ELK 构建 MySQL 慢日志收集平台
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK 构建 MySQL 慢日志收集平台相关的知识,希望对你有一定的参考价值。
参考技术A 本文讲解如何通过一套开源日志存储和检索系统 ELK 构建 mysql 慢日志收集及分析平台。ELK、EFK 简介
想必你对 ELK、EFK 都不陌生,它们有一个共同的组件:Elasticsearch(简称ES),它是一个实时的全文搜索和分析引擎,可以提供日志数据的收集、分析、存储 3 大功能。另外一个组件 Kibana 是这套检索系统中的 Web 图形化界面系统,可视化展示在 Elasticsearch 的日志数据和结果。
ELF/EFK 工具集中还有 l 和 F 这两个名称的缩写,这两个缩写代表的工具根据不同的架构和使用方式而定。
L 通常是 Logstash 组件,它是一个用来搜集、分析、过滤日志的工具 。
F 代表 Beats 工具(它是一个轻量级的日志采集器),Beats 家族有 6 个成员,Filebeat 工具,它是一个用于在客户端收集日志的轻量级管理工具。
F 也可以代表工具 fluentd,它是这套架构里面常用的日志收集、处理转发的工具。
那么它们(Logstash VS Beats VS fluentd)有什么样的区别呢?Beats 里面是一个工具集,其中包含了 Filebeat 这样一个针对性的日志收集工具。Logstash 除了做日志的收集以外,还可以提供分析和过滤功能,所以它的功能会更加的强大。
Beats 和 fluentd 有一个共同的特点,就是轻量级,没有 Logstash 功能全面。但如果比较注重日志收集性能,Beats 里面的 Filebeat 和 fluentd 这两个工具会更有优势。
Kafka 是 ELK 和 EFK 里面一个附加的关键组件(缩写 K),它主要是在支持高并发的日志收集系统里面提供分布式的消息队列服务。
ELK 的优势
在此之前,先介绍 ELK 日志分析会有一些什么样的优势?主要有 3 点:
1、它是一套开源、完整的日志检索分析系统,包含收集、存储、分析、检索工具。我们不需要去开发一些额外的组件去完成这套功能,因为它默认的开源方式就提供了一整套组件,只要组合起来,就可以完成从日志收集、检索、存储、到整个展示的完整解决方案了。
2、支持可视化的数据浏览。运维人员只要在控制台里选择想关注的某一段时间内的数据,就可以查看相应的报表,非常快捷和方便。
3、它能广泛的支持一些架构平台,比如我们现在讲到的 K8s 或者是云原生的微服务架构。
Kafka 作为日志消息队列,客户端通过 Filebeat 收集数据(日志)后将其先存入 Kafka,然后由 Logstash 提取并消费,这套架构的好处是:当我们有海量日志同步情况下,直接存入服务端 ES 很难直接应承接海量流量,所以 Kafka 会进行临时性的存取和缓冲,再由 Logstash 进行提取、过滤,通过 Logstash 以后,再把满足条件的日志数据存入 ES。
ES 不再是以单实例的方部署,而是采用集群架构,考虑 Kafka 的集群模式, Logstash 也使用集群模式。
我们会看到这套架构稍微庞大,大中型的企业往往存储海量数据(上百 T 或 P 级)运维日志、或者是系统日志、业务日志。
完成ELK服务搭建后,首先我需要开启的是 MySQL 的慢查询配置,那么通过 set global slow_query_log=‘ON‘,这样就可以开启慢查询日志,还需要设置好慢查询日志标准是大于 1 秒的,那么同样是 set global long_query_time 大于或等于 1,它的意思是大于 1 秒的查询语句,才会认为是慢查询,并且做日志的记录。
那么另外还要设置慢查询日志的位置,通过 set global slow_query_log = 日志文件路径,这里设置到 filebeat 配置监听的路径下,就完成了慢查询日志的路径设置。
配置完成以后,需要在 MySQL 终端上,模拟执行一条执行时间较长的语句,比如执行 select sleep(5),这样就会模拟执行一条查询语句,并且会让它休眠 5 秒。接下来我们看到服务端窗口的 MySQL 这条 sleep 语句已经执行完毕了,同时我们可以再打开 filebeat 的推送窗口,发现这里产生了一条推送日志,表示成功地把这条日志推送给了 ES。
