从零开始学正则
Posted echolun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始学正则相关的知识,希望对你有一定的参考价值。

壹 ? 我为什么学正则
正则表达式是从侧面衡量一个程序员水平的标准,可以很肯定的说没有哪位高级开发不懂正则。在前端开发中使用正则表达式最频繁的场景莫过于表单验证,判断邮箱,判断手机号格式等等,那么我是怎么解决这些问题的呢,打开百度,输入“正则验证手机”回车,复制粘贴即可。我想大家应该看过不少关于常用正则整理的文章,我不理解正则,反正从来也记下来了。
古人云,熟读唐诗三百首,不会做诗也会吟。我会花三周左右系统化学习正则表达式,若你有兴趣可以与我一同学习(一起受苦),我相信学成之后即使无法立刻写出逼格满满的正则,但对于阅读大部分常见正则应该是没问题的。
另外,正则学习系列文章均为我阅读 老姚《JavaScript正则迷你书》的读书笔记,毕竟此时的我也只是一个学习者。这本书写的真的超级棒,推荐大家下载在闲暇时间阅读。
文中所有正则图解均使用regulex制作。
最后偷偷说一句,公司前端组没一个人懂正则,等我学会了我将是组里第一个略懂正则的人!!

贰 ? 正则两种模糊匹配
正则表达式是一种匹配模式,要么匹配字符(符合规则的字符),要么匹配位置(符合规则字符所在的位置)。
正则之所以强大,是因为正则能实现模糊匹配;在实际开发中,我们往往需要匹配某一范围的数据。举个贴切的例子,当验证用户输入邮箱格式是否正确,除了“ @ ”等固定字符以外,用户输入的具体字符我们是无法估量和统计的,精准匹配显得无能为力,也只有模糊匹配能巧妙解决这个问题。
正则表达式的模糊匹配分为横向模糊与纵向模糊两种:
1.横向模糊
其实不难理解,横向模糊表示正则匹配的字符长度是不确定的,我们可以通过正则的量词实现横向匹配。不知道大家有没有在B站看到过“233”的弹幕,“233”是一个网络用语,表示大笑的意思。但因为个人输入随心的习惯,可能打出2333,233333等不定长度的弹幕,那么我们匹配弹幕中有多少233大笑可以用正则这么写:
var regex = /23{2,}/;
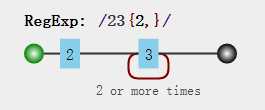
这里量词 {2,} 表示前面的3会出现2次或者更多次,量词后面会专门介绍。我们来试试这个正则:
var regex = /23{2,}/g; var str = ‘223 233 2323 2333‘; var result = str.match(regex); result//["233", "2333"]
注意正则后面有个小写的字母g,这是正则修饰符之一,g为global的简写,表示全局匹配。若不加g,match方法只会匹配第一个符合条件的字符。关于修饰符后文会详细介绍。
2.纵向模糊匹配
纵向模糊匹配是指具体某一位置可能有多种字符的情况,横向模糊可以用量词实现,而纵向模糊匹配可以使用字符组实现,比如:
var regex = /[abc]/;
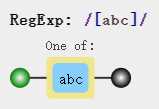
这段正则表示可匹配字母a b c其中一个,我们来看一个简单的例子:
var regex = /a[1-3]c/g; var str = "a0c a1c a2c a3c a4c"; var result = str.match(regex); result //["a1c", "a2c", "a3c"]
在这个例子中我们使用了字符组[1-3],它本质上与[123]效果相同,但因为是连贯数字所以支持范围简写。下面介绍具体介绍正则字符组。
叁 ? 正则字符组
在上一个例子中我们已经了解到字符组[123]可用范围表示法写成[1-3],这是非常有用的,设想一想,我们现在想匹配数字1-9,字母a-f,要写全的话就得这样[123456789abcdef],但通过范围表示法只用短短的[1-9a-f],是不是很奈斯:
