Hive:第 9 章 压缩和存储
Posted 亿钱君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive:第 9 章 压缩和存储相关的知识,希望对你有一定的参考价值。
压缩和存储
1. Hadoop 压缩配置
1.1 MR 支持的压缩编码
2. 开启 Map 输出阶段压缩(MR 引擎)
开启 map 输出阶段压缩可以减少 job 中 map 和 Reduce task 间数据传输量。具体配置如下
(1)开启 hive 中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
(2)开启 mapreduce 中 map 输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
(3)设置 mapreduce 中 map 输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
(4)执行查询语句
select count(id) from student;

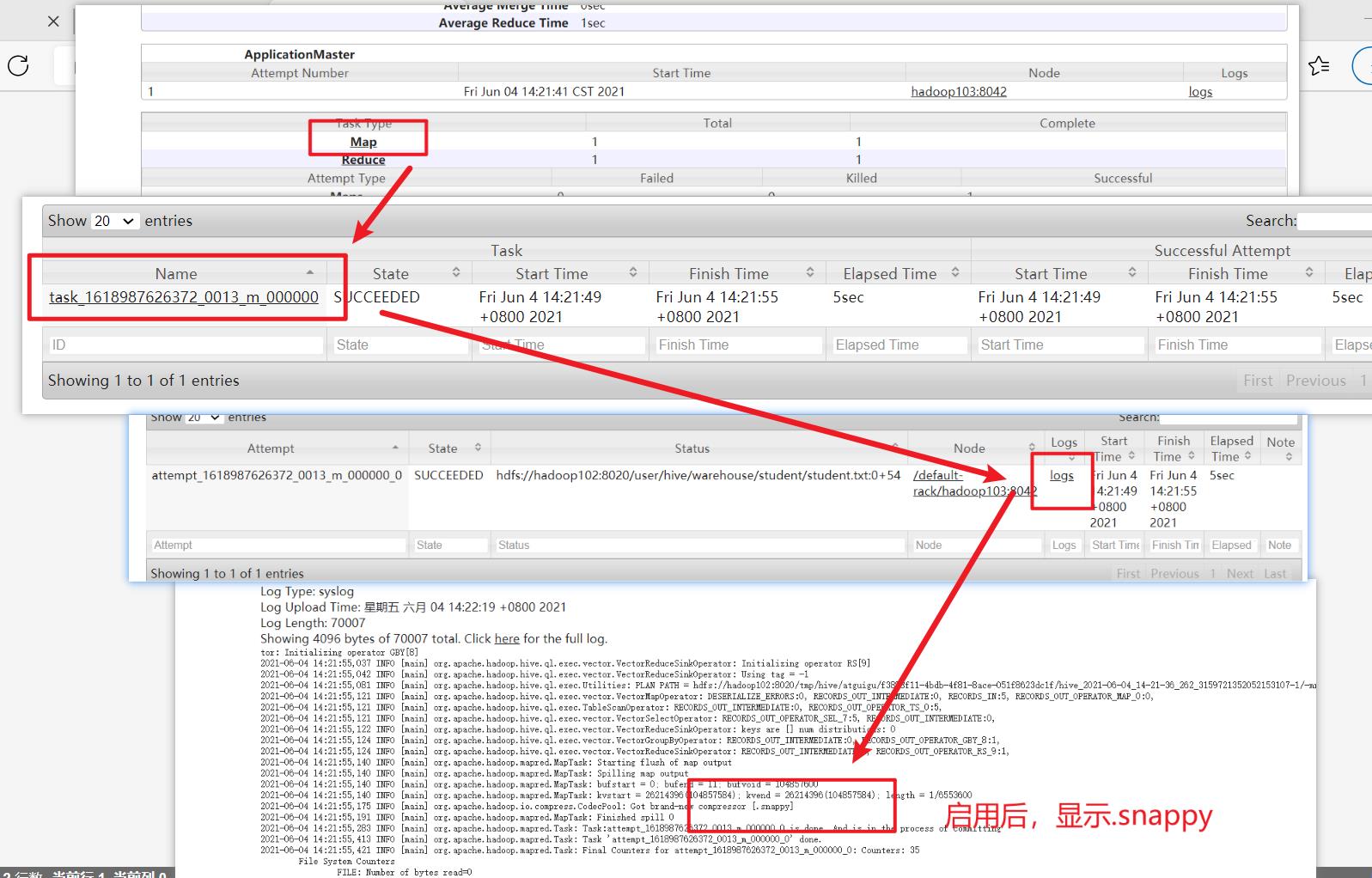
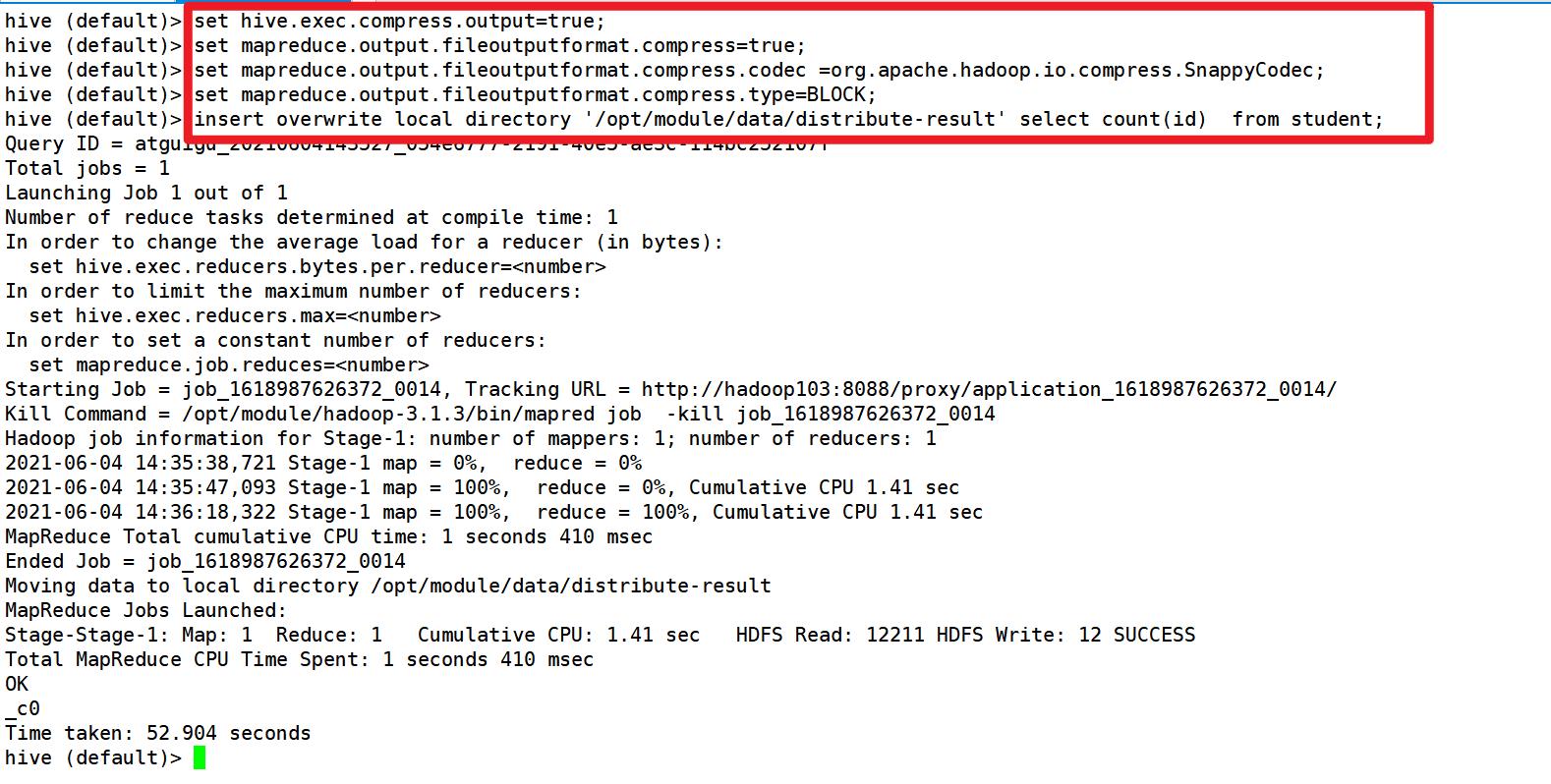
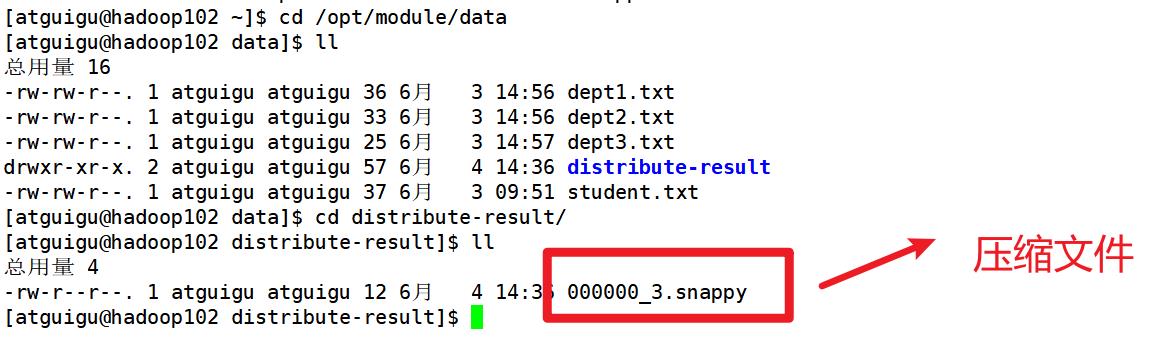
3. 开启 Reduce 输出阶段压缩