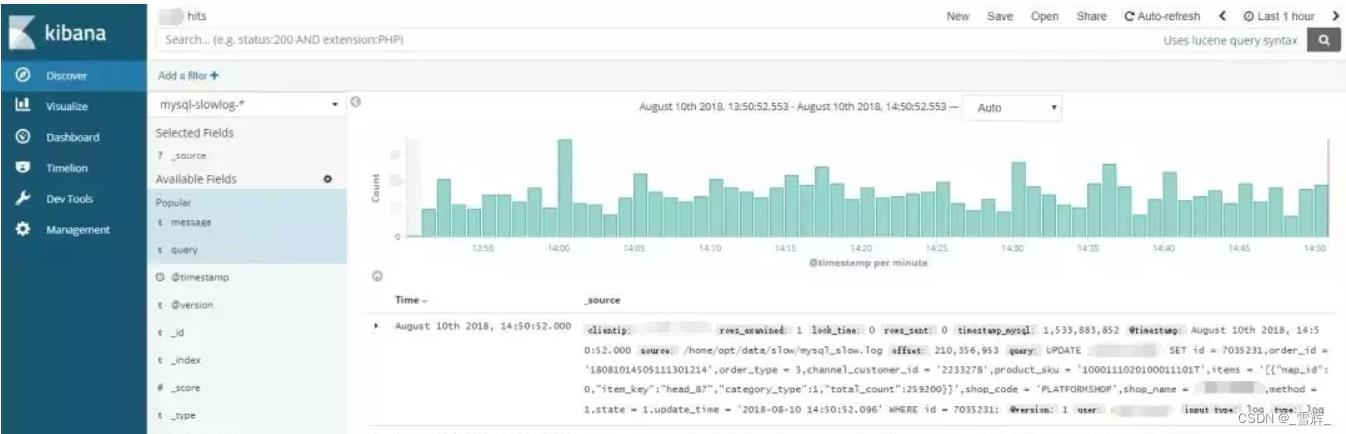
那么接下来我们就可以通过浏览器打开 Kibana 的管理后台,从界面里来看一看检索日志的记录和一些可视化展示的图表,我们可以点击界面上的 Discover 按钮,同时选择好对应的时间周期,然后可以增加一个 filter 过滤器,过滤器里面敲入对应的关键字来进行索引。
这里我敲入的是 slow.query 这个关键字,就会匹配出对应的可以检索的项目,点击想要查询的对应项目,展示出想检索的某一个时间周期内对应的一些日志记录,以及它的图表是什么样子的,同时在下方会有对应的 MySQL 的日志信息打印出来,通过 Kibana 这样的可视化界面就能够看到的相关信息了。
ELK采集MySQL慢日志实现
文章目录
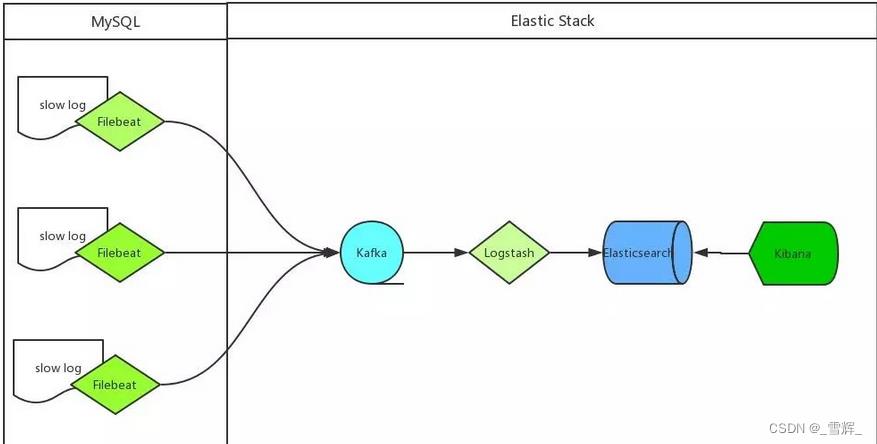
一、ELK采集MySQL慢日志架构
- MySQL 服务器安装 Filebeat 作为 agent 收集 slowLog
- Filebeat 读取 MySQL 慢日志文件做简单过滤传给 Kafka 集群
- Logstash 读取 Kafka 集群数据并按字段拆分后转成 JSON 格式存入 ES 集群
- Kibana 读取ES集群数据展示到web页面上
二、filebeat
使用filebeat实时采集mysql慢日志推送到kafka中
filebeat.inputs:
#slowlog
- type: log
enabled: true
paths:
- /data/mysql_tmp/slow.log
fields_under_root: true
fields:
clustername: test
type: mysql_slowlog
log_topic: mysql-slowlog
close_inactive: 5m
scan_frequency: 1m
tail_files: true
multiline:
pattern: "^# Time: "
negate: true
match: after
output.kafka:
version: x.x.x.x
hosts: ["xxx:9092","xxx:9092"]
topic: "%[log_topic]"
partition.round_robin:
reachable_only: false
worker: 1
required_acks: 1
compression: gzip
max_message_bytes: 10485760
keep_alive: 10s
client_id: "filebeat"
max_procs: 1
三、logstash
使用logstash将kakfa中的message,拆分后转成 JSON 格式存入 ES 集群
input
kafka
bootstrap_servers => "xxx:9092"
topics => "mysql-slowlog"
filter
grok
# 有ID有use
match => [ "message", "^#\\s+User@Host:\\s+%USER:user\\[[^\\]]+\\]\\s+@\\s+(?:(?<clienthost>\\S*) )?\\[(?:%IP:clientip)?\\]\\s+Id:\\s+%NUMBER:id\\n# Query_time: %NUMBER:query_time\\s+Lock_time: %NUMBER:lock_time\\s+Rows_sent: %NUMBER:rows_sent\\s+Rows_examined: %NUMBER:rows_examined\\nuse\\s(?<dbname>\\w+);\\nSET\\s+timestamp=%NUMBER:timestamp_mysql;\\n(?<query>[\\s\\S]*)" ]
# 有ID无use
match => [ "message", "^#\\s+User@Host:\\s+%USER:user\\[[^\\]]+\\]\\s+@\\s+(?:(?<clienthost>\\S*) )?\\[(?:%IP:clientip)?\\]\\s+Id:\\s+%NUMBER:id\\n# Query_time: %NUMBER:query_time\\s+Lock_time: %NUMBER:lock_time\\s+Rows_sent: %NUMBER:rows_sent\\s+Rows_examined: %NUMBER:rows_examined\\nSET\\s+timestamp=%NUMBER:timestamp_mysql;\\n(?<query>[\\s\\S]*)" ]
