sklearn中SVM一对一多分类参数的研究
Posted ruidongwu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sklearn中SVM一对一多分类参数的研究相关的知识,希望对你有一定的参考价值。
1、引言
最近在学习sklearn库中SVM算法中C-SVC多分类的相关应用,但是在sklearn中关于如何提取训练后的参数,并脱离原有的sklearn库,甚至脱离原有的python开发环境,在新的平台和系统中使用训练后的参数完成前向推理,是本文所需要讲述的内容。由于笔者主要从事于嵌入式平台(包括但不限于ARM、FPGA,目前主要是异构平台)中机器学习算法的相关应用与加速设计,所以需要对于算法的每一个步骤和细节都具有深刻的了解。而目前从网上查阅到的相关资料对于sklearn多分类的解释不够清晰,综合查阅到的中文资料和英文资料,在此处做一个详细的说明。
2、sklearn多分类示例
首先以二维平面内通过聚类生成四组数据,分别隶属于四个不同的类别,对应的代码如下所示,最终生成目标图像如图1所示。
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn import svm 4 from sklearn.datasets import make_blobs 5 6 n_samples = [10, 10, 10, 10] 7 centers = [[0.0, 0.0], [2.0, 2.0], [4.0, 4.0], [6.0, 6.0]] 8 cluster_std = [0.4, 0.4, 0.4, 0.4] 9 10 x, y = make_blobs(n_samples=n_samples, centers=centers, cluster_std=cluster_std, random_state=0, shuffle=False) 11 12 plt.scatter(x[:, 0], x[:, 1], c=y, cmap=plt.cm.rainbow, edgecolors=‘k‘) 13 14 plt.show()
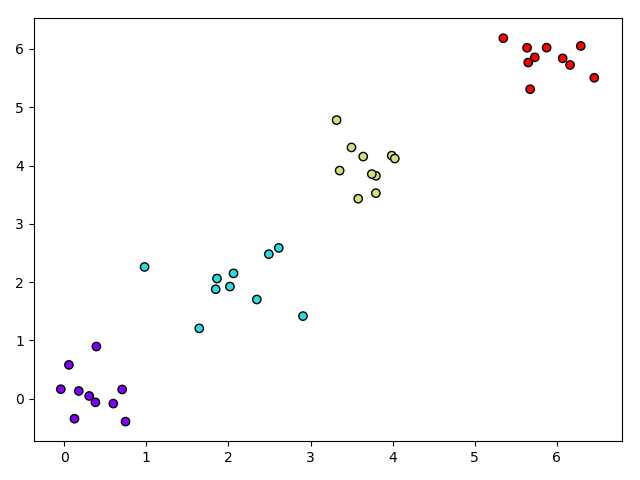
图1 聚类方法生成四组不同的数据
为了更加能够简化多分类的示例,此处直接使用线性核函数的方法,对于sklearn中C-SVC算法中多分类方法,网上给出的多分类示例包含有一对一(ovo)、一对多(ovr)、有向无环图等方法,但是此处需要说明的是,sklearn中的SVM算法底层的实现采用了台湾大学林智仁教授等发表的LibSVM运行库,而LibSVM中采用的多分类方法为一对一(ovo)的多分类方法(之前笔者误以为sklearn中能够支持不同的多分类方法,对于后面提到的提取训练参数并自行完成前向推理过程产生了误解,导致好几天没能理解参数函数)。因此,由于sklearn中C-SVC算法只能够支持一对一的多分类方法,只需要按照一对一的理论方法来理解给出的参数即可。
接下来给出笔者进行二维平面内多分类的示例,示例程序如下:
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn import svm 4 from sklearn.datasets import make_blobs 5 6 n_samples = [10, 10, 10, 10] 7 centers = [[0.0, 0.0], [2.0, 2.0], [4.0, 4.0], [6.0, 6.0]] 8 cluster_std = [0.4, 0.4, 0.4, 0.4] 9 10 x, y = make_blobs(n_samples=n_samples, centers=centers, cluster_std=cluster_std, random_state=0, shuffle=False) 11 12 clf = svm.SVC(kernel=‘linear‘, C=10, gamma=0.5, decision_function_shape=‘ovo‘) 13 clf.fit(x, y) 14 15 xx = np.linspace(-1, 7, 400) 16 yy = np.linspace(-1, 7, 400) 17 XX, YY = np.meshgrid(xx, yy) 18 XY = np.vstack([XX.ravel(), YY.ravel()]).T 19 Z = clf.predict(XY).reshape(XX.shape) 20 plt.pcolormesh(XX, YY, Z, cmap=plt.cm.rainbow) 21 22 plt.scatter(x[:, 0], x[:, 1], c=y, cmap=plt.cm.rainbow, edgecolors=‘k‘) 23 plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=100, facecolors=‘none‘, edgecolors=‘k‘) 24 25 print(‘clf.support_vectors_‘) 26 print(clf.support_vectors_) 27 28 print(‘clf.n_support_‘) 29 print(clf.n_support_) 30 31 print(‘clf.support_‘) 32 print(clf.support_) 33 34 print(‘clf.dual_coef_‘) 35 print(clf.dual_coef_) 36 37 print(‘clf.coef_‘) 38 #print(clf.coef_) 39 40 print(‘clf.intercept_‘) 41 print(clf.intercept_) 42 43 print(clf.decision_function([[1, 1]])) 44 print(clf.predict([[1, 1]])) 45 46 plt.show()
最终对图1中的样本点分类结果如图2所示,其中边缘多一个圈的样本点为对应的支持向量样本点。从图2中结果可以看出,线性核函数的多分类结果能够区分出对应的边界,符合预期的分类。
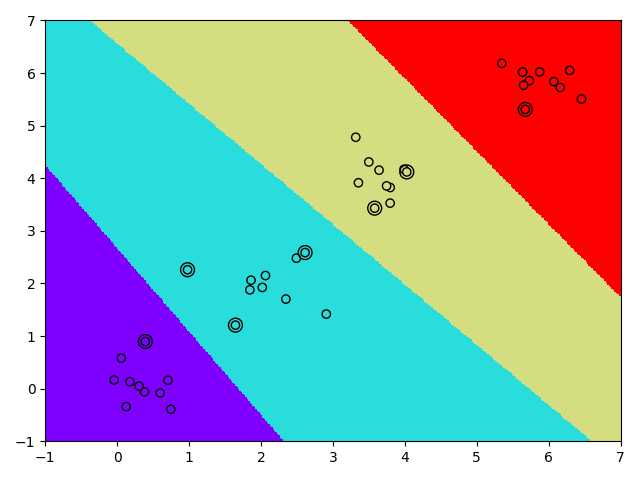
图2 线性多分类结果
3、sklearn多分类参数说明及应用
首先是对C-SVC前向推理的决策函数f(x)进行说明,如公式(1):