当 Hive 将 输 出 写 入 到 表 中 时 , 输出内容同样可以进行压缩

测试:
4. 文件存储格式
Hive 支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
- TEXTFILE 、SEQUENCEFILE:基于行存
- ORC、PARQUET:基于列存
4.1 列式存储和行式存储
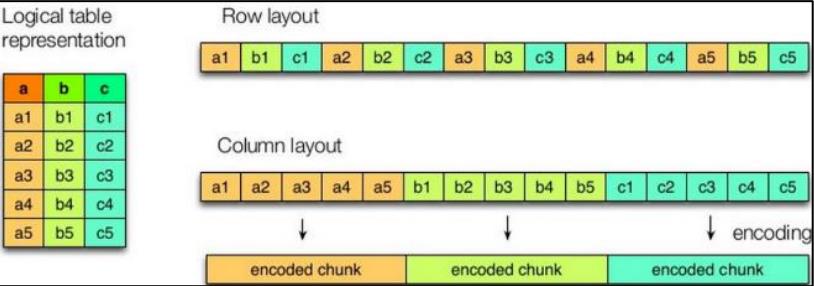
如图所示左边为逻辑表,右边第一个为行式存储,第二个为列式存储

4.2 TextFile 格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合 Gzip、Bzip2 使用,但使用 Gzip 这种方式,hive 不会对数据进行切分,从而无法对数据进行并行操作。
4.3 Orc 格式
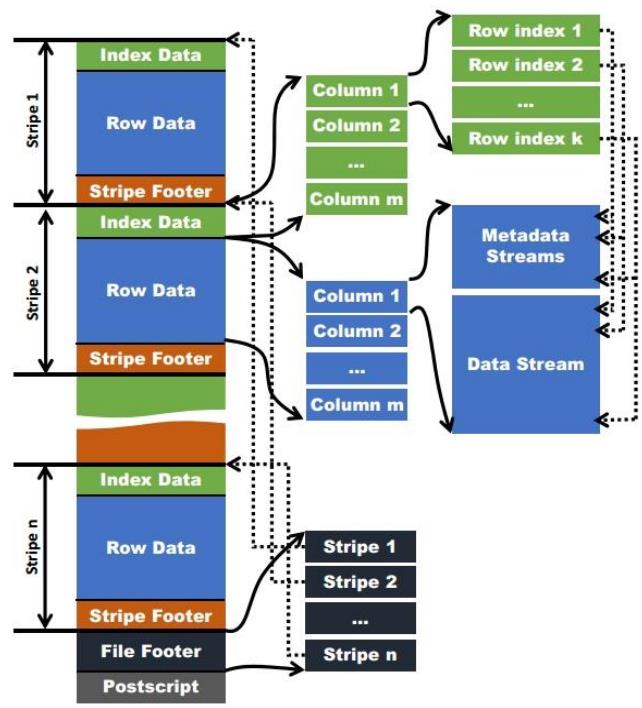
把一个文件分成多段,每一段数据(部分行)按列进行存储,并对每个
列进行了编码,以便快速查询
4.4 Parquet 格式
Parquet 文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此 Parquet 格式文件是自解析的
4.5 主流文件存储格式对比实验(常用ORC)
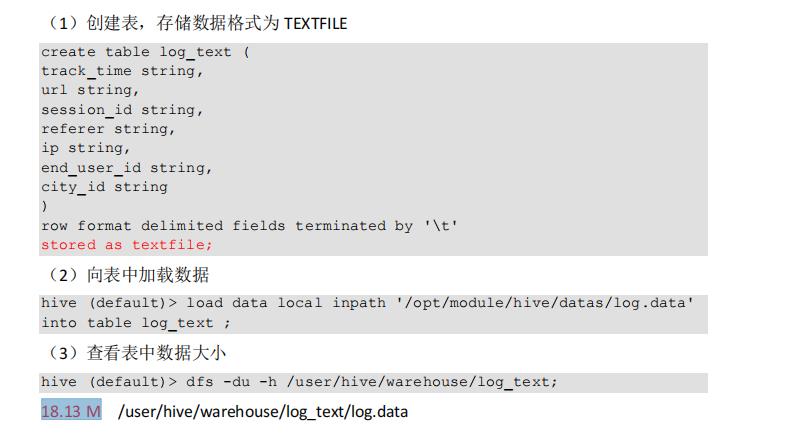