# 无ID有use
match => [ "message", "^#\\s+User@Host:\\s+%USER:user\\[[^\\]]+\\]\\s+@\\s+(?:(?<clienthost>\\S*) )?\\[(?:%IP:clientip)?\\]\\n# Query_time: %NUMBER:query_time\\s+Lock_time: %NUMBER:lock_time\\s+Rows_sent: %NUMBER:rows_sent\\s+Rows_examined: %NUMBER:rows_examined\\nuse\\s(?<dbname>\\w+);\\nSET\\s+timestamp=%NUMBER:timestamp_mysql;\\n(?<query>[\\s\\S]*)" ]
# 无ID无use
match => [ "message", "^#\\s+User@Host:\\s+%USER:user\\[[^\\]]+\\]\\s+@\\s+(?:(?<clienthost>\\S*) )?\\[(?:%IP:clientip)?\\]\\n# Query_time: %NUMBER:query_time\\s+Lock_time: %NUMBER:lock_time\\s+Rows_sent: %NUMBER:rows_sent\\s+Rows_examined: %NUMBER:rows_examined\\nSET\\s+timestamp=%NUMBER:timestamp_mysql;\\n(?<query>[\\s\\S]*)" ]
date
match => ["timestamp_mysql","UNIX"]
target => "@timestamp"
mutate
remove_field => ["@version","message","timestamp_mysql"]
output
elasticsearch
hosts => ["xxx.xxx.xxx.xxx:9200""]
index => "%type-%+YYYY.MM.dd"
四、es+kibana
读取Kibana 读取ES集群数据展示到web页面上
es中mysql慢日志索引模板
"order": 0,
"template": "mysqld-slow-*",
"settings":
"index":
"refresh_interval": "5s"
,
"mappings":
"mysqld-slow":
"numeric_detection": true,
"properties":
"@timestamp":
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
,
"@version":
"type": "string"
,
"query_time":
"type": "double"
,
"row_sent":
"type": "string"
,
"rows_examined":
"type": "string"
,
"clientip":
"type": "string"
,
"clienthost":
"type": "string"
,
"id":
"type": "integer"
,
"lock_time":
"type": "string"
,
"dbname":
"type": "keyword"
,
"user":
"type": "keyword"
,
"query":
"type": "string",
"index": "not_analyzed"
,
"tags":
"type": "string"
,
"timestamp":
"type": "string"
,
"type":
"type": "string"
,
"aliases":
以上是关于ELK 构建 MySQL 慢日志收集平台的主要内容,如果未能解决你的问题,请参考以下文章