hive 存储格式对比
Posted hello-wei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive 存储格式对比相关的知识,希望对你有一定的参考价值。
Apache Hive支持Apache Hadoop中使用的几种熟悉的文件格式,如TextFile,RCFile,SequenceFile,AVRO,ORC和Parquet格式。
Cloudera Impala也支持这些文件格式。 在建表时使用STORED AS (TextFile|RCFile|SequenceFile|AVRO|ORC|Parquet)来指定存储格式。
TextFile每一行都是一条记录,每行都以换行符( n)结尾。数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
RCFile是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
AVRO是开源项目,为Hadoop提供数据序列化和数据交换服务。您可以在Hadoop生态系统和以任何编程语言编写的程序之间交换数据。Avro是基于大数据Hadoop的应用程序中流行的文件格式之一。
ORC文件代表了优化排柱状的文件格式。ORC文件格式提供了一种将数据存储在Hive表中的高效方法。这个文件系统实际上是为了克服其他Hive文件格式的限制而设计的。Hive从大型表读取,写入和处理数据时,使用ORC文件可以提高性能。
Parquet是一个面向列的二进制文件格式。Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列的查询,Parquet特别有用。Parquet桌子使用压缩Snappy,gzip;目前Snappy默认。
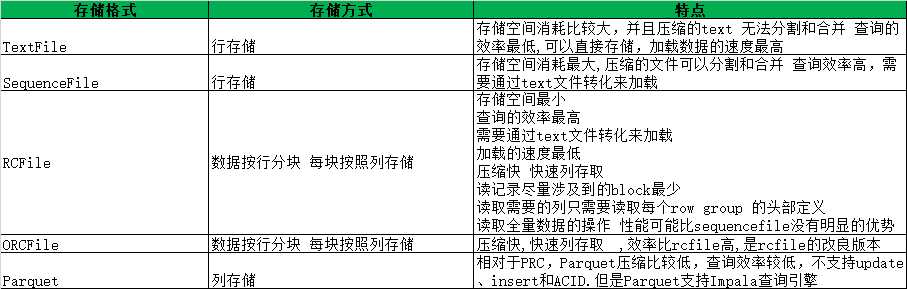
存储格式对比
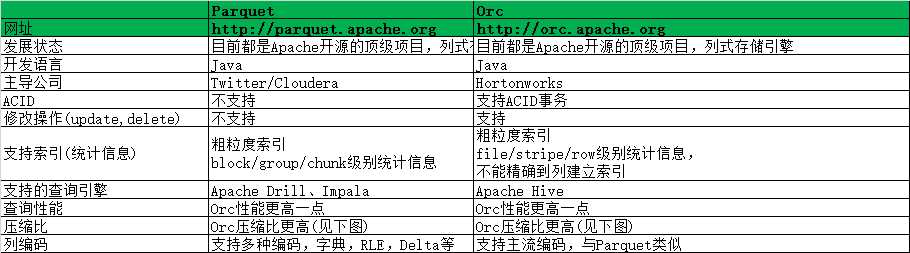
Parquet与ORC对比
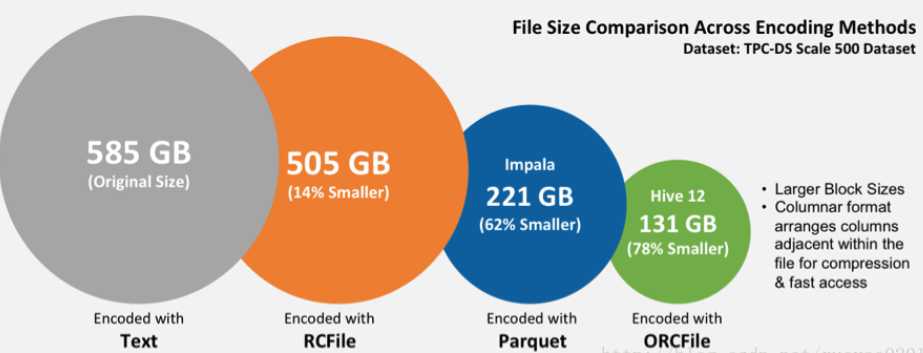
总结:如果仅仅是在HIve中存储和查询,建议使用ORC格式,如果在Hive中存储,而使用Impala查询,建议使用Parquet
以上是关于hive 存储格式对比的主要内容,如果未能解决你的问题,请参考以下文章