价格预测方法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了价格预测方法相关的知识,希望对你有一定的参考价值。
参考技术A 第一章价格预测概论第一节预测的性质
一、预测是一门古老的行业
二、预测是人类认识和改造世界的重要工具
三、未来是可预测的,但任何预测结果都是概率性的
四、对人类活动的预测会影响人的行为并可能导致某些
预测失效,但这种影响也是需要一定条件的
五、预测根据和理由比预测结果更重要
第二节价格预测由来及特点
一、价格预测由来已久
二、价格预测的特点
第三节价格预测的理论基础
一、供求与均衡价格
二、价格总水平及通货膨胀
三、通胀预期问题
第四节预测原则、方法及模型有关问题
一、预测工作基本原则
二、预测方法
三、数量模型的有关问题
第五节价格预测应做好的主要工作
一、预测的前期分析
二、价格预测中需要注意处理的问题
三、预测的评估总结
第二章价格预测调查与定性分析
第一节价格预测调查意义及形式
一、价格预测调查的意义
二、价格调查形式的分类
三、常用的价格调查形式
四、价格调查的原则和主要步骤
第二节价格预测定性分析内容和方法
一、定性分析的内容
二、定性分析的主要方法及形式
第三节价格预测定性分析与定量分析之间的关系
一、价格定性预测的概念
二、价格定量预测的概念
三、价格定量预测与价格定性预测的相互关系
第三章价格预测的主要模型方法及操作
第一节线性回归方法
tushare实战LSTM实现黄金价格预测
tushare实战LSTM实现黄金价格预测
文章目录
拉取数据
老样子,之前tushare实战分析黄金与美元收益率关系的时候也是这样,注意: pro_api中的东西是tushare的token
# 导入tushare
import tushare as ts
# 初始化pro接口
pro = ts.pro_api('xxx')
# 拉取数据
df = pro.fx_daily(**
"ts_code": "XAUUSD.FXCM",
"trade_date": "",
"start_date": 20160910,
"end_date": 20210910,
"exchange": "FXCM",
"limit": "",
"offset": ""
, fields=[
"ts_code",
"trade_date",
"bid_open",
"bid_close",
"bid_high",
"bid_low",
"ask_open",
"ask_close",
"ask_high",
"ask_low",
"tick_qty"
])
print(df)
df.set_index('trade_date',inplace=True)
df.to_csv('黄金数据2016-9-10至2021-9-10.csv')
数据预处理
LSTM模型的核心是用一个序列数据去预测未来的数据,序列数据的构造思路: 构造一个队列,将每日的数据视为一个个体,当后一个个体进入队列的时候,就会挤出队首的个体,然后在每个时刻都‘拍照’记录下队列的情况,就可以得到一个三维数据(len, men_day, attribute)其中len是序列的个数,假设数据集中有100条数据,我们将5天作为一个序列,那么就会有100-5+1=96个序列,men_day就是那个5天的5,表示序列的长度,attribute则是原数据的协变量(就是数据的特征);
了解了输入数据后,我们就要处理输出数据,假设我们想用截止到今天的数据去预测未来五天的价格,那么构造训练集的时候,就要将价格数据作为标签,向前shift5天;也就是在一条数据中,除了那些他原本就有的数据,还会多一个5天之后的价格。按照这个思路,写出数据预处理函数,其中deque表示的就是那个队列
mem_his_days就是序列的长度,pre_days就是预测未来几天的价格
def Stock_Price_LSTM_Data_Precesing(df,mem_his_days,pre_days):
df.dropna(inplace=True)
df.sort_index(inplace=True)
df.drop(columns='ts_code',inplace=True)
# 将ask_open向前移动了pre_days天
df['label'] = df['ask_open'].shift(-pre_days)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
sca_X = scaler.fit_transform(df.iloc[:,:-1])
from collections import deque
deq = deque(maxlen=mem_his_days)
X = []
for i in sca_X:
deq.append(list(i))
if len(deq)==mem_his_days:
X.append(list(deq))
X_lately = X[-pre_days:]
X = X[:-pre_days]
y = df['label'].values[mem_his_days-1:-pre_days]
import numpy as np
X = np.array(X)
y = np.array(y)
return X,y,X_lately
训练模型