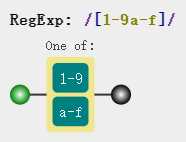
现在知道了连字符 - 的作用,那么现在我们就是要匹配1 - 3其中任意字符怎么做呢?有三种写法可解决这个问题,写成[-13]、[13-]或者使用转义符 表示[1-3]即可。
1.排除字符组
纵向模糊匹配还存在一种情况,就是某个位置可以是除了某几个字符之外的任意字符,比如我希望是除了1-3之外的任意字符,那么我们可以使用[^1-3]表示,注意这里使用了脱字符 ^。
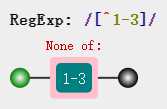
2.常用简写
了解了字符组范围表示法,那么想匹配数字0到9可以写成[0-9],其实它还有一种更简单的写法d,估计这部分是很多人常忘记的知识,我们来做个整理:
| 字符组 | 含义 |
| d | [0-9]表示是一位数字,digit数字。 |
| D | [^0-9]表示除数字以外的任意字符。 |
| w | [0-9a-zA-Z_]表示数字,大小写字母和下划线,word简写,又称单词字符。 |
| W | [^0-9a-zA-Z_],非单词字符。 |
| s | [ v f]表示空白符。包含空格,水平制表符,垂直制表符,换行符,回车符,换页符。 |
| S | [^ v f],非空白符。 |
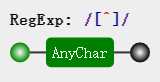
| . | [^ u2028u2029],通配符,表示除了换行符,回车符,行分隔符和段分隔符之外任意字符。 |
不懂就问,上述表格中空白字符都代表什么意思?这里我测试了下,可能因为语言的问题,很多字符在js环境中没法运行,C语言可以运行可惜我不懂...这里我做了查阅做了整理:
空格:顾名思义,就是我们理解的空格
水平制表符 :类似于tab键缩进的效果,一般系统中水平制表符占8列,所以根据你按的次数占据8*N列。
垂直制表符v:让文本从下一行开始输出,且开始的列数为v前字符的后一列。
换行符 :从下一行开头开始输出,这个js可以跑。
回车符 :这里的回车不是我们理解的enter回车另起一行开始输出,而是回到当前行开头输出,还可能将已输入文本替换,替换这一点根据环境不同表现不同。
换页符f:在输出f后面文本之前,会先将当前屏幕清空,类似于先清除再输出。
行分隔符和段分隔符,找了一圈也没看到好的解释,这里还望有缘人指点。
那么如果我们想匹配任意字符,有这几种写法[/d/D]、[/w/W]、[/s/S]、[^],其实不难理解,以[/d/D]为例,就是匹配数字以及除了数字以外的所有字符,这不就是所有字符了吗。
肆 ? 正则量词
| 量词 | 含义 |
| {m,n} | 至少出现m次,最多出现n次。 |
| {m,} | 至少出现m次,没有上限。 |
| {m} | 等价于{m,m},固定出现m次 |
| ? | 等价于{0,1},要么不出现,要么出现一次。 |
| + | 等价于{1,},至少出现1次,没有上限。 |
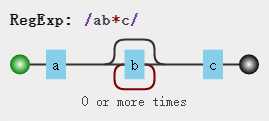
| * | 等价于{0,},表示出现任意次数,可以不出现,也可以任意次,包容型比?和+大。 |
1.贪婪匹配和惰性匹配
正则默认就是贪婪匹配,贪婪就是在量词匹配规则范围内最大限度的去匹配字符,我们来看个简单的例子:
var str = "ab abb abbb abbbb abbbbb"; var regex = /ab{2,4}/g; var result = str.match(regex); result //["abb", "abbb", "abbbb", "abbbb"]
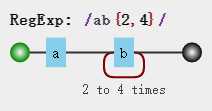
在这个例子中,我们匹配2-4个字母b,你给2个我要,给3个我要,哪怕给5个我也要尽我所能拿4个,是不是很贪心。
惰性与贪婪相反,惰性匹配就是在量词匹配范围内以最小限度去匹配字符,无欲无求做人本分,我们只需要在量词后接个?即是惰性匹配,看个例子:
