k8s容器环境收集应用日志到已有的ELK日志平台
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s容器环境收集应用日志到已有的ELK日志平台相关的知识,希望对你有一定的参考价值。
Tags: k8s环境下的容器日志收集
K8S环境下面如何收集应用日志
===
在本文中重点讲一下K8S容器环境中如何收集容器的日志;
1. 容器日志收集方案的选择:
??在K8S集群中,容器的日志收集方案一般有三种;第一种方案是通过在每一个k8s节点安装日志收集客户端软件,比如fluentd。这种方案不好的一点是应用的日志必须输出到标准输出,并且是通过在每一台计算节点的/var/log/containers目录下面的日志文件,这个日志文件的名称是这种格式user-center-765885677f-j68zt_default_user-center-0867b9c2f8ede64cebeb359dd08a6b05f690d50427aa89f7498597db8944cccc.log,文件名称有很多随机字符串,很难和容器里面的应用对应起来。并且在网上看到别人说这个里面的日志,对于JAVA的报错内容没有多行合并,不过我还没有测试过此方案。
??第二种方案就是在应用的pods里面在运行一个sidecar container(边角容器),这个容器会和应用的容器挂载同一个volume日志卷。比如这个sidecar容器可以是filebeat或者flunetd等;这种方案不足之处是部署了sidecar , 所以会消耗资源 , 每个pod都要起一个日志收集容器。
??第三种方案就是直接将应用的日志收集到kafka,然后通过kafka再发送到logstash,再处理成json格式的日志发送到es集群,最后在kibana展示。我实验的就是这种方案。通过修改logsbak配置文件实现了日志直接发送到kafka缓存的功能;下面直接看配置了
1. logsbak配置:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<jmxConfigurator/> <!-- 动态加载-->
<property name="log-path" value="/apptestlogs" /> <!-- 统一 /applogs 下面 -->
<property name="app-name" value="test" /> <!-- 应用系统名称 -->
<property name="filename" value="test-test" /> <!---日志文件名,默认组件名称 -->
<property name="dev-group-name" value="test" /> <!-- 开发团队名称 -->
<conversionRule conversionWord="traceId" converterClass="org.lsqt.components.log.logback.TraceIdConvert"/>
<!-- 根据实际情况修改变量 end-->
-<appender name="consoleAppender" class="ch.qos.logback.core.ConsoleAppender">
<!-- 典型的日志pattern -->
<!-- -<encoder>-->
<!--<pattern>[%date{ISO8601}] [%level] %logger{80} [%thread] [%traceId] ${dev-group-name} ${app-name} Line:%-3L - %msg%n</pattern>-->
<!--</encoder>-->
-<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>[%date{ISO8601}] [%level] %logger{80} [%thread] [%tid] ${dev-group-name} ${app-name} Line:%-3L - %msg%n</pattern>
</layout>
</encoder>
</appender>
-<appender name="fileAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log-path}/${app-name}/${filename}.log</file>
-<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/${log-path}/${app-name}/${filename}.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxHistory>15</maxHistory>
<!--用来指定日志文件的上限大小,例如设置为300M的话,那么到了这个值,就会删除旧的日志。-->
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>300MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<!-- -<encoder>-->
<!--<pattern>[%date{ISO8601}] [%level] %logger{80} [%thread] [%traceId] ${dev-group-name} ${app-name} Line:%-3L - %msg%n</pattern>-->
<!--</encoder>-->
-<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>[%date{ISO8601}] [%level] %logger{80} [%thread] [%tid] ${dev-group-name} ${app-name} Line:%-3L - %msg%n</pattern>
</layout>
</encoder>
</appender>