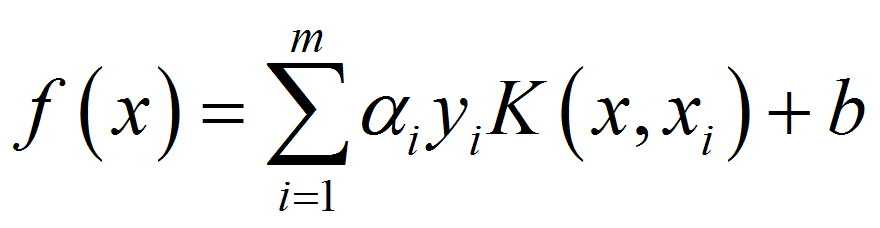 (1)
(1)
其中K(xi,x)为核函数;αiyi为核函数对应的系数,也是前向推理过程中最重要的参数,sklearn中对于核函数系数的存储方式不是特别好理解,也是本文所侧重说明的一个点;m为支持向量样本的个数,简单的理解,SVM顾名思义支持向量机,其中决策函数(也就是分割超平面)由支持向量来决定;b为决策函数对应的偏置项,属于支持向量累加完成后需要添加的偏置。
对于多分类(>=3)中一对一的分类方法,简述为每次选择样本空间中的任意两类构造分类模型,例如4个类别[0,1,2,3],分别对[0,1][0,2][0,3][1,2][1,3][2,3]构建6个分类模型。因此根据排列组合可知,若类别的数目为n,则需要构建的分类模型可用公式(2)来表示:
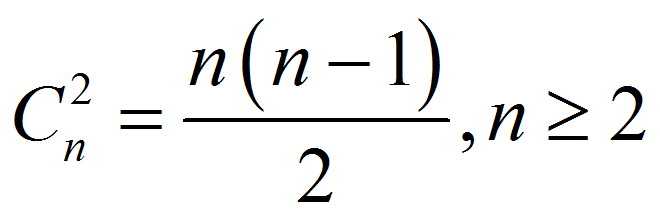 (2)
(2)
当n=2时为二分类问题,只需要构造一个分类模型,不属于多分类需要讨论的范畴。因此对于给定的类别n,需要构建决策函数的数目也由公式(2)来决定。
当多分类对应的多个决策函数确定后,输入新的测试样本,例如坐标(x,y),大小为(0,0);经过决策函数进行投票,例如4分类中[0,1][0,2][0,3][1,2][1,3][2,3],在对应的决策函数中,每一个决策函数的结果均小于0,则每个决策函数投票结果为[0,0,0,1,1,2],那么最终结果判断输入坐标(0,0)属于类别0,此处不排除投票出现相同的投票结果。
-------------------------
接下来就是重点了
-------------------------
假定输入样本的特征大小为n_features(例如二维平面输入为坐标,则特征为2),样本的类别为n,样本的数目为n_samples,训练后得到的支持向量个数为n_Svs。
在sklearn中需要注意的训练结果如下:
clf.support_vectors_
支持向量的表述,对应公式(1)核函数K(xi,x)中的xi,在实际的前向推理中,每个核函数只需要计算一次,而计算结果需要参与到多个模型分类中,该矩阵的维度为(n_SVs, n_features)。
|
0.391495 |
0.896357 |
|
0.978804 |
2.261447 |
|
2.613112 |
2.587744 |
|
1.644886 |
1.207681 |
|
3.580579 |
3.431993 |
|
4.026607 |
4.120989 |
|
5.674741 |
5.309487 |
clf.n_support_
每个类别所对应支持向量的个数,矩阵的维度为(1, n),若每一个类别对应的支持向量个数为n_SVi,每个类别支持向量个数的和为总支持向量的个数, 即公式(3):
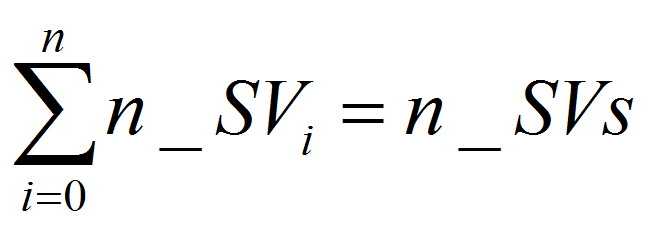 (3)
(3)
|
1 |
3 |
2 |
1 |
clf.support_
支持向量clf.support_vectors_对应在n_samples里面的索引,在前向推理过程中不需要是用到此参数,矩阵的维度为(1,n_SVs)。
|
1 |
10 |
14 |
16 |
20 |
