机器学习 - 算法 - 聚类 K-MEANS 算法
Posted shijieli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习 - 算法 - 聚类 K-MEANS 算法相关的知识,希望对你有一定的参考价值。
聚类算法
概述
无监督问题 手中无标签
聚类 将相似的东西分到一组
难点 如何 评估, 如何 调参
基本概念
要得到的簇的个数 - 需要指定 K 值
质心 - 均值, 即向量各维度取平均
距离的度量 - 常用 欧几里得距离 和 余弦线相似度 ( 先标准化 )
优化目标 - ![]()
需求每个簇中的点, 到质心的距离尽可能的加和最小, 从而得到最优
K - MEANS 算法
工作流程
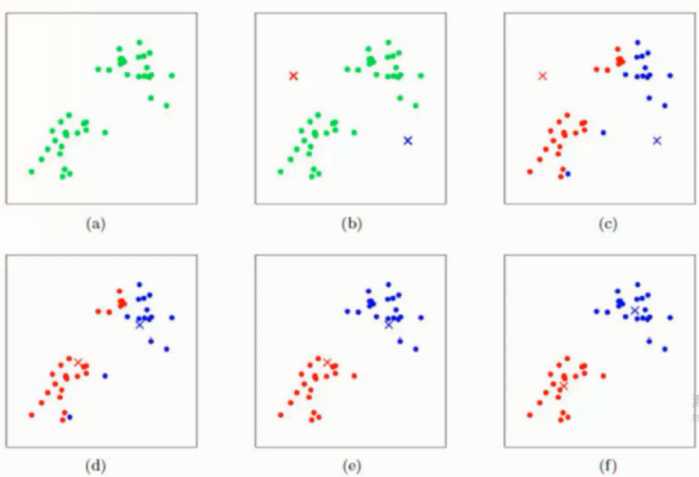
- (a) 初始图
- (b) 在指定了 K 值之后, 会在图中初始化两个点 红点, 蓝点( 随机质心 ) 这里 K 指定为 2
- (c) 然后对图中的每一个点计算是分别到红点以及蓝点的距离, 谁短就算谁的
- (d) 重新将红色蓝色区域计算质心
- (e) 根据重新计算的质心, 再次遍历所有点计算到两个新质点的距离对比划分
- (f) 按照之前的套路再次更新质点
就这样不断的更新下去, 直到所有的样本点都不再发生变化的时候则表示划分成功
优势
简单快速, 适合常规数据集
劣势
K 值难以决定
复杂度与样本呈线性关系
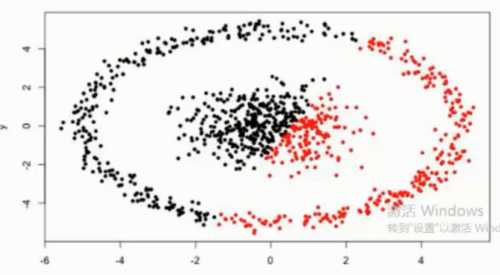
很难发现任意形状的簇 , 如下图
以上是关于机器学习 - 算法 - 聚类 K-MEANS 算法的主要内容,如果未能解决你的问题,请参考以下文章