并发操作会带来哪些数据不一致性
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发操作会带来哪些数据不一致性相关的知识,希望对你有一定的参考价值。
参考技术A 并发操作带来的数据不一致性包括三类:丢失修改、不可重复读和读“脏”数据。避免不一致性的方法和技术就是并发控制,最常用的技术是封锁技术;也可以用其他技术,例如在分布式数据库系统中可以采用时间戳方法来进行并发控制。
丢失修改:两个事务T1和T2读入同一数据并修改,T2提交的结果破坏了(覆盖了)T1提交的结果,导致T1的修改被丢失。
不可重复读:不可重复读是指事务T1读取数据后,事务T2执行更新操作,使T1无法再现前一次读取结果。
读“脏”数据:读“脏”数据是指事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被撤销,这时T1已修改过的数据恢复原值,T2读到的数据就与数据库中的数据不一致,则T2读到的数据就为“脏”数据,即不正确的数据。
- 官方服务
- 官方网站官方网站
数据库 chapter 11 并发控制
第十一章 并发控制
介绍并发操作可能造成数据不一致的问题,讲解并发控制的基本概念和最常用的封锁技术。
在多处理机系统中,每个处理机可以运行一个事务,多个处理机可以同时运行多个事务,实现多个事务真正的并行运行,这种并行执行方式称为同时并发方式。
并发控制:为了保证事务的隔离性和一致性。
并发操作带来的数据不一致性主要包括丢失修改、不可重复读和读“脏”数据等。
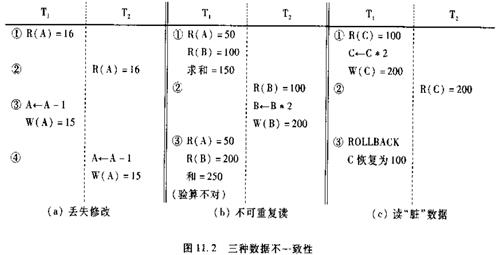
丢失修改:两个事物T1和T2读入同一数据并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失。例如:

不可重复读
不可重复读是指事物T1读取数据后,T2执行更新操作,使T 1无法再现前一次读取结果。

读“脏”数据

并发控制的主要技术有封锁(Locking)、时间戳(Timestamp)和乐观控制法,商用的DBMS一般都采用封锁方法。
封锁:在事务T对某个数据对象,例如表、记录等操作之前,先向系统发出请求,对其加锁,在事务T释放它的锁之前,其他事务不能更新此数据对象。
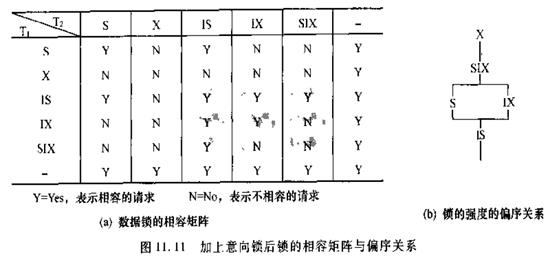
基本的锁有两种,排它锁(Exclusive Locks,简称X锁)和共享锁(Share Locks,简称S锁)。

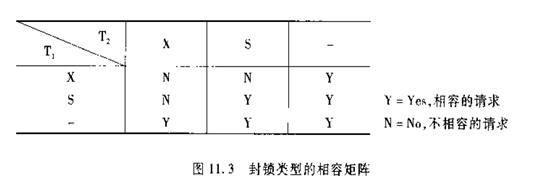


和操作系统一样,封锁的方法可能引起活锁和死锁等问题。
活锁:
如果事务T1封锁了数据R,事务T2又请求封锁R,于是T2等待。T3也请求封锁R,当T1释放了R上的封锁后系统首先批准了T3的请求,T2仍等待。然后T4又请求封锁R,T3释放了R上的封锁之后系统又批准了T4的请求,T2可能永远等待,这就是活锁。
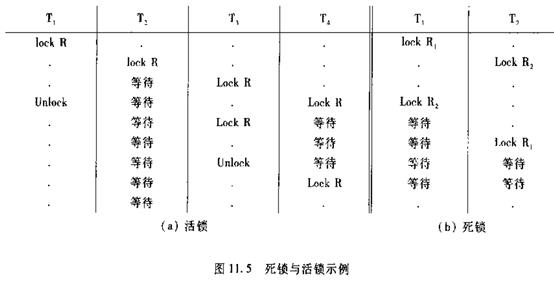
避免活锁的简单方法是采用先来先服务的策略,当多个事务请求封锁同一数据对象时,封锁子系统按请求封锁的先后次序对事务排队,数据对象上的锁一旦释放就批准申请队列中的第一个事务得锁。

死锁的预防:
一次封锁法:一次封锁发要求每个事务必须一次性将所有要使用的数据全部加锁,否则就不能继续执行。
顺序封锁法:预先对数据对象规定一个封锁顺序,所有事务都按照这个顺序实行封锁。
死锁的诊断与解除
超时法:如果一个事务的等待时间超过了规定时限,就认为发生了死锁。
等待图法:

并发调度的可串行性

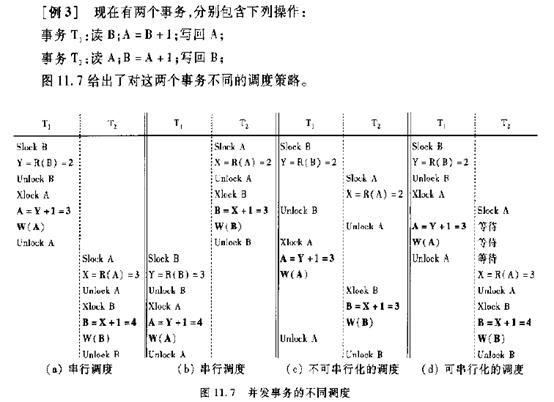

冲突可串行化调度


两段锁协议
目前DBMS普遍采用两段锁(Two-Phase Locking,简称2PL)协议的方法实现并发调度的可穿行性,从而保证调度的正确性。

就是封锁时间不可以解锁,解锁时间不可以封锁。



封锁的粒度
封锁对象的大小称为封锁粒度。封锁的对象可以是逻辑单元,也可以是物理单元。


多粒度封锁






以上是关于并发操作会带来哪些数据不一致性的主要内容,如果未能解决你的问题,请参考以下文章