28 |
31 |
clf.dual_coef_
每一组支持向量求得的核函数所对应的系数αiyi,矩阵的维度为(n-1, n_SVs),后文将对此进行详细的介绍。
|
1.331435 |
-0.43355 |
0 |
-0.89788 |
-0.12048 |
0 |
-0.0422 |
|
0.120484 |
0 |
1.213041 |
0 |
-1.21304 |
0 |
-0.11918 |
|
0.042204 |
0 |
0.119179 |
0 |
0 |
0.484178 |
-0.48418 |
clf.coef_
线性核函数合并同类项后的系数,只有当线性核的时候才能够调用此参数,非线性核函数不能够合并同类项,因此不存在此参数。矩阵的维度为(n*(n-1)/2, n_features)
|
-1.38003 |
-0.87137 |
|
-0.38423 |
-0.3055 |
|
-0.22298 |
-0.18625 |
|
-1.17358 |
-1.02411 |
|
-0.36488 |
-0.32437 |
|
-0.79799 |
-0.57544 |
clf.intercept_
每个决策函数对应的偏置,对应公式(1)中的b,矩阵的维度为(1, n*(n-1)/2)。
|
2.321663 |
1.424266 |
1.254244 |
6.716821 |
2.792877 |
6.584147 |
下面以图2中四分类来举例说明这些参数是如何使用的,此处参考了https://blog.csdn.net/baidu_33939056/article/details/71136197的相关说明和https://stackoverflow.com/questions/20113206/scikit-learn-svc-decision-function-and-predict中的解释,另外也参考有sklearn官方给出的说明文档:https://scikit-learn.org/stable/modules/svm.html。
当输入一个样本,样本的矩阵维度为(1,n_features)时,以线性核函数为例,如果输入的是(x0,x1),则生成的核函数矩阵为图3,矩阵的维度为(n_SVs, 1):

图3 核矩阵示意图
而上述核函数矩阵根据类别分为4类,每个类别对应的数量与clf.n_support_对应,分块后矩阵的维度为(n,1),如图4所示:

图4 核矩阵分块示意图
而对于核函数系数矩阵clf.dual_coef_,同样可以按照上述分类方式进行分块,分块后矩阵的维度为(n-1,n),如图5所示:

图5 系数矩阵分块示意图
根据图4和图5所示分块方式进行多分类,所以重点其实是公式(1)中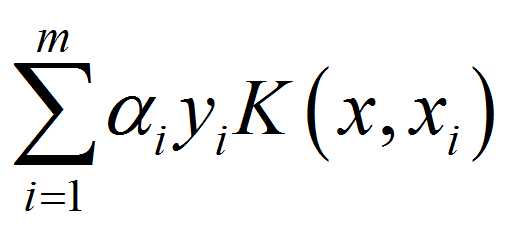 的计算过程。根据公式(2)可知,如果是四分类问题,采用一对一的分类方法需要计算6个决策函数,对于如何使用系数矩阵与核函数矩阵进行相乘,从而构造6个决策函数,笔者所查阅的资料没有给出一个形象的过程解释,因此本文再次给出详细的解释。在系数矩阵中,默认的决策函数按照[0,1][0,2][0,3][1,2][1,3][2,3]的决策方法,第一步首先提取系数矩阵中(0,0)和(0,1)中的数据,完成矩阵的点乘操作,得到累加后结果,即第一个决策函数计算完成;然后提取系数矩阵中(0,1)和(0,3)中的数据,对应第二个决策函数;说了这么多,我觉得还是用图片来便是更形象一点。看图6中的说明,展示了怎样构建一对一条件下的决策函数。