<appender name="errorAppender" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log-path}/${app-name}/${filename}-error.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/${log-path}/${app-name}/${filename}-error.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>300MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<maxHistory>15</maxHistory>
</rollingPolicy>
<!--<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">-->
<!--<pattern>[%date{ISO8601}] [%level] %logger{80} [%thread] [%traceId] ${dev-group-name} ${app-name} Line:%-3L - %msg%n</pattern>-->
<!--</encoder>-->
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>[%date{ISO8601}] [%level] %logger{80} [%thread] [%tid] ${dev-group-name} ${app-name} Line:%-3L - %msg%n</pattern>
</layout>
</encoder>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- This example configuration is probably most unreliable under
failure conditions but wont block your application at all -->
<appender name="very-relaxed-and-fast-kafka-appender" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>[%date{ISO8601}] [%level] %logger{80} [%thread] [%tid] ${dev-group-name} ${app-name} Line:%-3L - %msg%n</pattern>
</encoder>
<topic>elk-stand-sit-fkp-eureka</topic>
<!-- we don‘t care how the log messages will be partitioned -->
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.NoKeyKeyingStrategy" />
<!-- use async delivery. the application threads are not blocked by logging -->
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy" />
<!-- each <producerConfig> translates to regular kafka-client config (format: key=value) -->
<!-- producer configs are documented here: https://kafka.apache.org/documentation.html#newproducerconfigs -->
<!-- bootstrap.servers is the only mandatory producerConfig -->
<producerConfig>bootstrap.servers=192.168.1.12:9092,192.168.1.14:9092,192.168.1.15:9092</producerConfig>
<!-- don‘t wait for a broker to ack the reception of a batch. -->
<producerConfig>acks=0</producerConfig>
<!-- wait up to 1000ms and collect log messages before sending them as a batch -->
<producerConfig>linger.ms=1000</producerConfig>
<!-- even if the producer buffer runs full, do not block the application but start to drop messages -->
<producerConfig>max.block.ms=0</producerConfig>
<!-- define a client-id that you use to identify yourself against the kafka broker -->
<producerConfig>client.id=${HOSTNAME}-${CONTEXT_NAME}-logback-relaxed</producerConfig>
<!-- define All log messages that cannot be delivered fast enough will then immediately go to the fallback appenders -->
<producerConfig>block.on.buffer.full=false</producerConfig>
<!-- this is the fallback appender if kafka is not available. -->
<appender-ref ref="consoleAppender" />
</appender>
<root level="debug">
