smooth l1 loss & l1 loss & l2 loss
Posted lyp1010
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了smooth l1 loss & l1 loss & l2 loss相关的知识,希望对你有一定的参考价值。
引自:https://www.zhihu.com/question/58200555/answer/621174180
为了从两个方面限制梯度:
- 当预测框与 ground truth 差别过大时,梯度值不至于过大;
- 当预测框与 ground truth 差别很小时,梯度值足够小。
考察如下几种损失函数,其中 为预测框与 groud truth 之间 elementwise 的差异:

观察 (4),当 x 增大时 L2 损失对 x 的导数也增大。这就导致训练初期,预测值与 groud truth 差异过于大时,损失函数对预测值的梯度十分大,训练不稳定。
根据方程 (5),L1 对 x 的导数为常数。这就导致训练后期,预测值与 ground truth 差异很小时, L1 损失对预测值的导数的绝对值仍然为 1,而 learning rate 如果不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高精度。
最后观察 (6),smooth L1 在 x 较小时,对 x 的梯度也会变小,而在 x 很大时,对 x 的梯度的绝对值达到上限 1,也不会太大以至于破坏网络参数。 smooth L1 完美地避开了 L1 和 L2 损失的缺陷。其函数图像如下:
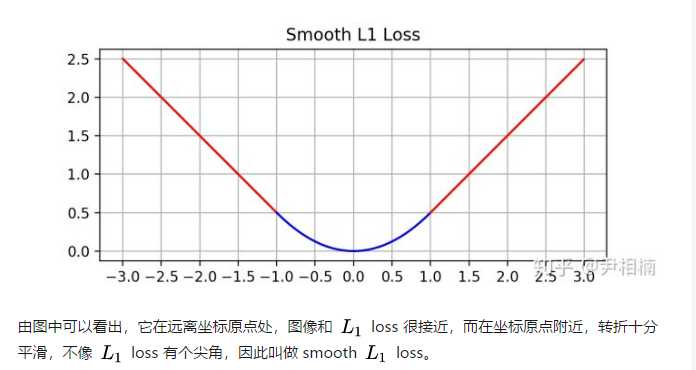
综上所述smootn l1 loss 综合了l1 loss 和l2 loss的优点。
以上是关于smooth l1 loss & l1 loss & l2 loss的主要内容,如果未能解决你的问题,请参考以下文章
目标检测中回归损失函数(L1Loss,L2Loss,Smooth L1Loss,IOU,GIOU,DIOU,CIOU,EIOU,αIOU ,SIOU)
目标检测网络中的定位损失函数对比:IOUGIOUCIOUDIOUL1L2Smooth L1
Pytorch常用损失函数nn.BCEloss();nn.BCEWithLogitsLoss();nn.CrossEntropyLoss();nn.L1Loss(); nn.MSELoss();(代码