终于到我们熟悉的调参环节,我调了好一会儿,最终选定的是mem_days、Lstm层数、隐藏层数、隐层神经元个数分别是5、3、2、64,朋友们也可以自己取调一调
pre_days = 5
# mem_days = [5,10,15]
# lstm_layers = [1,2]
# dense_layers = [1,2,3]
# units = [16,32]
mem_days = [5]
lstm_layers = [3]
dense_layers = [2]
units = [64]
from tensorflow.keras.callbacks import ModelCheckpoint
for the_mem_days in mem_days:
for the_lstm_layers in lstm_layers:
for the_dense_layers in dense_layers:
for the_units in units:
filepath = './models_only_problem/val_mape:.2f_epoch:02d_'+f'men_the_mem_days_lstm_the_lstm_layers_dense_the_dense_layers_unit_the_units'
checkpoint = ModelCheckpoint(
filepath=filepath,
save_weights_only=False,
monitor='val_mape',
mode='min',
save_best_only=True)
X,y,X_lately = Stock_Price_LSTM_Data_Precesing(golden,the_mem_days,pre_days)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,shuffle=False,test_size=0.1)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
model = Sequential()
model.add(LSTM(the_units,input_shape=X.shape[1:],activation='relu',return_sequences=True))
model.add(Dropout(0.1))
for i in range(the_lstm_layers):
model.add(LSTM(the_units,activation='relu',return_sequences=True))
model.add(Dropout(0.1))
model.add(LSTM(the_units,activation='relu'))
model.add(Dropout(0.1))
for i in range(the_dense_layers):
model.add(Dense(the_units,activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(1))
model.compile(optimizer='adam',
loss='mse',
metrics=['mape'])
model.fit(X_train,y_train,batch_size=32,epochs=50,validation_data=(X_test,y_test),callbacks=[checkpoint])
模型会被保存在models_only_problem文件夹下,第一个数值表示的就是预测的精度,越小越好,后面跟的就是那些超参数的值,只要找到前面数值最小的那些超参数的值,固定这些超参数即可,我的mape数值最小是1.66
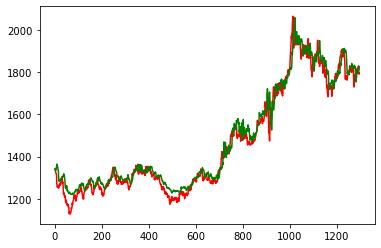
模型预测及查看效果
将刚才训练好的最好的模型拿下来,加载模型,把需要预测的数据扔进去
先看整体情况
from tensorflow.keras.models import load_model
import matplotlib.pyplot as plt
best_model = load_model('./models_only_problem/1.66_28_men_5_lstm_3_dense_2_unit_64')
pre = best_model.predict(X)
print(len(pre))
plt.plot(y,color='red',label='price')
plt.plot(pre,color='green',label='predict')
plt.show()
选取特定的一小段查看
x_time1 = y[200:300]
pre_time1 = pre[200:300]
plt.plot(x_time1,color='red',label='price')
plt.plot(pre_time1,color='green',label='predict')
plt.legend()
plt.show()

结果分析
从总体上看,LSTM的拟合效果还是不错的,可是在一个较短的时间内,预测数据竟然滞后于实际价格,这有可能带来投资的偏差,一种可行的办法就是,在数据中加入更多的属性,数据的质量决定了最终神经网络预测的质量
以上是关于价格预测方法的主要内容,如果未能解决你的问题,请参考以下文章
使用 RNN,我们如何预测货币价格以在给定时间段内达到特定价格?