数据库的并发操作
Posted cpsyche
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库的并发操作相关的知识,希望对你有一定的参考价值。
数据库的并发操作
事务
事务(Transaction)是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。
事务是恢复和并发控制的基本单位
事务的ACID特性:
原子性(Atomicity):事务是数据库的逻辑工作单位
一致性(Consistency):事务执行的结果必须是使数据库从一个一致性状态变
到另一个一致性状态
隔离性(Isolation):一个事务的执行不能被其他事务干扰
持续性(Durability ):一个事务一旦提交,它对数据库中数据的改变就应该
是永久性的。
并发控制
事务是并发控制的基本单位
并发控制机制的任务
- 对并发操作进行正确调度
- 保证事务的隔离性
- 保证数据库的一致性
并发操作带来的数据不一致性
- 丢失修改(Lost Update)
- 不可重复读(Non-repeatable Read)
- 幻读(Phantom Read)
- 读“脏”数据(Dirty Read)
丢失修改:两个事务T-1和T-2读入同一数据并修改,T-2的提交结果破坏了T-1提交 的结果,导致T-1的修改被丢失。(修改-修改冲突)
不可重复读:事务1读取某一数据,事务2对其做了修改;当事务1再次读该数据 时,得到与前一次不同的值(读-更新冲突)
幻读:事务T-1按一定条件从数据库中读取了某些数据记录,事务T-2删除(插入) 了其中部分记录 ,当T-1再次按相同条件读取数据时,发现某些记录神秘地 消失(出现)了。(读-插入/删除冲突)
脏数据: 事务T-1修改某一数据,并将其写回磁盘;事务T-2读取同一数据后,T-1由 于某种原因被撤销这时T-1,已修改过的数据恢复原值,T-2读到的数据就 与数据库中的数据不一致T-2读到的数据就为“脏”数据,即不正确的数据(修 改-读冲突)
数据不一致性:由于并发操作破坏了事务的隔离性
并发控制就的目的就是要用正确的方式调度并发操作,使一个用户事务的执行不受其他事务的干扰,从而避免造成数据的不一致性
并发控制的主要技术
- 封锁(Locking)
- 时间戳
- 乐观控制法
- 多版本并发控制
封锁
封锁:封锁就是事务T在对某个数据对象(例如表、记录等)操作之前,先向系统发 出请求,对其加锁
封锁是实现并发控制的一个非常重要的技术
基本封锁类型
- 排它锁(Exclusive Locks,简记为X锁)又叫写锁
- 共享锁(Share Locks,简记为S锁)又叫读锁
排它锁:若事务T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都 不能再对A加任何类型的锁,直到T释放A上的锁保证其他事务在T释放A上 的锁之前不能再读取和修改A
共享锁:若事务T对数据对象A加上S锁,则事务T可以读A,但不能修改A,其它事务 只能再对A加S锁,而不能加X锁,直到T释放A上的S锁,保证其他事务可 以读A,但在T释放A上的S锁之前,不能对A做任何修改
封锁协议
封锁协议:在运用X锁和S锁对数据对象加锁时,需要约定一些规则,这些规则为 Locking Protocol
对封锁方式规定不同的规则,就形成了各种不同的封锁协议,在不同的程度上保证并发操作的正确调度。
封锁协议决定了事物的隔离级别。
三级封锁协议
- 一级封锁协议
- 二级封锁协议
- 三级封锁协议
一级封锁协议:事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。
? 正常结束(COMMIT)
? 非正常结束(ROLLBACK)
一级封锁协议可防止丢失修改,并保证事务T是可恢复的,它不能保证可重复读和不读“脏”数据。
二级封锁协议:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,读完 后即可释S锁。
二级封锁协议可以防止丢失修改和读“脏”数据
三级封锁协议:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,直到 事务结束才释放。
三级封锁协议可防止丢失修改、读脏数据和不可重复读。

事务的四个隔离级别
mysql中的隔离级别有四种:
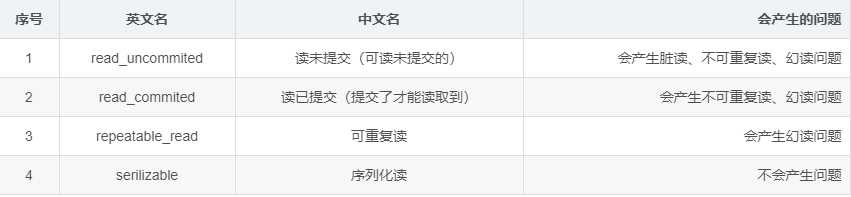
封锁的粒度
封锁对象的大小称为封锁粒度(Granularity)
封锁的对象:逻辑单元,物理单元
逻辑单元: 属性值、属性值的集合、元组、关系、索引项、整个索引、整个数据库等
物理单元:页(数据页或索引页)、物理记录等
封锁粒度与系统的并发度和并发控制的开销密切相关。
封锁的粒度越大,数据库所能够封锁的数据单元就越少,并发度就越小,系统开销也越小;
封锁的粒度越小,并发度较高,但系统开销也就越大
表锁:封锁粒度为表(关系)的锁
行锁:封锁粒度为行(元祖)的锁
悲观锁与乐观锁
(1)悲观锁:顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
(2)乐观锁: 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
(3)悲观锁 和 乐观锁的区别:
- 乐观锁在不发生取锁失败的情况下开销比悲观锁小,但是一旦发生失败回滚开销则比较大,因此适合用在取锁失败概率比较小的场景,可以提升系统并发性能
- 乐观锁还适用于一些比较特殊的场景,例如在业务操作过程中无法和数据库保持连接等悲观锁无法适用的地方
以上是关于数据库的并发操作的主要内容,如果未能解决你的问题,请参考以下文章