的计算过程。根据公式(2)可知,如果是四分类问题,采用一对一的分类方法需要计算6个决策函数,对于如何使用系数矩阵与核函数矩阵进行相乘,从而构造6个决策函数,笔者所查阅的资料没有给出一个形象的过程解释,因此本文再次给出详细的解释。在系数矩阵中,默认的决策函数按照[0,1][0,2][0,3][1,2][1,3][2,3]的决策方法,第一步首先提取系数矩阵中(0,0)和(0,1)中的数据,完成矩阵的点乘操作,得到累加后结果,即第一个决策函数计算完成;然后提取系数矩阵中(0,1)和(0,3)中的数据,对应第二个决策函数;说了这么多,我觉得还是用图片来便是更形象一点。看图6中的说明,展示了怎样构建一对一条件下的决策函数。
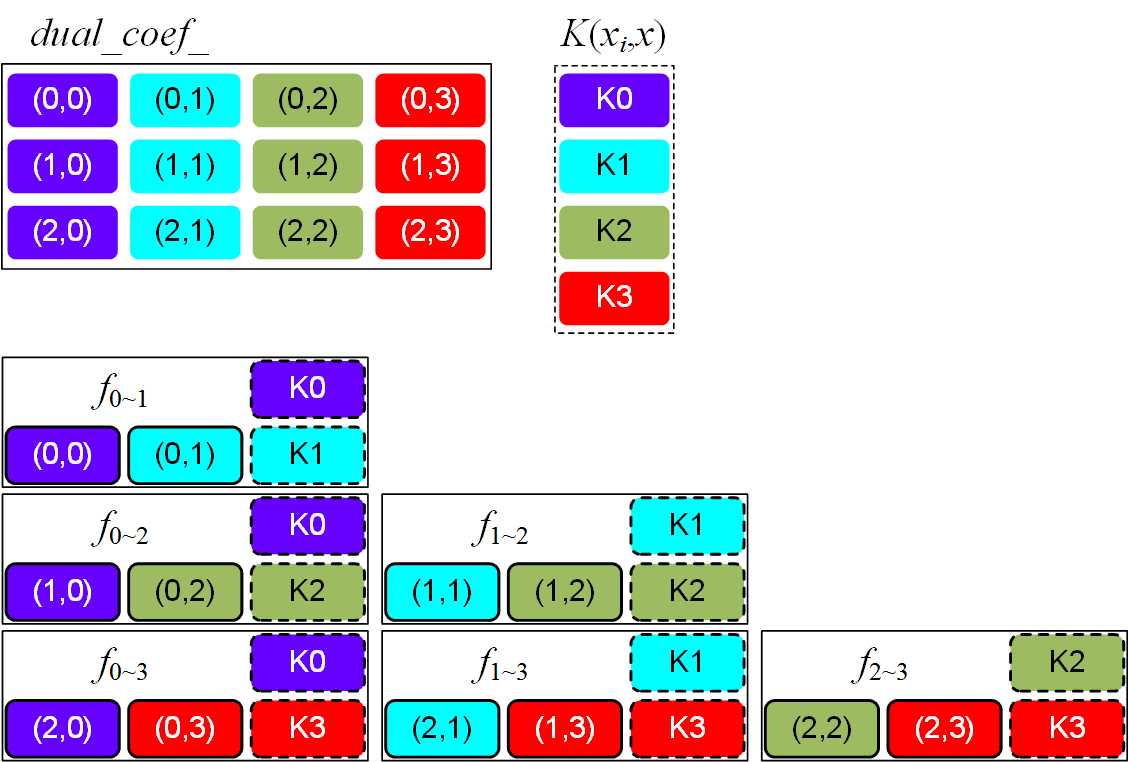
图6 一对一决策函数计算示意图
同样可以直接计算矩阵,然后按照图6中构造决策函数的方法将矩阵中元素选择求和,如图7所示:
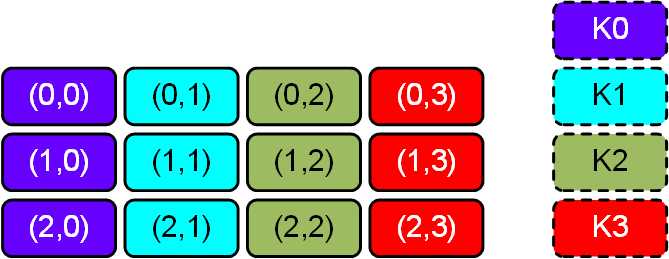
图7 直接矩阵运算示意图
构造决策函数的过程可以用图8中的伪代码来表明:
1 f_i=0; 2 for(i=0;i<n;i++) 3 { 4 si=i; 5 for(j=i+1;j<n-1;j++) 6 { 7 f[f_i]=dual_coef_[si][i]*k[i][j]; 8 f_i++; 9 si++; 10 } 11 }
图8 决策函数构建伪代码
最后得到的决策函数个数刚好与公式(2)的大小一致,接下来只需要与每一个决策函数的偏置相加,通过判断结果与0的关系,得到该决策函数的投票结果,最后统计投票结果,即可得到多分类结果。
4、一对一多分类程序
此程序参考了https://stackoverflow.com/questions/20113206/scikit-learn-svc-decision-function-and-predict的设计方法。
1 import numpy as np 2 3 sv = [[0.39149519, 0.89635728], 4 [0.97880407, 2.26144744], 5 [2.61311169, 2.58774351], 6 [1.6448857, 1.20768141], 7 [3.58057881, 3.43199283], 8 [4.02660689, 4.12098876], 9 [5.67474149, 5.30948696]] 10 nv = [1, 3, 2, 1] 11 a = [[1.33143525, -0.43355065, -0., -0.89788459, -0.12048409, -0., -0.04220442], 12 [0.12048409, 0., 1.21304109, 0., -1.21304109, -0., -0.11917911], 13 [0.04220442, 0., 0.11917911, 0., 0., 0.48417772, -0.48417772]] 