<appender-ref ref="very-relaxed-and-fast-kafka-appender" />
<appender-ref ref="fileAppender"/>
<appender-ref ref="consoleAppender"/>
<appender-ref ref="errorAppender"/>
</root>
</configuration>###2. 针对logsbak配置说明:###
- logsbak直接发送日志到kafka有几种方式,一种是异步模式,一种是同步模式。异步模式的意思就是如果kafka因为网络情况出现故障,则阻塞发送日志或者直接将日志发送到后备存储,比如后备存储是发送到日志文件;同步模式的意思就是即使kafka出现网络情况不可达,则就会影响到日志线程,进而影响到应用的性能。不过这个模式的我没有测试过;配置如下:
<!-- This example configuration is more restrictive and will try to ensure that every message
is eventually delivered in an ordered fashion (as long the logging application stays alive) -->
<appender name="very-restrictive-kafka-appender" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
<topic>important-logs</topic>
<!-- ensure that every message sent by the executing host is partitioned to the same partition strategy -->
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.HostNameKeyingStrategy" />
<!-- block the logging application thread if the kafka appender cannot keep up with sending the log messages -->
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.BlockingDeliveryStrategy">
<!-- wait indefinitely until the kafka producer was able to send the message -->
<timeout>0</timeout>
</deliveryStrategy>
<!-- each <producerConfig> translates to regular kafka-client config (format: key=value) -->
<!-- producer configs are documented here: https://kafka.apache.org/documentation.html#newproducerconfigs -->
<!-- bootstrap.servers is the only mandatory producerConfig -->
<producerConfig>bootstrap.servers=localhost:9092</producerConfig>
<!-- restrict the size of the buffered batches to 8MB (default is 32MB) -->
<producerConfig>buffer.memory=8388608</producerConfig>
<!-- If the kafka broker is not online when we try to log, just block until it becomes available -->
<producerConfig>metadata.fetch.timeout.ms=99999999999</producerConfig>
<!-- define a client-id that you use to identify yourself against the kafka broker -->
<producerConfig>client.id=${HOSTNAME}-${CONTEXT_NAME}-logback-restrictive</producerConfig>
<!-- use gzip to compress each batch of log messages. valid values: none, gzip, snappy -->
<producerConfig>compression.type=gzip</producerConfig>
<!-- Log every log message that could not be sent to kafka to STDERR -->
<appender-ref ref="STDERR"/>
</appender> 通过配置logsbak直接输出到kafka,并且使用异步模式,就成功的在kibana里面看到了容器的日志了; 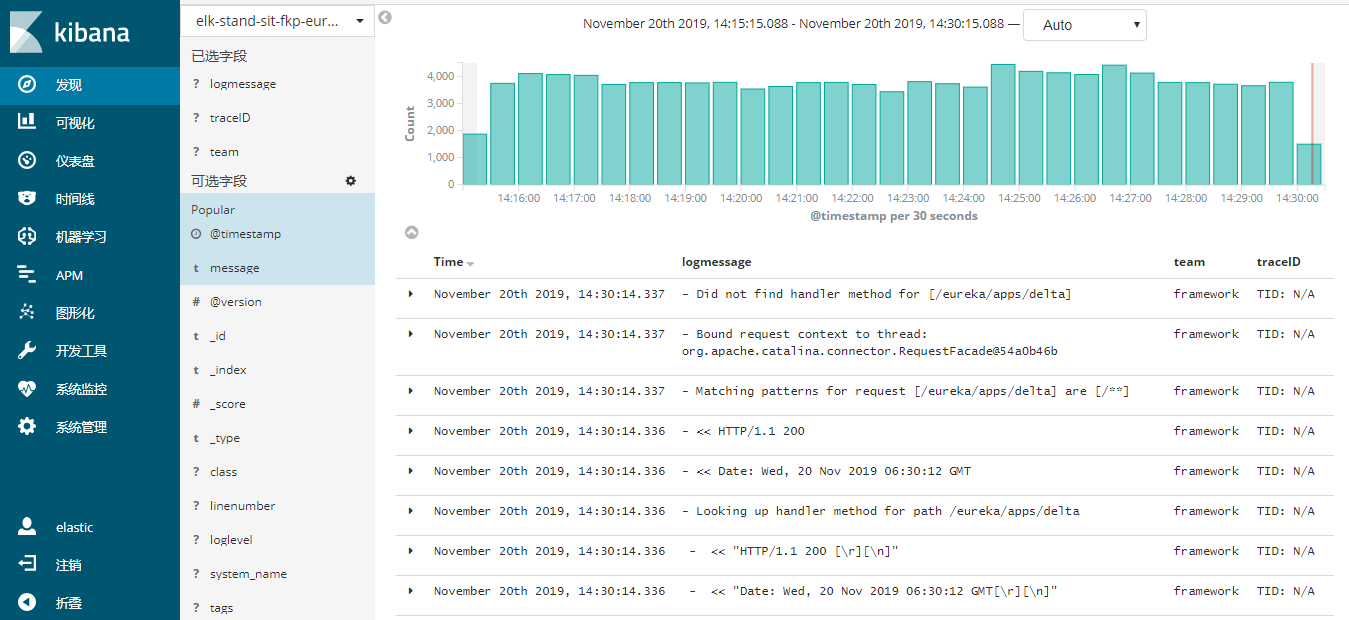
博文的更详细内容请关注我的个人微信公众号 “云时代IT运维”,本公众号旨在共享互联网运维新技术,新趋势; 包括IT运维行业的咨询,运维技术文档分享。重点关注devops、jenkins、zabbix监控、kubernetes、ELK、各种中间件的使用,比如redis、MQ等;shell和python等运维编程语言;本人从事IT运维相关的工作有十多年。2008年开始专职从事Linux/Unix系统运维工作;对运维相关技术有一定程度的理解。本公众号所有博文均是我的实际工作经验总结,基本都是原创博文。我很乐意将我积累的经验、心得、技术与大家分享交流!希望和大家在IT运维职业道路上一起成长和进步;

以上是关于k8s容器环境收集应用日志到已有的ELK日志平台的主要内容,如果未能解决你的问题,请参考以下文章