1)测试数据

2)TextFile:18.13 M
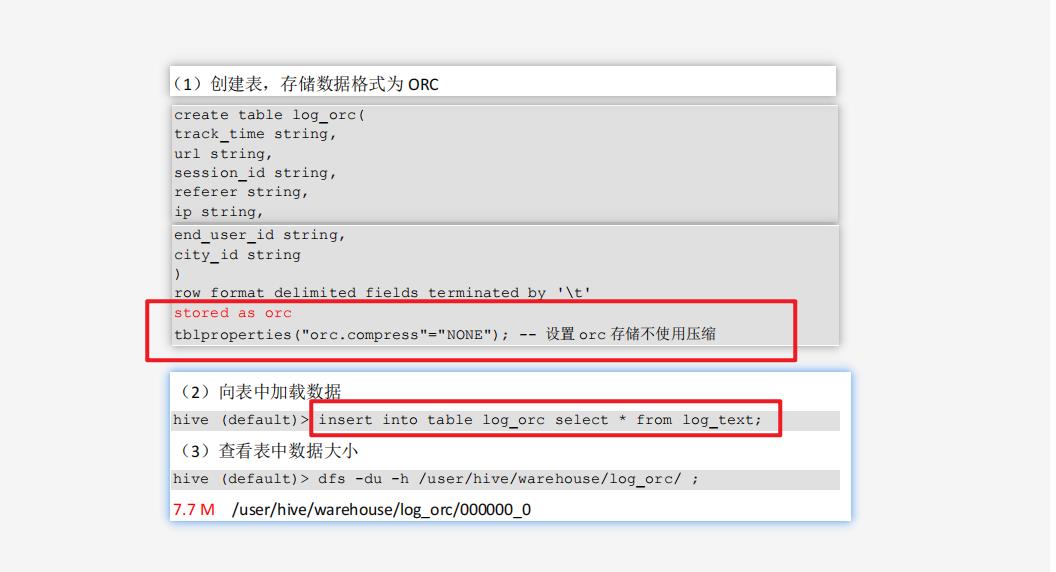
3)ORC:7.7 M
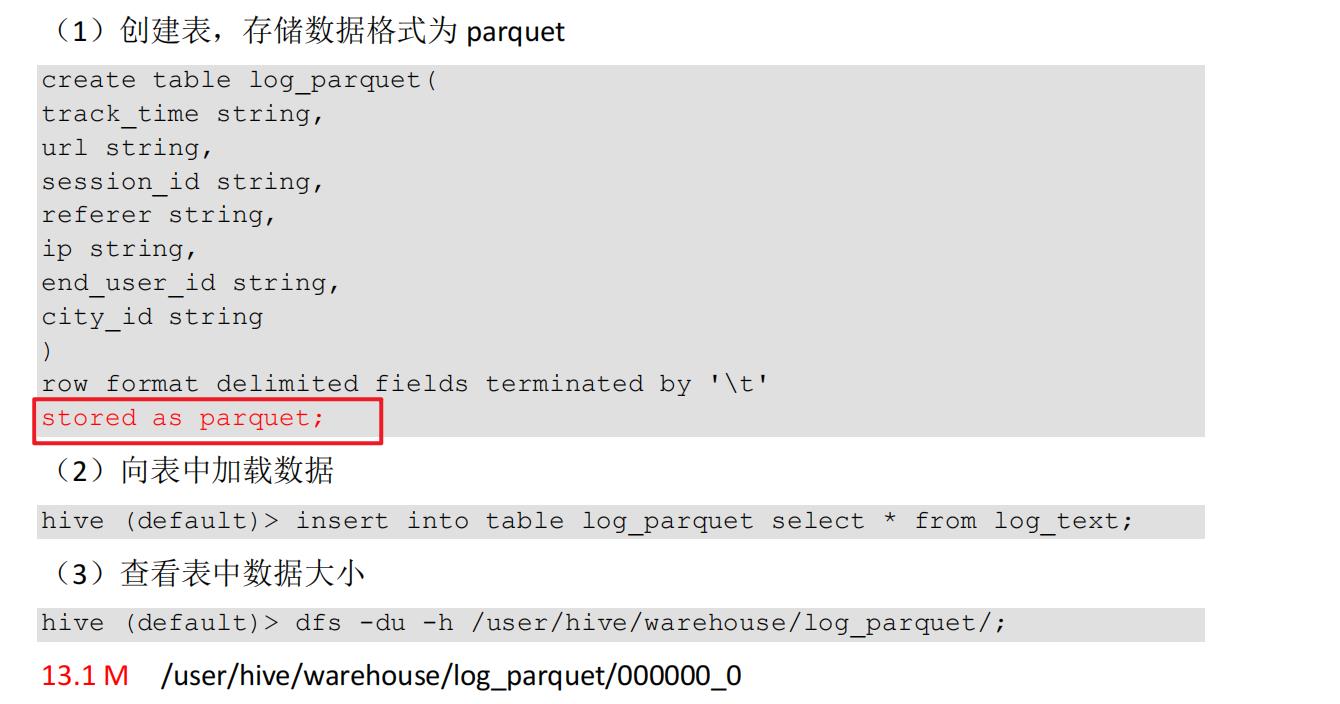
4)Parquet:13.1 M
存储文件的对比总结:

存储文件的查询速度测试:

5. 存储和压缩结合
1)创建一个 ZLIB 压缩的 ORC 存储方式:2.78 M
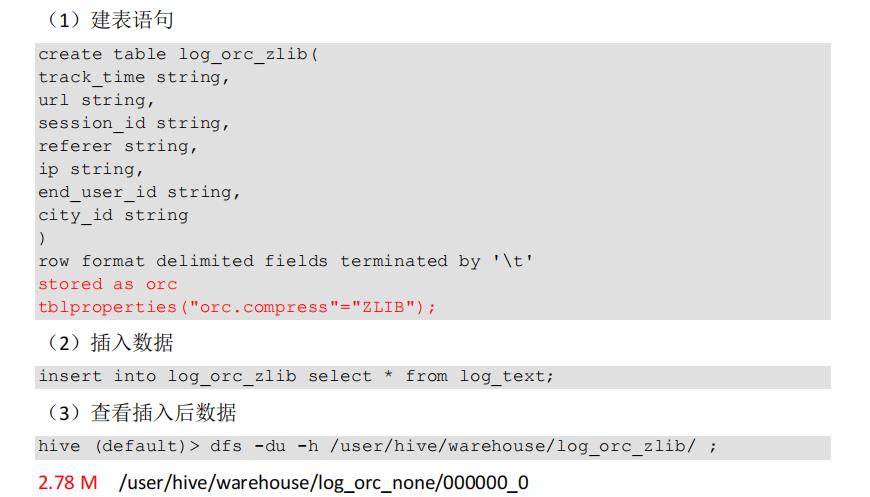
2)创建一个 SNAPPY 压缩的 ORC 存储方式:3.75 M
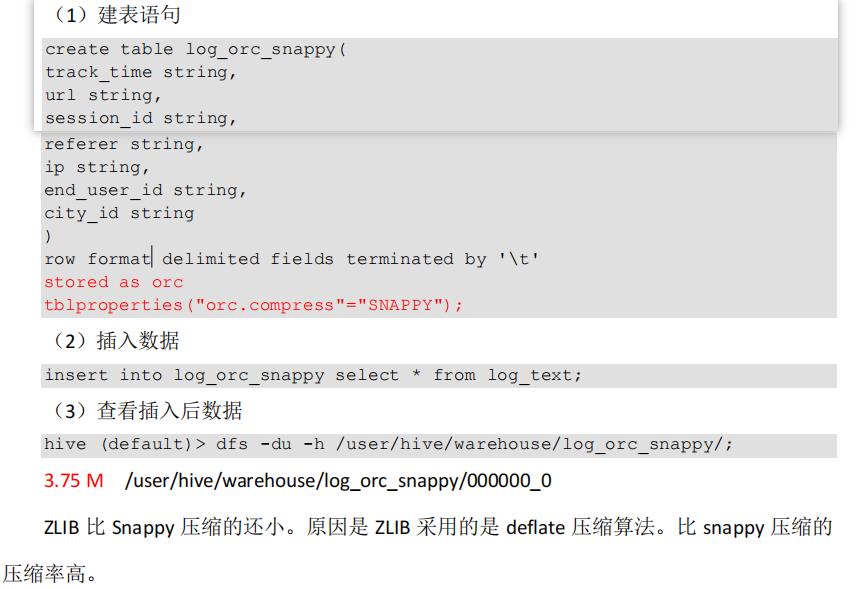
