#建立一个service。这个service关联到外部服务。当内部的service服务访问时候,外部服务先转给node,node转给service。service转给port。
#查看帮助文档:[root@node-001 manifests]# kubectl explain svc.spec.externalName
Service调度机制(默认随机调度)
Pod会话保持(Session affinity)
核心知识:支持两种: ClientIP、None(默认),所以默认随机调度。配置为clientip,把来自同一ip客户端,始终调度到统一个pod里面。可通过patch打补丁方式修改# kubectl patch svc myapp -p ‘{"spec":{"sessionAffinity":"ClientIP"}}‘,改好不用重启pod,立即生效,强大到没有朋友!
Service资源还支持Session affinity(粘性会话)机制,可以将来自同一个客户端的请求始终转发至同一个后端的Pod对象,这意味着它会影响调度算法的流量分发功用,进而降低其负载均衡的效果。因此,当客户端访问Pod中的应用程序时,如果有基于客户端身份保存某些私有信息,并基于这些私有信息追踪用户的活动等一类的需求时,那么应该启用session affinity机制。
Service affinity的效果仅仅在一段时间内生效,默认值为10800秒,超出时长,客户端再次访问会重新调度。该机制仅能基于客户端IP地址识别客户端身份,它会将经由同一个NAT服务器进行原地址转换的所有客户端识别为同一个客户端,由此可知,其调度的效果并不理想。Service 资源 通过. spec. sessionAffinity 和. spec. sessionAffinityConfig 两个字段配置粘性会话。 spec. sessionAffinity 字段用于定义要使用的粘性会话的类型,它仅支持使用“ None” 和“ ClientIP” 两种属性值。如下:
例子(配置pod会话保持)
#用Session affinity配置调度的时候调度后端的同一个pod。
#通过patch打补丁方式对之前myapp这个service设置会话保持,格式为ClientIP.
[root@node-001 manifests]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19d
myapp NodePort 10.99.99.99 <none> 80:30080/TCP 57m
redis ClusterIP 10.97.97.97 <none> 6379/TCP 36m
[root@node-001 manifests]# kubectl patch svc myapp -p ‘{"spec":{"sessionAffinity":"ClientIP"}}‘
service/myapp patched
#查看service是否pod会话保持是否设置为ClientIP。
[root@node-001 manifests]# kubectl describe svc myapp
Name: myapp
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"myapp","namespace":"default"},"spec":{"clusterIP":"10.99.99.99","...
Selector: app=myapp,role=canary
Type: NodePort
IP: 10.99.99.99
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 30080/TCP
Endpoints: <none>
Session Affinity: ClientIP #这边已经显示pod会话保持设置为ClientIP
External Traffic Policy: Cluster
Events: <none>
[root@node-001 manifests]#
#查看pod会话保持情况。改完是动态生效的!不用重启!从集群外机器访问myapp的service的nodeport集群的应用
[root@k8s-master mainfests]# while true;do curl http://192.168.100.181:30080/hostname.html;sleep 1;done
Headless Service(没有cluster ip):
#headless service表示没有service没有cluster ip。访问直达pod。kubcetl get svc的之后clueter ip没有数值
#有时不需要或不想要负载均衡,以及单独的 Service IP。 遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)的值为 "None " 来创建 Headless Service。
#无头service,每一个service应该名字。并且这个service名字可以解析成对应的cluster ip。通常cluster ip只有一个,由cluster ip调度到后端的多个pod。假设解析service名字的时候。没有cluster ip,#去掉service ip,这样解析service名字因为不能解析到clusterip,从而解析到pod ip。pod ip可能多个.没有cluster ip的就是无头service,而是直接达到pod。
配置Headless Service:只要定义字段clusterIP的值为:None
例子(定义hedless service)
#创建yaml文件。注意不能定义nodeport。
[root@node-001 manifests]# vim myapp-service-headless.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp-svc
namespace: default
spec:
selector:
app: myapp #挑选后端有myapp的标签的pod
release: canary #打的标签是role,角色定义是logstorsdad
clusterIP: "None" #定义service类型为无头service。定义None。没有clusterip。只有service。访问的时候直接访问后端pod。
ports:
- port: 80 #service暴露的端口
targetPort: 80 #service后端提供的pod端口
#创建headless-service服务
[root@node-001 manifests]# kubectl apply -f myapp-service-headless.yaml
service/myapp-svc created
#查看clusterip没有数值!
[root@node-001 manifests]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19d
myapp NodePort 10.99.99.99 <none> 80:30080/TCP 96m
myapp-svc ClusterIP None <none> 80/TCP 2s #none表示无头service
redis ClusterIP 10.97.97.97 <none> 6379/TCP 74m
#service创建完成,会自动在core-dns添加记录!
#用dig进行名称解析。查看服务解析情况!非常实用!!
[root@node-001 manifests]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myapp-svc ClusterIP None <none> 80/TCP 2s #none表示无头service
[root@mater01 ~]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 4d4h
[root@node-001 manifests]# dig -t A myapp-svc.defautl.svc.cluster.local. @10.96.0.10
# @表示不使用本地配置的dns解析,而是使用指向目标dns服务器去进行解析!目标dns是k8s集群内部的dns地址。
;; ANSWER SECTION:
. 30 IN A 10.244.1.27
. 30 IN A 10.244.1.27
#dig总结:这边会显示所有A记录。后面直接显示pod的地址,由这些pod地址提供服务!但是如果是有头的service。dig出来的后面的ip显示的是service-ip地址!
总结(有头service和无头service区别):
#无头service:这边可以看到,无头service,解析的直接就是pod的ip地址
#有头service:解析的就是自己service的cluster ip地址。
service缺点
#service无法解决https访问问题。定义service以后,尤其是nodeport集群访问,需要经过2级转换调度,而且是4层调度,无论是iptables还是ipvs。4调度自身无法实现卸载https会话。
#ingress----k8s还有一种引入集群外部流量的方式,叫ingress。基于7层调度器。利用7层pod,将外部流量引入到内部。
------------恢复内容结束------------
以上是关于Kubernetes-Service资源详解的主要内容,如果未能解决你的问题,请参考以下文章
21-Kubernetes-Service详解-Service使用
20-Kubernetes-Service详解-Service介绍
k8s之dashboard认证资源需求资源限制及HeapSter