14 b = [2.32166302, 1.42426621, 1.25424389, 6.71682103, 2.79287738, 6.58414668] 15 cs = [0, 1, 2, 3] 16 17 X = [5, 6] 18 19 k = [np.dot(vi, X) for vi in sv] 20 21 print(‘k‘) 22 print(k) 23 24 start = [sum(nv[:i]) for i in range(len(nv))] # nv=[1,3,2,1] start=[0,1,4,6] 25 end = [start[i] + nv[i] for i in range(len(nv))] # end = [1,4,6,7] 26 27 ‘‘‘ 28 c = [sum(a[i][q] * k[q] for q in range(start[j], end[j])) + 29 sum(a[j - 1][p] * k[p] for p in range(start[i], end[i])) 30 for i in range(len(nv)) for j in range(i + 1, len(nv))] 31 print(‘c‘) 32 print(c) 33 ‘‘‘ 34 35 c = np.zeros(int(4*(4-1)/2)) 36 ci = 0 37 for i in range(len(nv)): 38 for j in range(i + 1, len(nv)): 39 sum1 = 0 40 sum2 = 0 41 for q in range(start[j], end[j]): 42 sum1 = sum1 + a[i][q] * k[q] 43 for p in range(start[i], end[i]): 44 sum2 = sum2 + a[j - 1][p] * k[p] 45 print(‘i:‘ + str(i) + ‘;j:‘ + str(j)) 46 print(sum1 + sum2) 47 c[ci] = sum1+sum2 48 ci = ci+1 49 50 51 decision = [sum(x) for x in zip(c, b)] 52 print(‘decision‘) 53 print(decision) 54 55 56 votes = [(i if decision[p] > 0 else j) for p, (i, j) in enumerate((i, j) 57 for i in range(4) 58 for j in range(i + 1, 4))] 59 60 print(‘votes‘) 61 print(votes) 62 63 print(cs[max(set(votes), key=votes.count)])
对异构计算和机器学习算法加速的可以关注我发表的文献,不定期更新:
以上是关于sklearn中SVM一对一多分类参数的研究的主要内容,如果未能解决你的问题,请参考以下文章
机器学习SVM多分类问题及基于sklearn的Python代码实现
参数“coef0”是不是表示 sklearn.svm.SVC 方法中的特定系数?