3)创建一个 SNAPPY 压缩的 parquet 存储方式:6.39 MB
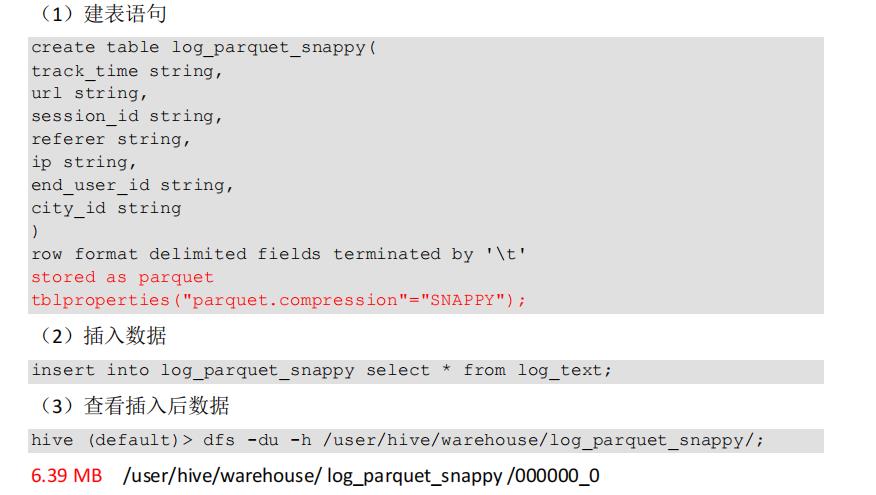
4)存储方式和压缩总结
在实际的项目开发当中,hive 表的数据存储格式一般选择:orc 或 parquet。压缩方式一般选择 snappy,lzo。
以上是关于Hive:第 9 章 压缩和存储的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之_08_Hive学习_04_压缩和存储(Hive高级)+ 企业级调优(Hive优化)
打怪升级之小白的大数据之旅(六十八)<Hive旅程第九站:Hive的压缩与存储>