var str = "ab abb abbb abbbb abbbbb"; var regex = /ab{2,4}?/g; var result = str.match(regex); result //["abb", "abb", "abb", "abb"]
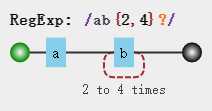
大家会不会觉得惰性匹配情况下这个次数4是不是没意义了呢?其实并不是没意义,尽管惰性匹配是以最小2次为匹配规则,但被匹配的字符前提条件是满足2-4之间,4还是起到了限制条件,我们改改例子再看:
var str = "abc abbc abbbc abbbbc abbbbbc"; var regex = /ab{2,4}?c/g; var result = str.match(regex); result //["abbc", "abbbc", "abbbbc"]
上述例子中当匹配到字段 abbbbbc 时因为字母b已经超过范围,所以不在匹配范围内。惰性可以理解为,在匹配范围内拿最少的东西,我可以过的无欲无求,但也得过的温饱活得下去才行啊。
伍 ? 正则多选分支
如果说横向模糊匹配和纵向模糊匹配都是一种匹配模式,那如果需要同时使用多种模式怎么办呢,这里我们就可以使用管道符 | 实现这一点,来看个简单的例子:
var str = "a0c a1c a2c a3c abc abbc abbbc abbbbc"; var regex = /a[1-3]c|ab{1,3}c/g; var result = str.match(regex); result //["a1c", "a2c", "a3c", "abc", "abbc", "abbbc"]
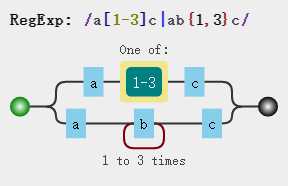
在这个例子中,我们使用了纵向模糊匹配和横向模糊匹配两种模式。
需要注意的是,分支匹配也是惰性匹配,即前面的匹配模式能满足,后面就不匹配了,来看个例子:
var str = "userName"; var regex = /user|userName/g; var result = str.match(regex); result //["user"]
这非常类似于js短路运算符中的||,以a||b为例,倘若a为真那么b就不判断了。
function fn1() { console.log(1); return true; }; function fn2() { console.log(2); return true; }; fn1() || fn2(); //1
我们再来个反转,情理上来说分支匹配是惰性,但有一种特殊情况,直接上例子:
var str = "userName"; var regex = /Name|userName/g; var result = str.match(regex); result //["userName"]
哎?怎么不是匹配Name字段,其实我也有这个疑问,去查了下也没看到合理的解释...我的猜测是,正则是从左往右的匹配机制,若左侧一开始无法匹配成功(user和Name对应不上),则优先考虑了分支其它情况。
var str = "userName"; var regex = /Name/g; var result = str.match(regex); result //["Name"]
陆 ? 总
那么到这里,javascript正则迷你书第一章节就看完了。我们做个总结,大家可以看着思维导图回顾下知识点:
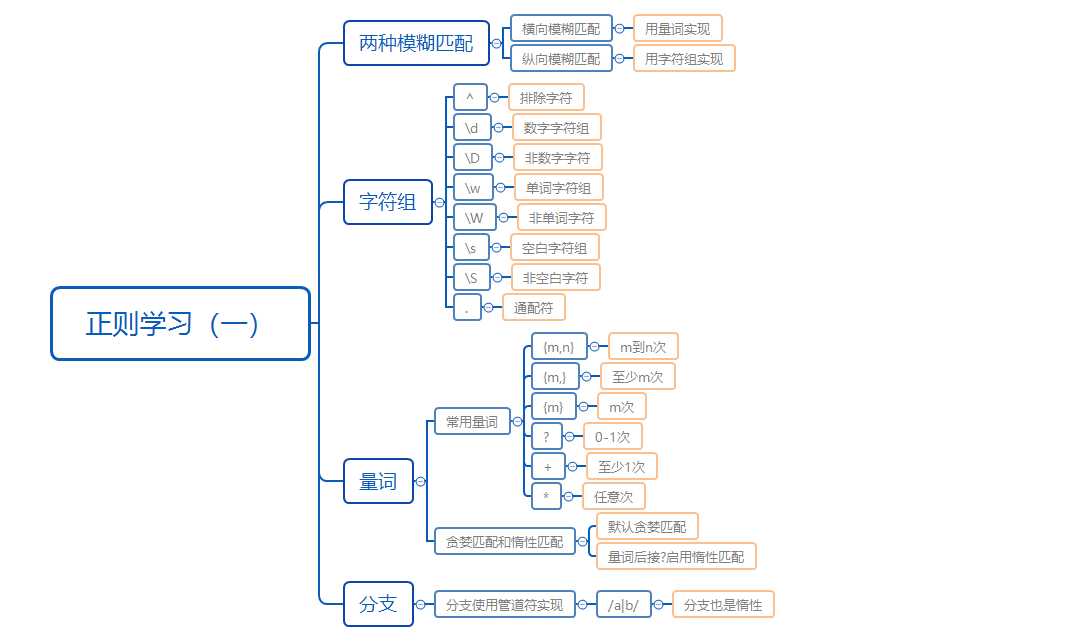
另外留两个思考题,尝试写出匹配24小时制的正则匹配,以及匹配16进制颜色值的正则,注意,16进制颜色是支持#dddddd与#ddd两种。
那么到这里本文结束,我也要抓紧时间看第二章节了。
以上是关于从零开始学正则的主要内容,如果未能解决你的问题,请参考以下文章